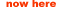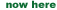|
��紤����������ǡѺ�٪�鹡�ҧ
������ҡ�ٴ��� � ����ǡѺ�٪�鹡�ҧ ��ҡ�д١ 3 ��鹡Ѻ��ͧ��ҧ � ���仴����ҡ�� ��д١��� � 3 ���������¡����ѹ��� ossicles ���Ӫ�������������ҡ�д١�� ��� �Ź ������Ҷ١��ѹ������ѹ���ٻ��ҧ������ ��� �Ź ���͡�д١����ҹ��������ѧ��ɤ�� malleus incus stapes �ѹ�������Ҿ�����ҵ�����ѡ��� �������ѧ䧡���������� ��觡Ѻ�Ź������������������ �����Ҥ�����Ź�����������駡����
�٪�鹡�ҧ������鹷�� eardrum ����ִ�Դ�Ѻ��д١�����鹹�� eardrum ���ҧ�ҡ circular �Ѻ radial fibers ����ա����������� ����ҹ� (tensor tympani muscle) ��·�����ѹ�֧ ˹�ҷ��ͧ eardrum ��� ����¹��üѹ�ǹ�ͧ�����ѹ�ͧ�������§����繡������ԧ�������觵����ѧ�٪��㹼�ҹ ossicles
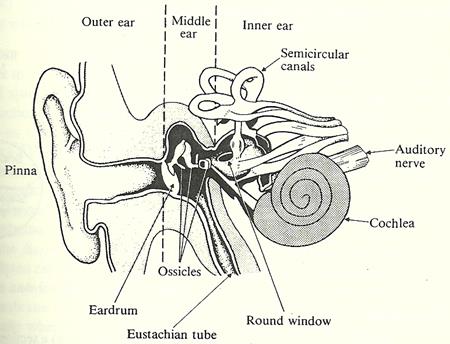
˹�ҷ��ͧ ossicles �����仡����¡Ѻ˹�ҷ��ͧ�ҹ �ѹ�ŧ�����ѹ���� � �ͧ�������§����ҡ��� eardrum �������繤����ѹ����ҡ�������ҧ�ҡ (����ҳ 30 ���) ��˹�ҵ�ҧǧ�բͧ�٪��� ���ǡ��Ҩ���¡��觷���˹�ҷ��ѧ���������繵���ŧ�ԧ�� (mechanical transformer) �ѧ�ٻ��ҹ��ҧ ������ç���ҧ�ͧ�ҹ ossicles �Ҩ���������ç����ա��ҹ˹�觻���ҳ 1.5 ��� (F2 = 1.5F1 ���� ��ѡ��âͧ�ҹ��� �ç���� � ���з���ҧ � �������Ѿ����ҡѺ�ç�ҡ � ��з���� �) ��з���Ǥٳ�ա 20 �����ԧ�����ѹ�Ҩҡ��鹷����ᵡ��ҧ�ѹ�ҡ�����ҧ eardrum �Ѻ ˹�ҵ�ҧǧ�� (���� P = F/A) P2 = (1.5)(20)P1 = 30P1
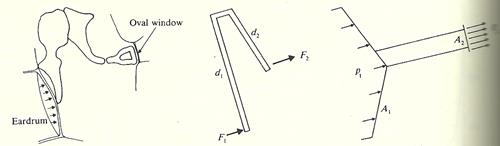
˹�ҷ���ա��С�âͧ��д١��� � ����ҹ�� ��� ����ͧ�٪��㹨ҡ���§ú�ǹ���ѧ�ҡ��С������¹�ŧ�����ѹẺ�Ѻ��ѹ ���§ú�ǹ���ѧ�з������������ 2 �ش�ӧҹ �ش�á�з���� eardrum �֧��� �蹢�� �ա�ش�д֧��д١�Ź����͡�ҡ˹�ҵ�ҧǧ�բͧ�٪��� ��õͺʹͧ������§�ѧ������¡��� acoustic reflex
�չ�� ���ͧ�ҡ eardrum �ѹ�ӵ��������֡�ҡ�������ҧ�٪�鹡�ҧ�Ѻ�ҡ����¹͡ �й�� ���繵�ͧ���Ըշ��л�Ѻ�����ѹ�����ҧ�٪�鹡�ҧ�Ѻ��鹹͡�����ҡѹ (�ͧ�ͺ�Ӷ����� ����? �ͧ��) �����ҵԨ֧���ҧ���������¹ (���ٻ��� 2) �������������ҧ�٪�鹡�ҧ�Ѻ��ѧ�ç��١�����ͧҹ��� ����ͤ����ѹ��¹͡����¹ �� ������������������¹�дѺ�����٧�Ǵ�����ѡ˹��� �ҡ���������¹�Դ��� ��ҡ��Ҩ���Թ���§��ͻ��� ����������
������������Ƕ֧��÷ӧҹ�ͧ�٪�鹡�ҧ �Ϳ��Ȣͧ�ѹ�բ�Ҵ����ҳ�����ӵ���ͧ��Ѻ
(�����˵� ���������º���§�ҡ�ҧ��ǹ�ͧ 5.2 Structure of the Ear, The Science of Sound 3rd Ed, �� Rossing, Moore, �Ѻ Wheeler)
| Create Date : 29 ����¹ 2556 | | |
| Last Update : 1 ����Ҥ� 2556 23:54:12 �. |
| Counter : 4914 Pageviews. |
| |
|
 |
|
|
|
Production, Propagation, and Processing of Sound (��ػ)
�����ҵ������§�ӴѺ�����ػ���Ǣ�� 3.5 Summary ��Т��¤���������������Ǣ�͡�˹�Ҩҡ����� 3 Production, Propagation, and Processing ˹ѧ��� The Sense of HEARING �ͧ Christopher J. Plack ��������������� �� The Nature of Sound (��ػ)
1. ���觡��Դ���§ ��� �ѵ�������˵ء�ó������ҧ�����ѹ�ǹ�ͧ�����ѹ �ѵ�بӹǹ�ҡ�դ���������ṹ���������ҵ� �������Ͷ١���ᷡ (���� �١�� �١�մ �١���) �������Դ�������§����������� �����Ф����秽״ (stiffness) �ͧ���� �繵�ǡ�˹��������ͧ������ ���觡��Դ���§�ҧ���ҧ������ҡ��������§�ѧ�����ѧ�ҡ�١��� �����觡��Դ���§�ҧ���ҧ����������� ���§�ֺ
���֡��� ��üѹ�ǹ�ͧ�����ѹ���������� � ���Դ������ͧ ��ͧ�����觾�ѧ�ҹ �� �����л�е� ��ѧ�ҹ�ҡ��ûзй�鹨�����¹��繤�����������ǹ�˭� �����ǹ˹�觷�����Դ���§
�ѵ���ͺ���㹪��Ե��Ш��ѹ���դ����������ҵԢͧ������ ���¡��� ����������ṹ�� �Ӷ�� ���÷�����Դ������ �ӵͺ �������ë���դ����״���������ٻ (�� �������Ǵմ���˹�觷� ��������÷���դ����״���� ��еç�ش�����ǡ�з��Ѻ���Ƿ����Ҵմ�ա�������ٻ) �ҧ��ǹ�ͧ���ö١�״�͡���ͺҧ��ǹ�١�պ�Ѵ �ѧ��鹨֧�Դ�ç���з�������ôѧ����ǡ�Ѻ�����ٻ��� (�Ҩ�֡�֧ʻ�ԧ����������¹�� ���դ����ⴴ�ҡ���� ���촨д֧����ѹ�ͧ��Ѻ���ٻ��� ���˹����) �����ѹ������������Ѻ���ٻ��� �ѹ overshoot ������Դ��������ٻ�㹷�ȷҧ�ç�ѹ�����Ѻ��á �֧������Դ������ (�֡�֧ʻ�ԧ����������¹�ӷ����蹢��ŧ�ѡ�ѡ������ش���) �����Ҩ���ش��觷���ٻ��� ���˹���� �������ͧ�����蹴ѧ����ǹ�����Ф�Ѻ �١��˹��������Ф����秷��ͧ͢���� ���Ţͧ������ ���������ִ�Դ�Ѻʻ�ԧ �ѧ�ٻ��ҹ��ҧ �ѵ�ҡ������ü��ѹ�Ѻ����ҡ����ͧ�ͧ��� ����üѹ�������ҡ����ͧ�ͧ�����秷��ͧ͢ʻ�ԧ ��蹤�� ������Ŵŧ 4 ��� �������ͧ�����蹨�������� 2 ���
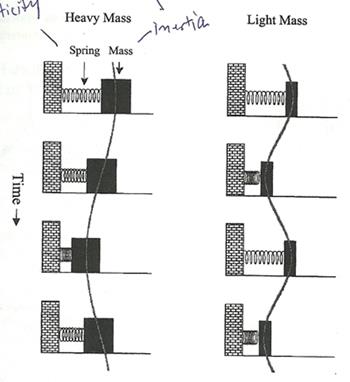
�����蹴ѧ���������Ҩ�������ش ����ǹ���ѺẺ���� � �ç��ҹ��Ǩ�������§�ѧ�����ѡ�ѡ��ѧ�ҡ���١��� ��ǹ����ǹ���Ѻ�ͺ����� � ��������§�ֺ � ��� � ����ᵡ��ҧ����繼Ũҡ damping ��ҡ���������Ẻ������Ҿ�ç���´�ҹ����ҧ���� �ѹ����蹵����ѡ���С����٭���¾�ѧ�ҹ��ٻ��������������� ���ҡ��õ�ҹ�ҹ�����������դ���ҡ �ѹ����蹤���������о�ѧ�ҹ�������С����繤���������ҧ�Ǵ���� �ٻ��ҹ��ҧ�ʴ����§�óըѺ��ҹ����ǹ� �Ѻ����ǨѺ�ͺ����ǹ� (highly damped)
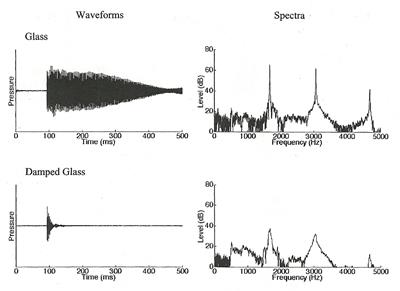
2. ���ѵ����ṹ��ͧ�ѵ���Ҩ����ҧ�Ѻ�� ���ѵԴѧ����������§�к͡�֧���§�ѡɳ��� (characteristic sound) �ͧ�ѵ�ص���١��� ���ѧ�觺͡�֧�ٻẺ����ѵ�ع�鹵ͺʹͧ��ͤ�������е�鹷��ᵡ��ҧ�ѹ �ѵ�ب�����ҡ �ع�ç 㹡óշ��ͺʹͧ��͡�á�е�鹷�����������ṹ��ͧ�ѹ

