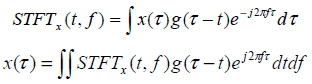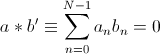|
Flaw in SVD-based Watermarking
[��úѭ���������ͧ�����ѧ�֡��]
�����ҵ������ػ�ҡ������㹪������ǡѹ�ͧ L. Lamarche, Y. Liu �Ѻ J. Zhao �ҡ Canadian Conference on Electrical and Computer Engineering ����͵����һ� 2006 㹺��Ѵ��ͧ͢������ Lamarche ��ҧ�֧ Zhang �Ѻ Li (2005) ������Ԩ�ó� image watermarking �ͧ Liu �Ѻ Tan ������Ԥ SVD ������ʹ������ͻ� 2002 ����ըش�����ͧ ������ͧ�ҡ Ozer ����Ԥ�ѧ������һ���ء����Ѻ audio (����¢ͧ Ozer ����ҡ An SVD-Based Audio Watermarking Technique) Lamarche ��Ф�Ш֧�����Ǩ��з��ͺ��� �Ըա�âͧ Ozer ���ըش�����ͧẺ���ǡѹ������� �ѹ������蹢ͧ������ 㹡�ê��ش�Դ�ͧ��÷���¹���Ҿ��� Zhang ����˵ؼ���� ���ǹ��Ǩ�Ѻ��¹�ӵ�ͧ���������ԡ�� 2 ��ǫ����Ҷ�����������ǧ˹�� �������ԡ���ͧ��ǹ��١���ҧ��������ҧ��鹵�ѧ��¹�ӹФ�Ѻ (��Ҥس��ҹ�������Ǥ�����, ��Ҩ������ ����Ǽ��оٴ�֧����ա��������ҵ��� ��ǧ����) ��С�õ�Ǩ�Ѻ�ѧ����� �������Ѻ����ԡ�� 2 ��ǹ���ҡ�Թ� ������ѵ�ҡ�õ�Ǩ�Ѻ����� false positive �դ���٧ ����Ѻ Lamarche ������鷴�ͧ���ǡ羺���ҧ���ǡѹ
���ǹ�Ԥ�ͧ Ozer �ٻ��ҹ��ҧ�ʴ���ýѧ
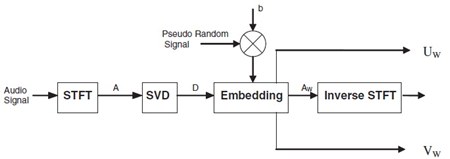
���ѭ�ҳ���§���ŧ STFT �������ҧ����ԡ�� A ��Ҵ FxM (�����ҹ�����鹩�Ѻ �����¹����¹ M by F matrix ��觹�Ҩо����Դ�� �������ǹ�Ѵ�� ��Ҩ���繤�� i �ѹ�ҡ 1 �֧ F ��� j �ѹ�ҡ 1 �֧ M) ����� �¡����ԡ��ѧ����Ǵ��� SVD �� A = UDVT ����� D ������ԡ�� singular value, D = diag(δ1, δ2, ..., δr) ����� δi ��� sv
�Ըա�ýѧ�ͧ Ozer ��͡������¹����ԡ�� D ���� DW �ٴ�ա���ҧ��� �Ťٳ�ͧ UDWVT �� AW ��������ԡ����������ŧ STFT ���ѹ���Ǩ����ѭ�ҳ���§���ѧ��¹��ŧ����º�������� �չ�� 㹡�����ҧ DW �Ҩ����ҧ WD ����ҡ� ���������� WD ���¡���� SVD ��Ҩ��� WD = UWDWVWT