�͡�ҡ�еͺʹͧ��͡�ö١��е�� (�� ���) �µç���� �ѵ���ѧ�ͺʹͧ��͡����蹢ͧ���÷���ѹ������ (�� �ҡ��) ���� ����ѵ�ع�����Ѻ��á�е�鹨ҡ���觡��Դ�����蹴��¤���������ṹ��ͧ�ѹ�ͧ �ѹ������ع�ç �� �ع�ç��Ҵ����������ᵡ��㹡óբͧ�ѡ��ͧ������ �ҡ�ǡ�����ҧ���§��������٧������������ṹ��ͧ��� ���º��º��Ѻ�����觪ԧ��� �����Ҽ�ѡ���¤���������ǡѺ���������ԧ��ҡ��ѧ��� �ԧ��ҡ���������٧���� � ���Ͷ����Ҷ��ʻ�ԧ�١�Դ��Ŵ�����͢�ҧ˹�� ����·��ŧ���Ǵ�� �����¡��͢��ŧ ��ŷ��Դʻ�ԧ�����蹢��ŧ ��ж�Ҥ������㹡���¡��͢��ŧ�ͧ�����ҡѺ����������ṹ��ͧ�к���ŵԴʻ�ԧ �ѹ�������ҡ ��������¡��͢��ŧ���ǡ������ͪ�ҡ��Ҥ���������ṹ��ͧ�к� ��š����蹹���ŧ �·���� �ѵ�ط�� damped (�� ����ǹ�Ѻ�ͺ�� �) �ж١�ٹ���ç�Ѻ�ٻẺ����������ṹ���ҡ���� (�ѡ��ͧ�����ҷ������Ƿ��١�Ѻ�ͺᵡ�ҡ������Ƿ��١�Ѻ��ҹ)
3. �͡�ҡ��� ���ṹ���ѧ����ö�Դ���㹻���ҵûԴ�ͧ�ҡ�� �ѹ���ͧ�ҡ����з����㹷����ҧ��� ��á�е�鹷�����������ṹ��з�����Դ���蹹�� (standing wave) ������Դ���˹觷���ա������¹�ŧ�����ѹ����ش (node) ��е��˹觷���ա������¹�ŧ�����ѹ�٧�ش (antinode)
����������§�١���ҧ���㹻���ҵûԴ ��㹷�ͻԴ����ͧ��ҧ ����dz����ҡ��˹�������Һҧ㹷�ͨ��з���Ѻ仡�Ѻ�� 㹡óբͧ���� ���������Űҹ�ͧ�����������Ѻ仡�Ѻ�Ҷ١��˹��¤�����Ǣͧ��� �������ҷ��������¹�ŧ�����ѹ��㹡���������ҡ���¢�ҧ˹����ѧ�ա��ҧ˹�� (�����ѵ���������§) �������Ѻ������Ƿ�� ��Ҥ�����Ǥ������§��鹾ʹշ����������§����з����ʵç�Ѻ�������§����з� (in phase) �������§����ͧ������ѹ���ҧ��õͺʹͧ����ҡ��� ����Ѻ��ͻԴ �˵ء�ó�ѧ������Դ����ͤ�����Ǥ��蹢ͧ���§�դ�����ͧ��Ңͧ������Ƿ�� ���һ��´�ҹ˹�觢ͧ����Դ (�� �Ǵ) ���§���件֧�����Դ���͡Ѻ��á�Ѻ�� (phase reversal) �ٴ�ա���ҧ˹����� ����˹��蹨��з���Ѻ���繤����Һҧ �ѧ��� ����Ѻ��ͻ����Դ˹�觢�ҧ ������Ǥ�����Űҹ���������Ңͧ������Ƿ��
�������ѹ�ͧ�������§������������ṹ�����������㹷�ȷҧ�ç�ѹ��������;ǡ�ѹ�з������ҧ�ͺ����ͧ��ҧ�з�����Դ���蹹�觴ѧ�ٻ
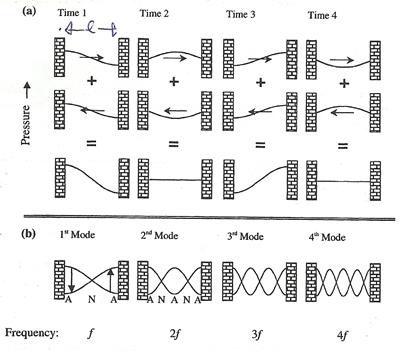
����dz�����ҧ�ͺ����ͧ���յ��˹觷������ѹ�������¹�ŧ ���¡��� node ��ǹ���˹觷��������¹�ŧ�ͧ�����ѹ�դ���ҡ����ش ���¡��� antinode �͡�ҡ�����������Űҹ���� �ҡ��㹷���ѧ��� (�Դ���§�ѧ��ͧ) ���������������ѹ��Ẻ�����ԡ��Ѻ���������Űҹ ��蹤�� 㹡óշ�ͻԴ����ͧ��ҧ ���蹹���ѧ���Դ��鹵�Һ��ҷ�������Ǣͧ����ѧ�繨ӹǹ�����Ңͧ���觢ͧ������Ǥ������§ (���ٻ b ��ҧ��) ����Ѻ�óշ���Դ˹�觢�ҧ ��á�Ѻ�ʷ������Դ�з�����Դ�������ԡ���Ţ��� �ѧ�ٻ
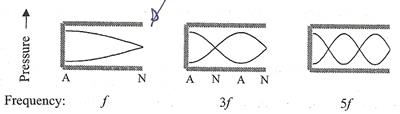
4. �к����Դ���§�ͧ��������§����ͧ����ջ�Сͺ�������觡��Դ�����ѧ��蹫�觨����ҧⷹ���� � ⷹ���Ѻ�� ������ͧⷹ�١�Ѵ�ŧ���ç���ҧ���ṹ��㹷ҧ�Թ���§�����ç���ҧ�ͧ����ͧ����յ���ӴѺ
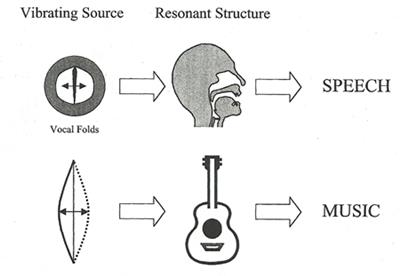
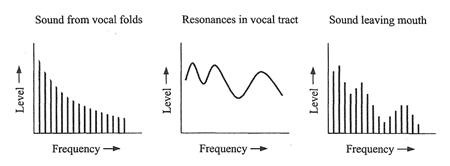
������ҧ���§�ٴ���¡�úպ�ҡ��㹻ʹ����ҹ������§ (vocal folds) ������ѹ��� �ҡ������§�ж١�Ѵ�ŧ�����ѹ�Թ�ҧ��ҹ�����Ӥ���лҡ ��ͷҧ�Թ���§ (vocal tract) ����ӵ�����º��Ѻ��ͻ����Դ˹�觴�ҹ�ѧ��������Ƕ֧����� �����Դ�óչ�����������ҧ����ջҡ
5. �������§�Թ�ҧ����Ш����ҡ�ȷ������Ե� �¤���������§�ü��ѹ�Ѻ������ҧ�ҡ���觡��Դ���§¡���ѧ�ͧ (inverse square law) ���¤������ �дѺ���§Ŵŧ 6 dB ����Ѻ�ء � ������ҧ�����������ͧ��Ҩҡ���觡��Դ���§ (���� -10 log10 4 ≈ -6)
6. (6.1) ����ͤ������§�Թ�ҧ���͡Ѻ�ѵ�� �ѹ�Ҩ�з���Ѻ�ҡ�ѵ�� �Ҩ�觼�ҹ�ҧ�ѵ�� (�Թ�ҧ����ѵ��) �Ҩ������ູ�ͺ�ѵ�� ���Ͷ١�ٴ�����ѵ��, (6.2) ��������ᴹ�� (impedance) �ͧ�ѵ����Тͧ�ҡ�������ҡѹ�ҡ����� ��ѧ�ҹ���§���з���Ѻ�ҡ��ҹ��, (6.3) ������ͧ����з����Ѻ��㹾�鹷��Դ���¡��� reverberation, (6.4) ͧ���Сͺ��������Ө�������ູ�ͺ�ѵ���ҡ���� ����ѡ�ж١�ٴ�����ѵ���ҡ����
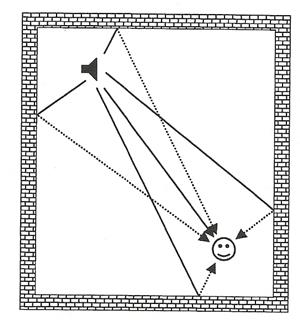
���§���з�����͵�ǡ�ҧ�ӾҤ������§�������ᴹ��ᵡ��ҧ�ҡ��ǡ�ҧ����ѹ༪ԭ˹�� �����ᴹ������觷��͡�����ҵ�ǡ�ҧ��� � ��͵�ҹ����Թ�ҧ�ͧ�������§�ҡ�������˹ ���÷���秷������˹��蹨��������ᴹ���٧ ��觤���ᵡ��ҧ�����ҧ�����ᴹ��ͧ�ͧ��ǡ�ҧ�դ���ҡ ��ѧ�ҹ���§�������з���Ѻ�ҡ �� ���§�Թ�ҧ��ҡ�� (��ǡ�ҧ����������ᴹ����) 仡�з���ᾧ (��ǡ�ҧ����������ᴹ���٧) ��ѧ�ҹ��ǹ�˭�ͧ�������§���з���Ѻ �ѧ�ٻ (�������§����з��͡�ҡ��ѧ ����Ҩ�ͧ���˹������ѹ�Թ�ҧ�ҡ sound image ��������ҹ��ѧ��ѧ���������ҧ���ǡѺ���觡��Դ���§)
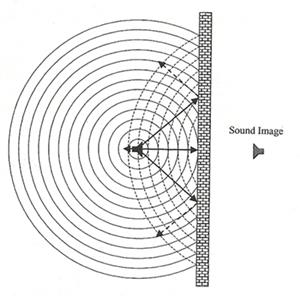
�ٻ��ҹ��ҧ�ʴ�������ҧ������������§����з�㹾�鹷��Դ ������ԧ�Ѻ��������ٻ ���� �͡�ҡ����������鹷ҧ�ҡ���觡��Դ�Ҷ֧������ ���§���������Թ���Ҩ�Ҩҡ����з�����ҡ���ҡ���з������á ������ͧ���§�з����Ѻ��������¡��� reverberation
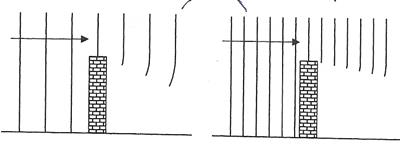
��ѧ�ҹ�ҧ��ǹ�������з��Ҩ�觼�ҹ�ѵ�� ���蹵���з�������ѵ���������÷����������� ���ҧ�á��� ��ѧ�ҹ��ǹ�˭�������з��Ҩ�١�ٴ�����ѵ�� ��ѧ�ҹ��������¹��繤��������ͧ�ҡ�ç���´�ҹ�ͧ���� (damping)
���������ູ�Դ�������͡������¹�ŧ�����ѹ㹤������§����ҹ�ͺ�ͧ�ѵ���ջ������ѹ��Ѻ�ҡ�ȷ�������ҹ��ѧ�ѵ�� ���������ູ���ҡ�����¢������Ѻ������� �ѧ�ٻ ���������������ູ�ҡ���Ҥ�������٧
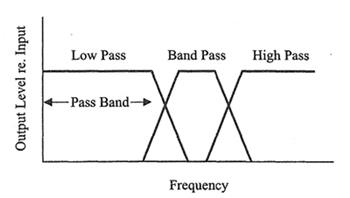
7. ������� (filter) ��͵�ǴѴ�ŧ������ͧ���§�����ѭ�ҳ, low-pass filter ������ͧ���Сͺ��������Ӽ�ҹ���Ŵ�ͧ���Сͺ��������٧����բ�Ҵ���ŧ, high-pass filter �������������٧��ҹ���Ŵ����������, band-pass filter ��������ҹ�������㹪�ǧ� � ��ҹ���Ŵ�����������٧���͵�ӡ�����ҹ���
�ٻ��ҹ��ҧ�ʴ��ٻ�������������ͧ complex tone (�ٻ��) ����ٻ��������������ѧ�ҡ����ѹ��ҹ band-pass filter �ͧ��Ƿ���դ�������ҧ��ҧ�ѹ�� bandwidth ��ҡѹ
vocal tract �Ѻ����ͧ��������к����ṹ��ҧ����Ҿ���ӵ�������������
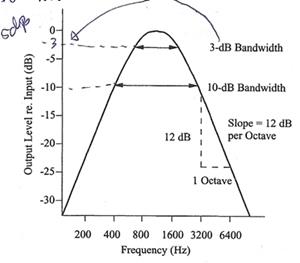
�ٻ�����ʴ� characteristics �ͧ band-pass filter ����դ�������ҧ��ҡѺ 1 kHz ������������ logarithm ��ǹ������дѺ���§ dB �ͧ output �ҡ���������º�Ѻ�дѺ���§ input �� �����һ� pure tone ������� 200 Hz ��ҿ�������ǹ�� �дѺ���§ output ��Ŵŧ����ҳ 24 dB ��º�Ѻ input ������ͧ�ҡ������������տ�������������ö�ӨѴ�������͡ bandwidth ����������ҧ����ԧ (������Ŵ�����դ���������ͤ����ѹŴŧ) ��ú͡ bandwidth �ͧ�������֧������˹������дѺ�ͧ output ���Ŵ�ŧ �� 3-dB bandwidth ���� 10-dB bandwidth �ҧ���Ҩ�͡���¤�� Q �����ҡѺ�ѵ����ǹ�����ҧ��������ҧ��� bandwidth �� ��Ҥ�������ҧ��ҡѺ 1 kHz ��� 10-dB bandwidth = 400 Hz ��Ҩ��� Q10 = 2.5
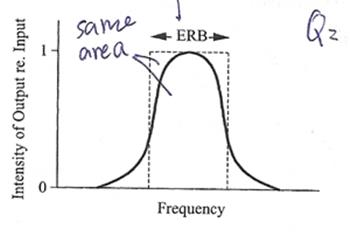
����ǡѺ��������դ���ա��ҷ��������� ERB (equivalent rectangular bandwidth) �� ERB ��� bandwidth �ͧ��������������ҡ����٧��ҡѺ���Ŵ�����ӷ���ش (����������駤�ͤ�������ͧ output ��º�Ѻ������� input ���Ŵ�����ش������� 1) ����վ�鹷����ҡѺ��鹷�����ҿ characteristics �ͧ������� �ѧ�ٻ
8. ��ôѴ�ŧ������ͧ���§ �з���� waveform ��������Ңͧ���§����¹仴��� ��п���������е�Ǩ��ռŵͺʹͧ�����ū� (impulse response) �������ѹ��Ѻ�ѹ (�ŵͺʹͧ�����ū� ��� output �ͧ������������ input ��� �����ū�) ����������ö��ŵͺʹͧ�����ū�������»�ҡ���ó�ѧ������� ������ͧ�ŵͺʹͧ�����ū������Ѻ characteristics ���Ŵ��ͧ�������
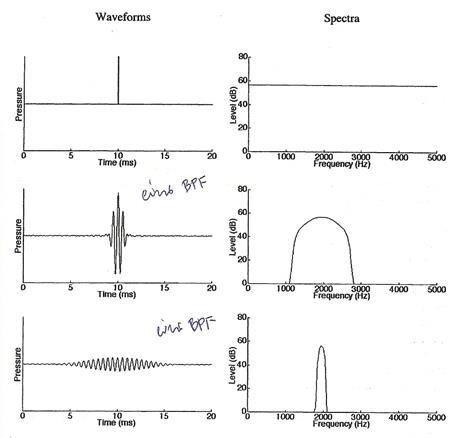
�ҡ�ٻ �� �ʴ� waveform �Ѻ������ͧ�����ū� �ͧ�ٻ ��ҧ ��ҧ �ʴ��ŵͺʹͧ�����ū�Ѻ�������ѧ�ҡ�ѭ�ҳ��ٻ����ҹ band-pass filter ���ᵡ��ҧ�ѹ�ͧ��� spectral characteristics �ͧ������������Ѻ������ͧ�ŵͺʹͧ�����ū�
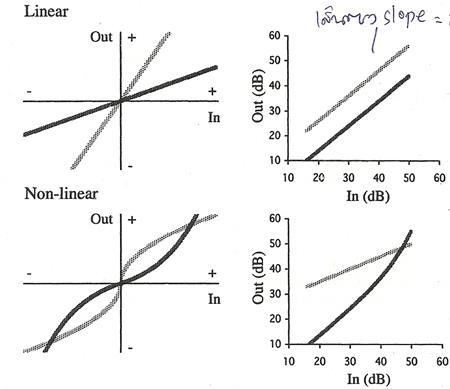
9. ��к��ԧ��� �����ѹ�������൨ output ��ҡѺ�Ťٳ�ͧ��Ҥ����Ѻ�����ѹ�������൨ input �͡�ҡ��� output ������ͧ���Сͺ�ҧ������������ input ��ҹ�� ��ǹ��к����������ԧ��� �����ѹ�������൨ output ����繤�Ҥ������Ңͧ�����ѹ�������൨ input �����ͧ���Сͺ�ҧ��������� output �������ҡ��ͧ���Сͺ��������� input ͧ���Сͺ����Դ��鹷�� output ������¡��� distortion products
�ٻ��ҹ��ҧ �� ��� pure tone ��������� 1 kHz �Ѻ������ͧ�ѹ ������ pure tone 仼�ҹ�ѧ�����ҡ����ͧ ��������Ѿ��˹�ҵҴѧ�ٻ��ҧ ����ٻ��ҧ ��Ҩ���繼��Ѿ����ѧ�ҡ��� pure tone �ٻ��仼�ҹǧ�����§�����Ẻ���觤��� ��ô��Թ��÷���ͧ���ҧ���������ԧ��� ��Ҩ֧���������������ҡ�����Թ�ص��������ҵ�ص
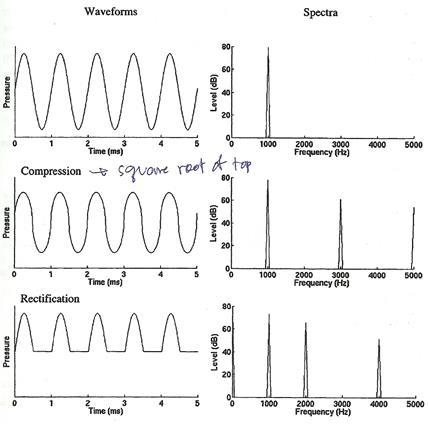
�ٻ����� �� �ʴ� pure tone ��������� 1800 Hz �Ѻ 2000 Hz ����ѹ ��ǹ�ٻ��ҧ�����ҧ ��ҹ� pure tone �ͧ�����ٻ��仴��Թ��ü�ҹ�ѧ�����Ҥ���ҡ����ͧ�Ѻǧ�����§����ʤ��觤��蹵���ӴѺ (�ӹͧ���ǡѺ�ٻ��˹�ҹ�� ����ǹ�� input �� tone ����դ����Ѻ�������˹���)
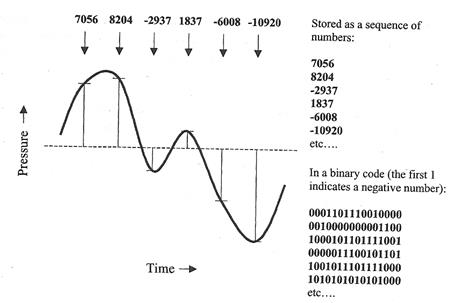
10. �������ö�ŧ waveform ����դ���������ͧ������ӴѺ�ͧ�Ţ�ҹ�ͧ������ʴ������ѹ�������൨���ش��ҧ � ��������ͧ�ҧ������ ��蹤���ѭ�ҳ�ԨԷ�� �������ö���繵��᷹ͧ���Сͺ� � � waveform �鹩�Ѻ ���¤�������٧�ش�֧����˹�觢ͧ�ѵ�� sampling
�ٻ�ʴ�����ŧ�������§���ӴѺ�ͧ����Ţ�ҹ�ͧ
| Create Date : 27 ����¹ 2556 | | |
| Last Update : 22 �ԧ�Ҥ� 2556 21:11:29 �. |
| Counter : 3970 Pageviews. |
| |
|
| |
|
|
|
The Nature of Sound (��ػ)
�����ҵ������§�ӴѺ�����ػ���Ǣ�� 2.6 Summary ��Т��¤���������������Ǣ�͡�˹�Ҩҡ����� 2 The Nature of Sound ˹ѧ��� The Sense of HEARING �ͧ Christopher J. Plack
1. ���§�Դ�ҡ�������¹�ŧ�����ѹ㹵�ǡ�ҧ�ҧ���ҧ �� �ҡ�� �����ѹ�������¹�ŧ���С�Ш���͡�ҡ���觡��Դ���§�����ѵ�����Ƿ��������Ѻ��Դ�ͧ��ǡ�ҧ��� �� �ѵ���������§��ҡ�ȷ������ѹ����ҡ�� �դ�һ���ҳ 330 ����/�Թҷ� (�ѵ���������§��ҡ�� �͡�ҡ�Т�鹡Ѻ�����ѹ�ҡ�������ѧ�������Ѻ�س������ա����) ���š��������͡������¹�ŧ�����ѹ�ͧ��ǡ�ҧ����ö�ʴ������������١���쿷��������ѹ����ʻ�ԧ �ٻ�ʴ�������� 6 ���������ͧ�ѹ�ҡ��ŧ��ҧ
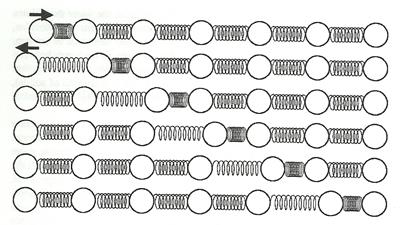
��÷��������ѹ����¹�ŧ�ش㴨ش˹�� ���觼����������¹�����ѹ�������Ш�µ���͡�����ѵ�����Ƿ��������Ѻ����˹��� (density) ��Ф����秷��� (stiffness) �ͧ���õ�ǡ�ҧ ��ҵ�ǡ�ҧ˹����ҡ �ѵ�����Ǩе�� �����ѵ�ط������ҡ�����ҹҹ����㹡����� ��ǹ��ǡ�ҧ����秷��͡��� �ѵ���������§���ҡ���� �� ���§�Թ�ҧ����� (stiffness �٧�ҡ) �����ѵ������ 5200 m/s ��з���Թ�ҧ��ҧ��š�乫� (vulcanized rubber) ����դ���˹����٧������秷��� �����ѵ������ 54 m/s �óյ�ǡ�ҧ���� �֧����Ө�˹��蹡����ҡ�� �� stiffness �ͧ����٧�����ҡ���ҡ ������ѵ�����Ǣͧ���§㹹�ӻ���ҳ 1500 m/s