WD ���ҧ�ҡ��ôѴ�ŧ����ԡ�� WFxM ���� watermark carrier ������� element ������ noise ���¤�� δi, a = embedding strength �Ѻ b = polarity {-1, 1} �ͧ watermark �ѧ�����
����������WD(i,j) = δi + abδiw(i,j)
��हФ�Ѻ ��ѧ�ҡ�� WD ����ѹ���¡ SVD ��������� DW ������� DW �᷹��� D � UDVT ��ҡ���� AW �����ŧ inverse STFT �稺 ��駹���駹�� 㹡�õ�Ǩ�Ѻ��¹�� �ҧ��觵�Ǩ�Ѻ�е�ͧ������ԡ�� 2 ��Ǥ�� UW �Ѻ VW �ç������Ф�Ѻ������������ҧ����繵�ǻѭ�� (�Ш�ԧ�����˹ ��ҷ�������� ���ѧ������������ѹ��ӹ�)
�Ҥ��Ǩ�Ѻ��¹���� diagram �ѧ�ٻ
��� watermarked signal ���ŧ STFT �������ҧ����ԡ�� AW �ҡ����� SVD �¡ AW ��������� D'W �� D'W �����Ѻ UW ��� VW ���������ǧ˹�Ҩҡ��鹵��ýѧ �������ҧ W'D = UWD'WVWT ��ѧ�ҡ����� W'D �� W' �ҡ W' = D-1(W'D - D)/a �ش����㹡�õѴ�Թ��ҺԵ���ѧ������� ����� correlation �����ҧ W' �Ѻ W (original watermark) �¶�� ∑wijw'ij ����Ѻ�ء��� i, j �繺ǡ ��Ҩеդ������ b = 1 (bit 1) �͡��� b = -1 (bit 0)
���ǹ��÷��ͧ �����¹�͡����������ö�ӵ����鹵��� Ozer �ʹ��� ������ѧ�ҡ�ӵ�������ͧ Ozer ���ҧ WD ��������� watermarked signal ����� noise �����ҡ! �֧�Ѵ�ŧ����õ�ѧ�������� WD(i,j) = D(i,j) + abD(i,j)w(i,j) ��ʹѴ�ŧ���ҧ������� �ջѭ�ҵ detect �ա �֧�Ѵ�ŧ�ա���� �� WD(i,j) = D(i,j) + abw(i,j) �й������õ��Ǩ�Ѻ�֧��ͧ����¹��� �� W' = (W'D - D)/a
��÷��ͺ��� 1 ��¹�� Wr ����Ѻ bit = 1 �١�ѧŧ��ѭ�ҳ���§�ٴ X0 ���ѭ�ҳ XW ���������ԡ�� UW �Ѻ VW �չ�� ᷹������ XW �� input ����Ѻ detection stage �����ѭ�ҳ Y ��������§�ٴ�ա�ѹ˹��᷹ �ѭ�ҳ Y ����������¹�ӹФ�Ѻ ����繤����ѹ�Ѻ X0 ��ҡ���� �� Y �����Ѻ UW ��� VW �ҡ�����ö��Ǩ�Ѻ��¹���� �ٻ��ҹ��ҧ �����¹�ӷ��֧�Ҩҡ Y �Ҥ�������¡Ѻ��¹�ӷ�����ҧ���ҧ���� 200 ��� �µ�Ƿ�� 100 ����¹�Ӣͧ��ԧ ��㹤����繨�ԧ Y �������¹��!