2. pure tone ��� ���§����ա������¹�ŧ�����ѹ��������Ҽ�ҹ�Ẻ sinusoidal �¤������ͧ pure tone ����ҡ�ӹǹ�١���� (�����Ѻ�ѹ˹���ͺ�ͧ�ѹ���蹡Ѻ��ͧ����) ����Դ���㹪�ǧ���� ��ФҺ�ͧ pure tone ��� ���������ҧ�ʹ�����ͧ�ʹ�������Դ�ѹ ������ҧ�����ҧ�ʹ���蹷���ͧ��� ���¡��� ������Ǥ���
3. ��Ҵ (magnitude) �ͧ�������§����ö�ٴ�֧����ٻ�ͧ �����ѹ ���ͤ������ (intensity) �ͧ�������§ ���;ٴ�֧�дѺ���§�˹��� logarithm ������¡��� ഫ��� (dB) ��ҹ�����˹��� dB �����ҡ��˹��¢ͧ�����ѹ (N/m2) ���ͤ������ (W/m2) ��� ��ǧ�������ҧ�ͧ���§���������Թ���դ�������� ����дǡ �ٴ仾ٴ�����ǧ� ���§�����������������纻Ǵ�բմ������������������ҳ 1,000,000,000,000 ��Ңͧ����������§�ҷ���ش���������Թ
�дѺ���§�˹��� dB = 10 log10(I/I0) ���� = 20 log10(P/P0) ���� I ∼ P2
I0 ��� P0 ��� �дѺ���������ҧ�ԧ��Ф����ѹ��ҧ�ԧ ��ҡѹ�������������� ����Ѻ�дѺ���§��ҡ�� ���������ѹ��ҧ�ԧ��ҡѺ 0.00002 N/m2 (���� I0 = 10-12 W/m2) ��ж��������ѹ��ҧ�ԧ��ҹ�� ��Ҩ����¡�дѺ���§�˹��� dB �ѧ�������� SPL (sound presure level) ��蹤�� ���§����դ����ѹ��ҡѺ�����ѹ��ҧ�ԧ �����дѺ���§��ҡѺ 0 dB SPL (�������� ���� P = P0 ��� log 1 = 0) �ѹ����ԧ��Ҥ����ѹ��ҧ�ԧ�ѧ����� ������͡���� 0 dB SPL ���դ�������§�Ѻ�дѺ���§��ӷ���ش����������ö���Թ��������� 1 kHz
�ͧ�Դ��� � ��Ѻ �����ѹ����ҡ�Ȼ���ҳ 105 N/m2 ������§���ش����������ö���Թ����ѹ��Ѻ�����ѹ�ǹ�ͧ�����ѹ��� 2 x 10-5 N/m2 ���¤������ �������ö���Թ�������§����դ����ѹ�ѹ�ǹ��ӡ���˹��㹾ѹ��ҹ�ͧ�����ѹ����ҡ�� ���º��º��Ѻ���蹹�ӷ���դ����٧�� 1 ��������ú���������ط÷���դ����֡ 1,000 �������� !!! ����з�����§����дѺ 120 dB SPL �ѹ���дѺ�������س�Ǵ������觼����µ���� ���դ����ѹ�ǹ�ͧ�����ѹ���¢�Ҵ����ӡ����дѺ�����ѹ����ҡ�ȶ֧��Ҿѹ��� ���ѧ�к͡��� �������¹�ŧ�ͧ�����ѹ�������§���������Թ�ѹ㹪��Ե��Ш��ѹ����դ�ҹ��¹Դ��§�� �ʴ�����������٢ͧ����������з�� sensitive ��§��
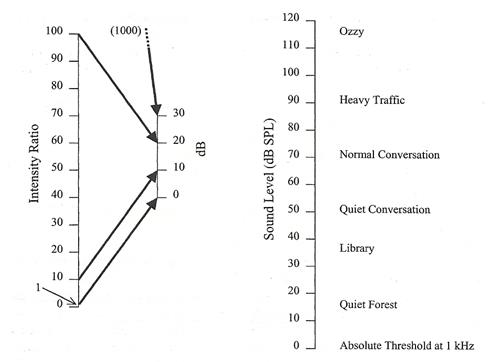
�ٻ�ʴ���èѺ��� (map) �����ҧ�ѵ����ǹ�ͧ������� I/I0 �Ѻ dB SPL ����ʴ� dB SPL �ͧ���§��ҧ � 㹪��Ե��Ш��ѹ ����дѺ�٧�ش �����¹������ Ozzy �����ҧ�֧ Ozzy Osbourne ��͡����㹵ӹҹ �繤����ǹ��Т����蹢ͧ�����¹��Ѻ ͡��� ����˹�������Թ Ozzy Osbourne �͡��� ����ǹ�������������Թ���§��������� ���з���ҹ�ҿѧ���§�ѧ 30 �ѹ��ҹഫ����ҷ�駪��Ե ����дѺ 30 �ѹ��ҹഫ��Ź����ҡѺ 102999999988 W/m2 �ѹ�繡��ѧ�ҹ����ҡ�ͨз���·���͡�� �Ѻ��������áѺ�٢ͧ Ozzy �֧��¹㹡�ҿ��ҹ������дѺ�٧�ش������ Ozzy
����������˹��� dB ����� logarithm �Ф�Ѻ ������������§�дѺ 40 dB SPL ��ҡѺ�ա���§˹�觫�����дѺ 40 dB SPL �����ѹ ���Ѿ���������������§������дѺ 80 dB SPL �������§ 80 dB SPL ����դ�������ҡ�������§ 40 dB SPL �֧˹��������� (���� 40 dB ⇔ I = 10,000 I0 ��� 80 dB ⇔ I = 100,000,000 I0) 㹤����繨�ԧ �ͧ���§�������ѹ�������§����дѺ 43 dB SPL (�������դ�������ѹ��ͧ����Ẻ����)
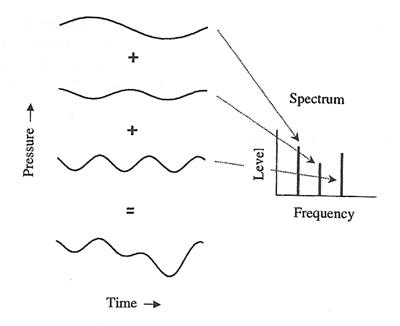
4. (4.1) �������§� � ����ö���ҧ������¡����� pure tone ���� � �ѹ����բ�Ҵ (amplitude) ������� ����� ��ҧ�ѹ, (4.2) ��þ��͵������ͧ�������§�ʴ��������дѺ�ͧͧ���Сͺ pure tone �����ѹ����������ͤ������, (4.3) �������ͧ���§�ʴ� short-term spectrum �ͧ���§ �繿ѧ���蹢ͧ����, (4.4) ���ͧ�ҡ time-frequency tradeoff ����������������´ (resolution) ��������� ��Ŵ���������´������������ ��С���������������´������������ ���Ф��������´���������
�ٻ��ҹ��ҧ����ʴ�������ҧ�ҡ��ͤ��� 4.1 ��� 4.2
�ٻ���仹���ʴ� waveform ���������ͧ pure tone ����դ������ 2 kHz 㹪�ǧ���� 20 ms (�ٻ��), 10 ms (�ٻ��ҧ) ����ٻ��ҧ�ʴ� waveform �Ѻ������ͧ�ѭ�ҳ impulse
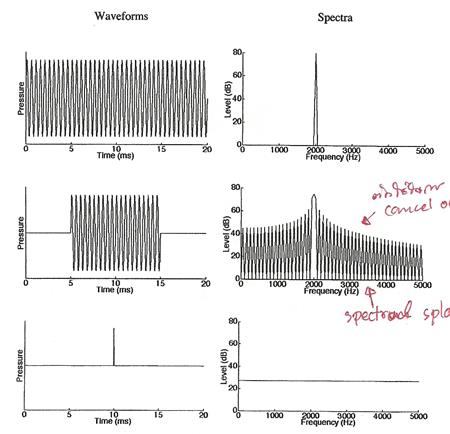
㹡óբͧ pure tone ��������ͧ����ըش������� ����ըش����� ������ͧ�ѹ�������˹����鹷��������ͧ pure tone ������ pure tone ��ǧ������� � ����ٻ ������ͧ�ѹ�С��ҧ��� ������令�� �������¹�ŧ�����Ԩٴ�ѹ�շѹ������������� ���¶֧��������ѹ��Ѻ����������Ԩٴ��Ш��������ҧ��������� ��С������¹�ŧ�ѹ�շѹ㴢ͧ�����Ԩٴ��������� ���¶֧����������Ԩٴ��Ш��������ҧ������������
��������ѹ���ѹ���͡������ ���������������ѭ�ҳ���§��ǧ������� � ����� �����������������ͧ�ѹ�����觡�Ш���͡�ҡ (blurred) ��ҹ�� �֧�Դ time-frequency tradeoff ��觤��������´������٧ ���������´㹤�������������
�ٻ��ҹ��ҧ�ʴ��������ͧ�ѭ�ҳ pure tone ������ͧ����ѭ�ҳ impulse �������繡�þ��͵�дѺ���¤�������ͧ�մӺ��������� (�) ��Ф������ (���) ���;ٴ����ʴ� short-term spectrum �ͧ���§��������� �ҡ�ٻ �����Ҷ�Ҫ�ǧ�ͧ window ᤺ (���������´�ҧ�����٧) �����������������ҧ���� ��͡��� (����� window ���������ҡ������dz�ͺ�ͧ��õѴ����Դ�������¹�ŧ�ѹ�շѹ�)
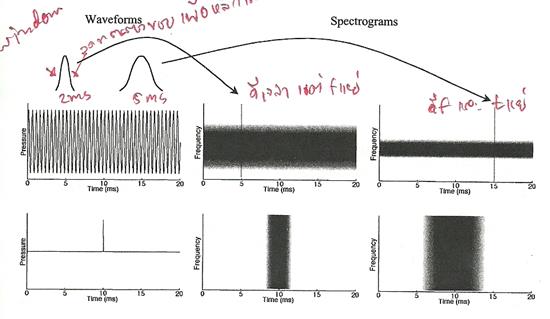
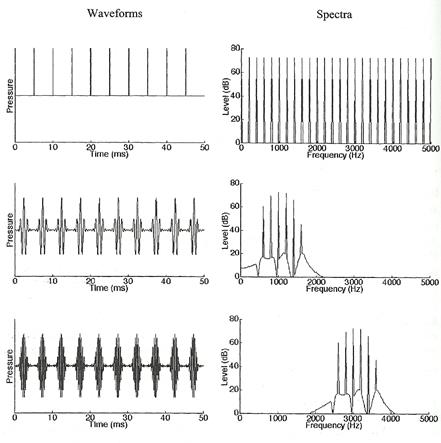
5. complex tone Ẻ��ӤҺ���� waveform ����� � �ѹ��ʹ��ǧ���� ������ͧ���§����ҹ����ͧ���Сͺ pure tone �ӹǹ˹�� ����դ�������繨ӹǹ�����Ңͧ���������Űҹ (fundamental frequency) ���ͨӹǹ�ͧ waveform ����Դ��鹫�� � ����˹���Թҷ� �ٻ��ҹ��ҧ�ʴ� waveform ���������ͧ complex tone ����ѭ�ҳ �ٻ�� �Һ�ͧ waveform ��ҡѺ 10 ms ��蹤�� ���������Űҹ��ҡѺ 100 Hz �ٻ��ҧ�Ѻ�ٻ��ҧ�դҺ��ҡѺ 5 ms ��Ф��������Űҹ 200 Hz
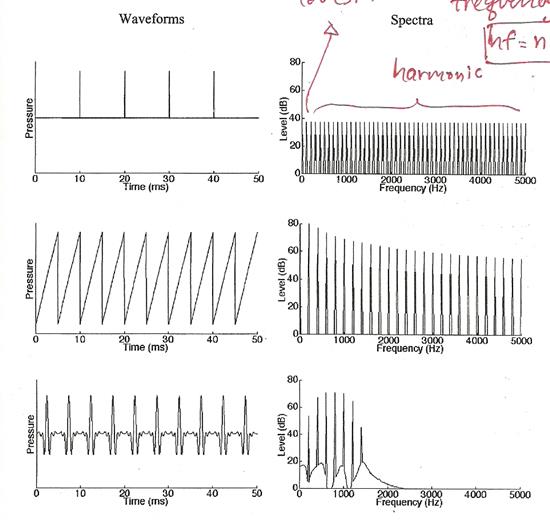
㹡óա�����ͧ�����ԡ�������ѹẺ���㨩ѹ ���������Űҹ��ͨӹǹ����դ���ҡ����ش�������ö������ä������ͧ�����ԡ��ء�����ŧ��� �� �����ԡ���Сͺ���� 550 600 700 750 Hz ���������Űҹ����ҡѺ 50 Hz
�ٻ��ҹ��ҧ�ʴ�������ҧ complex tone ������ҧ�ҡ pure tone ���� � ��ǫ���դ�������繨ӹǹ����������ѹ waveform �����¹�Ţ 1 ���ͧ���Сͺ��Űҹ ��Ш��������ѵ�ҡ�ë�Ӣͧ complex tone ��ҡѺ�������ͧͧ���Сͺ��Űҹ ��� 200 Hz
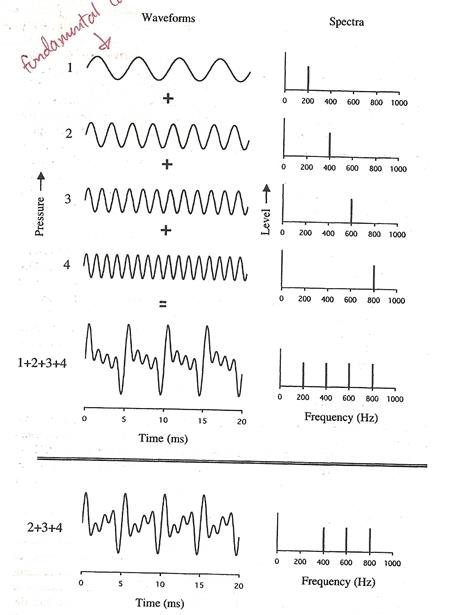
�չ�� �ѧࡵ�ٻ��ҧ�ش (�ҡ�ٻ��ҧ��) 2+3+4 ���źͧ���Сͺ��鹰ҹ���� waveform �ͧ�ѹ��˹ҵ�ᵡ��ҧ�ҡ 1+2+3+4 ���ѵ�ҡ�ë���ٻ�ѧ������� ��� 200 Hz ��蹤�� ���������Űҹ�ͧ complex tone �������Ѻ������ҧ�ͧ�����ԡ�� �����������ͧ�����ԡ�����ش����ҡ�
�ٻ��ҹ��ҧ�ʴ� complex tone �ͧ���§����դ��������Űҹ���ǡѹ ��� 200 Hz ��������ͧ�ǡ�ѹᵡ��ҧ�ѹ���ҧ����ԧ ���§�ٻ��������������״���� ��з�����§�ҡ�ٻ��ҧ�����ҧʴ�ʡ��� �����ͺ�Ӷ��������˵������ͧ����� 2 ��鹷����������ǡѹ�֧�����§ᵡ��ҧ�ѹ ������������ᵡ��ҧ�ѹ ��蹡������ç���ҧ�����ԡ�ͧ���§����ͧ��ҧ�ѹ
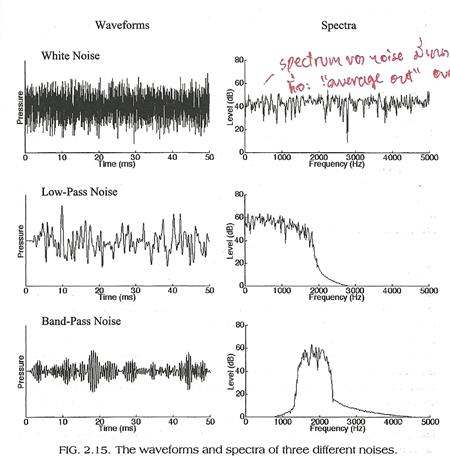
6. ���§ú�ǹ (noise) �դ����ѹ�ǹ�ͧ�ç�ѹ��Ẻ������ʹ��ǧ���� ������ͧ noise ���ա�á�Ш�¢ͧͧ���Сͺ�ҧ��������������ͧ ������ҧ noise ���������ͧ�ѹ�ʴ��ѧ�ٻ��ҧ��ҧ���
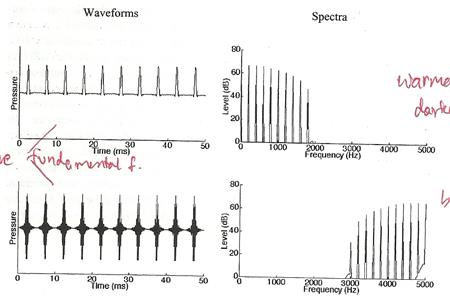
7. Amplitude modulation ��͡������¹�����Ԩٴ�ͧ envelope �ͧ���§���������, Frequency modulation ��͡������¹�ŧ�������ͧ���§��������� ��ô��Թ��÷�駤����觼š�з��������� ������ҧͧ���Сͺ�ҧ��������������������ա�ӹǹ˹��
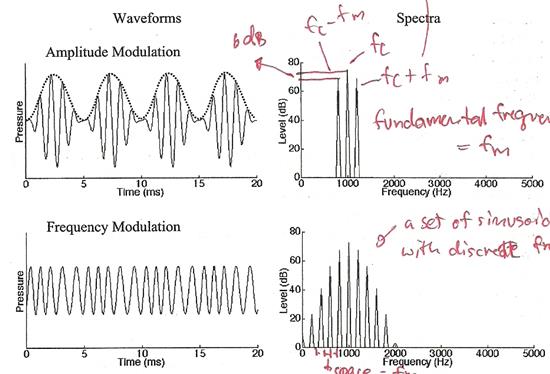
�ٻ���ʴ� pure tone ��������� 1 kHz �ʹ��ŵ�����Ԩٴ�Ѻ sinusoidal ��������� 200 Hz ������������ա������¹�ŧ �� spectral side bands ��������� 800 ��� 1200 Hz ��ǹ�ٻ��ҧ�� frequency modulation �����������ҧ�����ҧ�������ҡѺ 200 Hz
| Create Date : 25 ����¹ 2556 | | |
| Last Update : 26 ����¹ 2556 20:57:10 �. |
| Counter : 5073 Pageviews. |
| |
|
| |
|
|
|
��úѭ���������ͧ�����ѧ�֡��
����ǹ��������ҧ������¹��� ����������Ǣ�ͧ�Ѻ �� ����Ѻ������§ ��÷���¹�Ӣͧ���§ (audio watermarking) ��С�ë�����������§ ����֧����ͧ��� DSP ��鹰ҹ ����������ҧ��������͡���������ѹ��� 5 ����¹ 2556 ��������������������ش�ѹ��� 25 �á�Ҥ� 2558
��鹰ҹIntroduction to Digital Audio Watermarking [11 �Զع�¹ 2556]
Audio Watermarking Algorithms: State-of-the-Art [14 �Զع�¹ 2556]
����������ǡѺ����Ѻ������§Judgment of Perceptual Synchrony Between Two Pulses and Its Relation to the Cochlear Delays [16 ����¹ 2556]
Masking [3 �ѹ��¹ 2556]
Audio Watermarking TechniquesAn Audio Watermarking Algorithm Based on Fast Fourier Transform [5 ����¹ 2556]
A New Audio Watermarking Scheme Based on Singular Value Decomposition and Quantization [14 ����¹ 2556]
High Capacity Audio Watermarking Using the High Frequency Band of Wavelet Domain [18 ����¹ 2556]
Method of Digital-Audio Watermarking Based on Cochlear Delay Characteristics [26 ����¹ 2556]
Audio Watermarking Based on Spread Spectrum Communication Technique [6 ����Ҥ� 2556]
Echo Data Hiding [14 �Զع�¹ 2556]
Experiments with and Enhancements to Echo Hiding [16 �Զع�¹ 2556]
Experimental Research on Parameter Selection of Echo Hiding in Voice [20 �Զع�¹ 2556]
Audio Watermarking of Stereo Signals Based on Echo-Hiding Method [20 �Զع�¹ 2556]
EMD and Psychoacoustic Model Based Watermarking for Audio [15 �á�Ҥ� 2556]
A Novel Echo-Hiding Scheme with Backward and Forward Kernels [15 �á�Ҥ� 2556]
Analysis-by-Synthesis Echo Hiding Scheme Using Mirrored Kernels [15 �á�Ҥ� 2556]
Researches on Echo Kernels of Audio Digital Watermarking Technology Based on Echo Hiding [15 �á�Ҥ� 2556]
Research of Improved Echo Data Hiding: Audio Watermarking based on Reverberation [16 �á�Ҥ� 2556]
Reversible Watermarking for Digital Audio Based on Cochlear Delay Characteristics [27 �á�Ҥ� 2556]
Detection of Tampering in Speech Signals with Inaudible Watermarking Technique [27 �á�Ҥ� 2556]
Data-hiding Scheme for Digital-Audio in Amplitude Modulation Domain [27 �á�Ҥ� 2556]
An SVD-Based Audio Watermarking Technique [27 �ԧ�Ҥ� 2556]
Flaw in SVD-based Watermarking [27 �ԧ�Ҥ� 2556]
����ͧ���What is a Cepstrum? [21 �Զع�¹ 2556]
Arnold Transform (Arnold's Cat Map) [5 �á�Ҥ� 2556]
Hilbert-Huang Transform [16 �á�Ҥ� 2556]
Correlation [27 �á�Ҥ� 2556]
Least Squares [28 �á�Ҥ� 2556]
Orthogonality [28 �á�Ҥ� 2556]
Differential Evolution [28 ���Ҥ� 2558]
���ͧ��蹡Ѻ pitch �ͧ complex tones [25 �á�Ҥ� 2558] �NEW�
���ͧ��蹡Ѻ���ͧ�������§����Ҷ֧�� [25 �á�Ҥ� 2558] �NEW�
���ҷ�����Сͺ������¹���               
| [01]� | The Sense of Hearing �� Christopher J. Plack (Psychology Press, 2005) | | [02]� | An Introduction to the Psychology of Hearing (6th Ed) �� Brian C. J. Moore (Emerald, 2012) | | [03]� | The Science of Sound (3rd Ed) �� Rossing, Moore �Ѻ Wheeler (Addison Wesley, 2002) | | [04]� | Applied Signal Processing �� Thierry Dutoit �Ѻ Ferran Marques (Springer, 2009) | | [05]� | Audio Signal Processing and Coding �� A. Spanias, T. Painter �Ѻ V. Atti (Wiley, 2007) | | [06]� | Fundamentals of Acoustic Signal Processing �� M. Tohyaman �Ѻ T. Koike (AP, 1998) | | [07]� | Digital Signal Processing with Examples in MATLAB �� S. Stearns �Ѻ D. Hush (CRC, 2011) | | [08]� | Signal Processing, Perceptual Coding and Watermarking of Digital Audio �� Xing He (IGI Global, 2011) | | [09]� | Watermarking in Audio �� Xing He (Cambria Press, 2008) | | [10]� | Advanced Techniques in Multimedia Watermarking �� Ali Mohammad Al-Haj (Information Science Reference, 2010) | | [11]� | Digital Audio Watermarking Techniques and Technologies �� Nedeljko Cvejic �Ѻ Tapio Seppanen (IGI Global, 2007) | | [12]� | Digital Watermarking and Steganography �� I. Cox, M. Miller, J. Bloom, J. Fridrich, �Ѻ T. Kalker (Morgan Kaufmann, 2007) | | [13]� | Elements of Wavelets for Engineers and Scientists �� Dwight F. Mix �Ѻ Kraig J. Olejniczak (John Wiley & Sons, 2003) | | [14]� | Introduction to Data Compression (2nd Ed) �� Khalid Sayood (Morgan Kaufmann, 2000) | | [15]� | Digital Filters (2nd Ed) �� R.W. Hamming (Prentice-Hall, 1983) | | [16]� | Mathematical Tools in Signal Processing with c++ and Java Simulations �� Willi-Hans Steeb (World Scientific, 2005) |
Readings| [001]� | S. A. Craver, M. Wu, and B. Liu, "What Can We Reasonably Expect from Watermarks?," in Proc. IEEE Workshop on Application of Signal Processing to Audio and Acoustics, New York, pp. 223-226, 2001 | | [002]� | M. Fallahpour and D. Megias, "High Capacity Audio Watermarking Using the High Frequency Band of the Wavelet Domain," Multimedia Tools and Applications, vol. 52, no. 2-3, pp. 485-498, 2011 | | [003]� | E. Ercelebi and L. Batakci, "Audio Watermarking Scheme Based on Embedding Strategy in Low Frequency Components with a Binary Image," Digital Signal Processing, vol. 19, no. 2, pp. 265-277, 2009 | | [004]� | M. Unoki and D. Hamada, "Method of Digital-Audio Watermarking Based on Cochlear Delay Characteristics," International Journal of Innovative Computing, Information and Control, vol. 6, no. 3, pp. 1325-1346, 2010 | | [005]� | V. Bhat, I. Sengupta, and A. Das, "A New Audio Watermarking Scheme Based on Singular Value Decomposition and Quantization," Circuits Systems and Signal Processing, vol. 30, no. 5, pp. 915-927, 2011 | | [006]� | S. Lee and Su. Jung, "A Survey of Watermarking Techniques Applied to Multimedia," in Proc. IEEE International Symposium on Industrial Electronics Proceedings, 2001 | | [007]� | X. Wen, X. Ding, J. Li, L. Gao, and H. Sun, �An Audio Watermarking Algorithm Based on Fast Fourier Transform,� in Proc. International Conference on Information Management, Innovation Management and Industrial Engineering Proceeding, pp. 363-366, 2009 | | [008]� | E. Aiba, M. Tsuzuki, S. Tanaka, M. Unoki, �Judgment of Perceptual Synchrony Between Two Pulses and Its Relation to the Cochlear Delays,� J. Psychological Research, Vol. 50, No. 4, 2008 | | [009]� | W. Bender, D. Gruhl, N. Morimoto and A. Lu, "Techniques for data hiding," IBM Systems Journal, vol. 35, no. 384, pp. 313-336, 1996 | | [010]� | H. J. Kim and Y. H. Choi, "A Novel Echo-Hiding Scheme With Backward and Forward Kernels," IEEE Transactions on Circuits and Systems for Video Technology, vol. 13, no. 8, pp. 885-889, 2003 | | [011]� | W. Wu and O. Chen, "Analysis-by-Synthesis Echo Hiding Scheme Using Mirrored Kernels," in Proc. IEEE International Conference on Acoustics, Speech, and Signal Processing, Toulouse, pp. 325-328, 2006 | | [012]� | G. Nian, S. Wang, and Y. Ge, "Research of Improved Echo Data Hiding: Audio Watermarking Based on Reverberation," in Proc. IEEE International Conference on