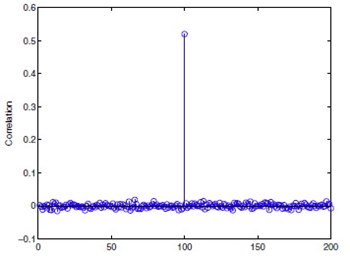
��÷��ͺ��� 2 ���� UW �Ѻ VW �¡����� noise ��� � U'W = UW + cUNoise ��� V'W = VW + cVNoise ����� UNoise �Ѻ VNoise �� random noise matrices ����ա��ᨡᨧẺ���� ��� c ��� noise variance �óշ�� c = 10 ����ʹ֧��¹�Өҡ XW ���� U'W �Ѻ V'W ����Ҥ��������Ѻ��¹�ӷ������ 200 ����µ�Ƿ�� 100 ����¹�Ө�ԧ������Ѿ��ѧ�ٻ �����ҡóչ�� correlation �Ѻ��¹�������������� 0 ���¤������ false positive rate �٧

�������ͤӹdz BER ����ͷ��ͺ 1000 ���駷���� c = 1, 10 ��� 100 ����ӴѺ������Դ error 47 ��������Ѻ��� 3 �ó� ��蹤�� BER = 4.7% ����Ѻ������ noise ŧ�����ԡ�� �����¹��ػ��� �Ҥ��Ǩ�Ѻ�ͧ Ozer �������Ѻ����ԡ�������ҧ��ѧ����觼�ҹ������Ǩ�Ѻ�ҡ�Թ� ������������Ѻ watermarked signal �����㹡�÷��ͺ
��ҼŨҡ��������ԧ �Ըբͧ Ozer ��Ҩ��ͻѭ�ҫ������ ����������� ������ͧ�Ԥ����觼�ҹ UW �Ѻ VW ��Ҩ������÷������ � �ѹ, ��ҷ���� review �Ҷ֧��й�� ���ѧ������÷��ͺ��â������Ѻ����ԡ���ͧ��ǹ��㹡�����Ԥ������¤�֧�Ѻ�ҹ�ͧ Ozer ��
| Create Date : 27 �ԧ�Ҥ� 2556 | | |
| Last Update : 27 �ԧ�Ҥ� 2556 20:59:32 �. |
| Counter : 1282 Pageviews. |
| |
|
 |
|
|
|
An SVD-Based Audio Watermarking Technique
[��úѭ���������ͧ�����ѧ�֡��]
�����ҵ������ػ�ҡ������㹪������ǡѹ�ͧ H. Ozer, B. Sankur �Ѻ N. Memon �ҡ Workshop on Multimedia and Security ���駷�� 7 �� 2005 ��� New York ����¢ͧ�������١�����ҧ�֧��е���ʹ��ա���º������Ф�Ѻ ����� SVD-based ���ᵡ��ҧ�ҡ�Ԥ����������仡�˹�� (�� A New Audio Watermarking Scheme Based on Singular Value Decomposition and Quantization) ��м��Ѿ������ҡ�Ԥ��� robustness �٧�ҡ ��й�� 㹻� 2006 �պ������ͧ L. Lamarche ��Ф�Шҡ Canadian Conference on Electrical and Computer Engineering ����͵����� �͡����駶֧��õդ��� robustness �٧�Թ����ͧ�ҡ BER ����ӹ���繼�����ͧ�ͧ false positive detection rate ����٧ ��������´�������ͧ Lamarche (2006) ������������Һ��͡����� ����Ѻ������Ҩ��֡������¢ͧ Ozer ��Ф�Сѹ��
��鹵��ë���¹�� ������ҡ ����ѭ�ҳ���§���ŧ STFT ����� analysis ��� reconstruction �ͧ STFT ���
����������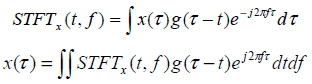
����� g(t) �� window function �������令ٳ�Ѻ�ѭ�ҳ���§ x(t) ��ʹ��ҹ������ѭ�ҳ x(t) ����Ҽ��Ѿ��ҡ��äٳ������ŧ�������� ��ѧ�ҡ�ŧ ��Ҩ���ѧ����������������������� �����������ҧ������ԡ���ͧ�ԵԢ�Ҵ FxM ����� F ��� �ӹǹ��� (�������Ѻ������Ǣͧ x(t)) ��� M ��� ��Ҵ�ͧ���
����� �������ԡ��ѧ��������¡���� SVD: AFxM = UDVT ����� D �� diagonal matrix ��Ҵ FxM ����� elements ����鹷�§��� ���ͷ�����¡��� singular value (sv) �ӹǹ min(F,M) ��� ��ǹ U �Ѻ V �� orthogonal matrix ��Ҵ FxF �Ѻ MxM ����ӴѺ ���ѵԷ���Ӥѭ�ͧ SVD ��� sv �������¹�ŧ����� orthogonal transformation
��ѧ�ҡ�� D ���� ��Ҩнѧ��¹��ŧ� D ���� watermark (������ӴѺ�ͧ�����Ţ�ҹ�ͧ) �����Ѻ pseudo-random signal ���͡�Ш�¡��ѧ�ҹ�ͧ watermark bit �������ѭ�ҳ pseudo-random ��ǹ�� ����������¹���¡��� watermark carrier W = {w(i,j)} ������ԡ�좹Ҵ FxM ������� element ���ѡɳФ���� random noise
�Ըսѧ ������ҡ���ҧ WD �ҡ wD = δi + abδiw(i,j) ����Ѻ i = 1, 2, ..., F ��� j = 1, 2, ..., M ����� δi ��� sv �ͧ A, a ��� embedding strength ���� scaling factor ��� b ∈ {-1, 1} �� polarity �ͧ��¹�ӷ��нѧ
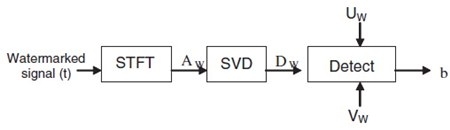
����� ��� WD ���¡���� SVD �ա�� WD = UWDWVWT �ش���� ���ѭ�ҳ���§��ѧ�ҡ�ѧ��¹��ŧ仨ҡ����ŧ inverse STFT �ͧ AW = UDWVT ��鹵������ʴ��ѧ�ٻ
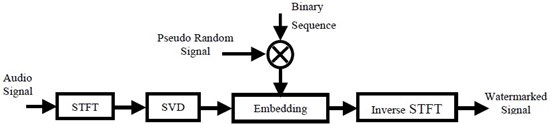
�ҧ��觵�Ǩ�Ѻ��¹�� �ж������բ���������ҹ���������� ���� UW, VW, D ��� key ��������ҧ pseudo-random signal ��鹵��õ�Ǩ�Ѻ��¹�ӡ������繢�鹵����Ѻ�ͧ��ýѧ��¹�� ���ѭ�ҳ���§������Ѻ���ŧ STFT �������ҧ����ԡ�� A' �ҡ��� ��Ш�� A' ���� SVD
����������A' = U'D'WV'T
��� D'W �����ҡ��鹵�¡ SVD �Ѻ UW ��� VW (2 �����ѧ��� �����ҷҧ��觶ʹ��¹�������ǧ˹������) ���� W'D = UWD'WVWT ������ W'D 㹡�äӹdz W' �ҡ��������ѹ�� aW' = D-1(W'D - D)
����� key ���ҧ W (��觨�������ԡ��ͧ watermark carrier �������������) ���Ƿӡ�����º��º���������ͧ W' �Ѻ W
����������W'·W = ∑wijw'ij ����Ѻ�ء��� i, j
��� W'·W > 0 ��Ҩк͡��� b = 1 ���� W'·W ≤ 0 ��Ҩк͡��� b = -1
�ٻ��ҹ��ҧ�ʴ�������ҧ��õͺʹͧ�ͧ detector ��� watermark ������ҧ���ҧ���� 1000 ��� ���͡�õͺʹͧ ��觴� correlation ���� similarity score ��е��˹觷�� 500 ����¹�Ӣͧ��ԧ��ѧ�ҡ�١���� 4 Ẻ ��� (a) copysample, (b) fft_HLPass, (c) flipsample, (d) zerocross
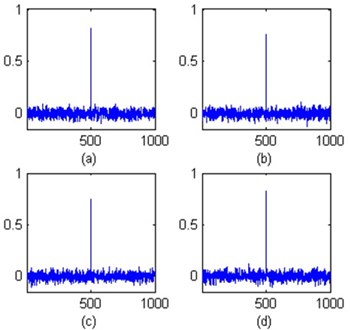
�ѡɳТͧ�ѭ�ҳ�鹩�Ѻ����ѭ�ҳ��ѧ�ҡ�١���շ�� 4 Ẻ��ҧ���ʴ��ѧ�ٻ (a) - (e) ����ӴѺ
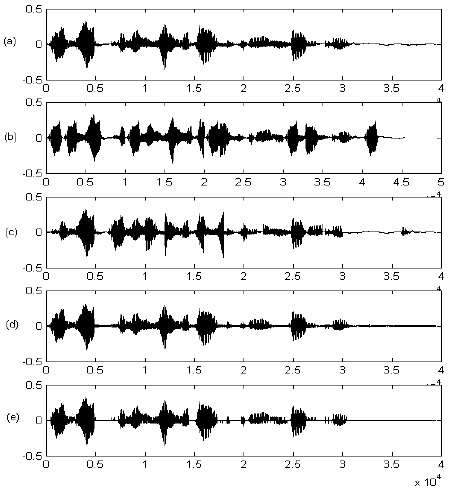
�š�÷��ͧ audibility tests ���ṹ PAQM = 0.01 ��� MOS = 4.7 �����Ҵ��ҡ�Ф�Ѻ ����Ţ������¤�����ҿѧ�¡����ᵡ��ҧ�����ҧ�ѭ�ҳ�鹩�Ѻ�Ѻ�ѭ�ҳ���§��������¹��᷺����͡ �š�÷��ͺ robustness tests ���͡�Ҵ� BER ����ҡ �ٵ��ҧ��� 1 ��м����¹�����º��º BER �����ҧ SVD-based �Ѻ DCT-based �ʴ��ѧ���ҧ��� 2
| Create Date : 25 �ԧ�Ҥ� 2556 | | |
| Last Update : 27 �ԧ�Ҥ� 2556 1:32:24 �. |
| Counter : 1728 Pageviews. |
| |
|
| |
|
|
|
Absolute Thresholds
[��úѭ���������ͧ�����ѧ�֡��]
�����ٴ�֧��������ö�ͧ auditory system 㹡�õ�Ǩ�Ѻ���§�� � ������������Ҿ�Ǵ���������������§����������
absolute threshold ���� �մ�����������Թ���§ ��� �дѺ����ش�ͧ���§������������ö��Ǩ�Ѻ���������������§��� �·���� ������Ը��Ѵ�дѺ����ش�ѧ��������� 2 Ẻ (1) �Ѵ�����ѹ���§���ش㴨ش˹��������������������������⿹�ú�ѹ��� � ������ eardrum ��觴� �Ը��ѴẺ����ͧ�кص��˹����Ѵਹ�Ф�Ѻ ���е��˹觵�ҧ�ѹ�Դ���� �����Ѿ����ᵡ��ҧ�ѹ���ҧ�ҡ������Ѻ�óդ�������٧ �մ����� ���� threshold ����Ѵ�����Ըչ�����¡��� minimum audible presure ���� MAP, (2) �Ѵ�дѺ���§��ѧ�ҡ��Ҽ��ѧ�͡�ҡʹ�����§ (sound field) �·ӡ���Ѵ���ش������繡�觡�ҧ����Тͧ���ѧ ���¡��Ңմ���������Ѵ�����Ըչ����� minimum audible field ���� MAF
���§����������� input ��ǹ�˭��� sinusoidal tone �����ǡ��� 200 ms ��駹�����Ъ�ǧ������Ǣͧ���§�ռŵ���дѺ�մ�����������Թ���§ (������§�ҹ���� 500 ms ������Ǣͧ���§����ռŵ�� threshold) ��ҿ�մ�����������Թ�ѡ���͵������������ͧ sinusoidal tone �ѧ�ٻ