Acoustics, Speech, and Signal Processing, Honolulu, pp. 117-180, 2007 | | [013]� | F. Wei and D. Qi, "Audio Watermarking of Stereo Signals Based on Echo-Hiding Method," in Proc. International Conference on Information, Communications and Signal Processing, Macau, 2009 | | [014]� | W. Yunlu and W. Zhendong, "Blind Detection on Echo Hiding Based on Cepstrums," in IEEE Youth Conference on Information, Computing and Telecommunication, Beijing, pp. 235-238, 2009 | | [015]� | L. Li and Y. Song, "Experimental Research on Parameter Selection of Echo Hiding in Voice," in Proc. International Conference on Machine Learning and Cybernetics, Baoding, pp. 2423-2426, 2009 | | [016]� | S. Mitra and S. Manoharan, "Experiments with and Enhancements on Echo Hiding," in Proc. International Conference on Systems and Networks Communications, Porto, pp. 119-124, 2009 | | [017]� | X. Cao and L. Zhang, "Researches on Echo Kernels of Audio Digital Watermarking Technology Based on Echo Hiding," in Proc. International Conference on Wireless Communications and Signal Processing, Nanjing, 2011 | | [018]� | L. Wang, S. Emmaue, and M.S. Kankanhalli, "EMD and Psychoacoustic Model Based Watermarking for Audio," in Proc. IEEE International Conference on Multimedia and Expo, Suntec City, pp. 1427-1432, 2010 | | [019]� | F.R. Moore, "An Introduction to the Mathematics of Digital Signal Processing Part I: Algebra, Trigonometry, and the Most Beautiful Formula in Mathematics," Computer Music Journal, vol. 2, no. 1, pp. 38-47, 1978 | | [020]� | F.R. Moore, "An Introduction to the Mathematics of Digital Signal Processing Part II: Sampling, Transforms, and Digital Filtering," Computer Music Journal, vol. 2, no. 2, pp. 38-60, 1978 | | [021]� | X. Zhang and Y. Hao, "An Adaptive Audio Watermarking Algorithm Based on Cepstrum Transform," in Proc. International Conference on Computational Sciences and Optimization, Harbin, pp. 806-809, 2012 | | [022]� | V. Korzhik, G. Morales-Luna, and I. Fedyanin, "The Use of Wet Paper Codes With Audio Watermarking Based on Echo Hiding," in Proc. Federated Conference on Computer Science and Information Systems, Wroclaw, pp. 727-732, 2012 | | [023]� | M.S. Al-Yaman, M.A. Al-Taee, and H.A. Alshammas, "Audio-Watermarking Based Ownership Verification System Using Enhanced DWT-SVD Technique," in Proc. International Multi-Conference on Systems, Signals and Devices, Chemnitz, pp. 1-5, 2012 | | [024]� | C. Maha, E. Maher, and B.A. Choki, "A blind audio watermarking scheme based on Neural Network and Psychoacoustic Model with Error correcting code in Wavelet Domain," in Proc. International Symposium on Communications, Control and Signal Processing, St. Julians, pp. 1138-1143, 2008 | | [025]� | K. Ren and H. Li, "Large Capacity Digital Audio Watermarking Algorithm Based on DWT and DCT," in Proc. International Conference on Mechatronic Science, Electric Engineering and Computer, Jilin, pp. 1765-1768, 2011 | | [026]� | N.E. Huang and Z. Wu, "A Review on Hilbert-Huang Transform: Method and Its Application to Geophysical Studies," Reviews of Geophysics, vol. 46, issue 2, 2008 | | [027]� | B. Chen and G.W. Wornell, "Quantization Index Modulation: A Class of Provably Good Methods for Digital Watermarking and Information Embedding," IEEE Transaction on Information Theory, vol. 47, no. 4, 2001 | | [028]� | B. Chen and G.W. Wornell, "Digital Watermarking and Information Embedding Using Dither Modulation," in Proc. IEEE Workshop on Multimedia Signal Processing, Redondo Beach, CA, pp.273-278, 1998 | | [029]� | M. Unoki and R. Miyauchi, "Reversible Watermarking for Digital Audio Based on Cochlear Delay Characteristics," in Proc. International Conference on Intelligent Information Hiding and Multimedia Signal Processing, Dalian, China, pp. 314-317, 2011 | | [030]� | N.M. Ngo, M. Unoki, R. Miyauchi, and Y. Suzuki, "Data-hiding scheme for digital-audio in amplitude modulation domain," in Proc. International Conference on Intelligent Information Hiding and Multimedia Signal Processing, Piraeus, pp. 114-117, 2012 | | [031]� | M. Unoki and R. Miyauchi, "Detection of Tampering in Speech Signals with Inaudible Watermarking Technique," in Proc. International Conference on Intelligent Information Hiding and Multimedia Signal Processing, Piraeus, pp. 118-121, 2012 | | [032]� | E. Ercelebi and L. Batakci, "Audio watermarking scheme based on embedding strategy in low frequency components with a binary image," Digital Signal Processing, vol. 19, issue 2, pp.265-277, 2009 | | [033]� | A.R. Elshazly, M.M. Fouad, and M.E. Nasr, "Secure and Robust High Quality DWT Domain Audio Watermarking Algorithm with Binary Image," in Proc. International Conference on Computer Engineering & Systems, Cairo, pp. 207-212, 2012 | | [034]� | Fathi E. Abd El-Samie, "An Efficient Singular Value Decomposition Algorithm for Digital Audio Watermarking," International Journal of Speech Technology, vol. 12, issue 1, pp. 27-45, 2009 | | [035]� | J. Zhang, "Analysis on Audio Watermarking Algorithm based on SVD," in Proc. 2nd International Conference on Computer Science and Network Technology, Changchun, China, pp. 1986-1989, 2012 | | [036]� | P. K. Dhar and T. Shimamura, "An Audio Watermarking Scheme Using Discrete Fourier Transformation and Singular Value Decomposition," in Proc. 35th International Conference on Telecommunications and Signal Processing, Prague, pp. 789-794, 2012 | | [037]� | H. Ozer, B. Sankur, and N. Memon, "An SVD-based Audio Watermarking Technique," in Proc. the 7th Workshop on Multimedia and Security, New York, pp.51-56, 2005 | | [038]� | G. Suresh, "An Efficient and Simple Audio Watermarking Using DCT-SVD," in Proc. International Conference on Devices, Circuits and System, Coimbatore, pp. 177-181, 2012 | | [039]� | A. Al-Haj, C. Twal, and A. Mohammad, "Hybrid DWT-SVD Audio Watermarking," in Proc. Fifth International Conference on Digital Information Management, Thunder Bay, ON, pp. 525-529, 2010 | | [040]� | L. Lamarche, Y. Liu, and J. Zhao, "Flaw in SVD-based Watermarking," in Proc. Canadian Conference on Electrical and Computer Engineering, Ottawa, Ont., pp. 2082-2085, 2006 | | [041]� | P. K. Dhar and T. Shimamura, "Audio Watermarking in Transform Domain Based on Singular Value Decomposition and Quantization," in Proc. 18th Asia-Pacific Conference on Communications, Jeju Island, pp. 516-521, 2012 | | [042]� | S. Vongpraphip and M. Ketcham, "An Intelligence Audio Watermarking Based on DWT-SVD Using ATS," in Proc. WRI Global Conference on Intelligence Systems, Xiamen, pp. 150-154, 2009 | | [043]� | A. Singhal, A. N. Chaubey, and C. Prakkash, "Audio Watermarking Using Combination of Multilevel Wavelet Decomposition, DCT and SVD," in Proc. International Conference on Emerging Trends in Networks and Computer Communications, Udaipur, pp. 239-243, 2011 | | [044]� | V. Bhat K., I. Sengupta, and A. Das, "An Audio Watermarking Scheme Using Singular Value Decomposition and Dither-Modulation Quantization," Multimedia Tools and Applications, vol. 52, nos. 2-3, pp. 269-283, 2011 | | [045]� | S. Karimimehr, S. Samavi, H. R. Kaviani, and M. Mahdavi, "Robust Audio Watermarking based on HWD and SVD," in Proc. 20th Iranian Conference on Electrical Engineering, Tehran, pp. 1363-1367, 2012 | | [046]� | W. Jiang, "Fragile Audio Watermarking Algorithm Based on SVD and DWT," in Proc. International Conference on Intelligence Computing and Integrated Systems, Guilin, pp. 83-86, 2010 | | [047]� | A. Al-Haj and A. Mohammad, "Digital Audio Watermarking Based on the Discrete Wavelets Transform and Singular Value Decomposition," European Journal of Scientific Research, vol. 39, no. 1, pp. 6-21, 2010 | | [048]� | P. K. Dhar and T. Shimamura, "A DWT-DCT-Based Audio Watermarking Method Using Singular Value Decomposition and Quantization," Journal of Signal Processing, vol. 17, no. 3, pp. 69-79, 2013 | | [049]� | E. Ambikairajah, A. G. Davis, and W. T. K. Wong, "Auditory Masking and MPEG-1 Audio Compression," Electronics & Communication Engineering Journal, vol. 9, issue 4, pp. 165-175, 1997 |
ԾھԹڷ�¡������ �������� �Ի�ڨ����������� ����Ͷ�� �ŷ����ʧ��������������
����� |
| Create Date : 18 ����¹ 2556 | | |
| Last Update : 25 �á�Ҥ� 2558 20:17:25 �. |
| Counter : 2275 Pageviews. |
| |
|
| |
|
|
|
|

 �ҡ��ͤ�����ѧ����
�ҡ��ͤ�����ѧ���� ���Դ������͡ : 85 �� [
���Դ������͡ : 85 �� [