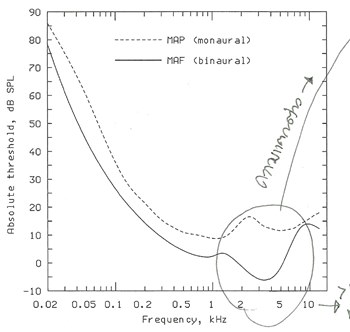
�ҡ�ٻ �����鹻�� MAP ��ǧ��� monaural ���¶֧ �ó������§������ҷ���٢�ҧ���� (��ҹ�ҧ�ٿѧ) ��ǹ MAF ���ѧ�Ѵ�Թ�����ѧ���ٷ���ͧ��ҧ (binaural) ������¹�� ������ͧ�� ��� threshold ��Ŵŧ����ҳ 2 dB SPL �������º�Ѻ�ó������� ��鹡�ҿ��ҡ����������¢ͧ���ѧ���ع��·���ٻ��ԹФ�Ѻ �����˵� ����Ѻ���ѧ��㴤�˹���Ҩ�դ�� threshold �٧���͵�ӡ��ҡ�ҿ�����֧ 20 dB SPL ���ҧ��Ҥ������ ���ѧ�Ѵ����繼��ѧ��軡�������
��ҿ MAP �Ѻ MAF ᵡ��ҧ�ѹ�Ѵਹ㹪�ǧ������� 1.5 - 6 kHz �ѹ����繼Ũҡ�ҡ���١Ѻ��� ���С���ѴẺ˹����ҵ�ͧ�Ѵ�ú��������� ��ǹ����Ѵ�աẺ �ú�ҧ�����ʹ�����§��������١��ͺ�Ӵ����Է�ԾŢͧ�ҡ���١Ѻ��� �ŵ�ҧ�ͧ�дѺ���§ MAP �Ѻ MAF �ʴ��ѧ�ٻ��ҹ��ҧ
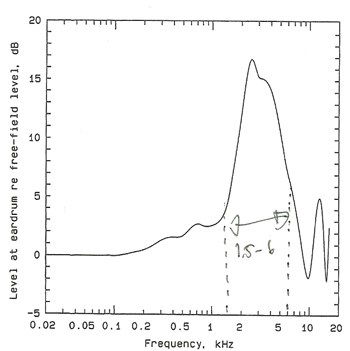
threshold ��� MAP ��� MAF ������������ҧ�Ǵ���Ƿ���������٧�ҡ��е���ҡ ��ǹ˹���Ҩҡ�ѡɳ��Тͧ����觼�ҹ�ѭ�ҳ�ͧ�٪�鹡�ҧ ����觼�ҹ������ҹ��������ҧ �
��������٧�ش�������ö���Թ��������Ѻ���� ��硹���Ҩ���Թ tone ��������٧�֧ 20 kHz ������Ѻ����˭���ǹ�˭� ��� threshold ������������ҧ�Ǵ��������ͤ�������٧���� 15 kHz ��ǹ�ҧ��觤�������� ������������բմ�ӡѴ����� Whittle ��Ф�� (1972) �鷴�ͧ�Ѵ threshold ����Ѻ�������ҡ 50 Hz �֧ 3.15 Hz ����Ҽ��Ѿ�����͡�ҿ������ٵ�����ͧ�Ѻ��觤���������٧���Ҵ� ��й�� ��� 3.15 Hz �մ�����������Թ���դ����������� 120 dB SPL
Johnson �Ѻ Gierke (1974) �͡��� 㹤������·��� � 仹� �������þٴ������Թ���§����������ӡ��� 16 Hz ����ҵ�Ǩ�Ѻ�ѹ��ҡ distortion products (�����ԡ��) ���ǡ�ѹ���ҧ�����ѧ�ҡ��ҹ������٪�鹡�ҧ ���ͨҡ�����蹢ͧ��ҧ��� ���ҧ�á��� �ǤԴ�ͧ Johnson �Ѻ Gierke ���������繷������Ѻ����ùѡ
Moller �Ѻ Pederson (2004) �͡��� �ѭ�ҳ sinusoidal ����������ӡ��� 20 Hz ��鹶١��Ǩ�Ѻ�������ҡ���ҡ����蹢ͧ��ҧ��� ����������ѧ����� ��Ҩ�������Թ���§��ⷹ���������§Ẻ�������ҷ��繷ӹͧ�ŧ ������Թ���§����������ӡ��� 20 kHz ���ѡɳ���������ͧ ����ѹ�Ҩ�١�Ѻ���Ẻ�������֡�֧�����ѹ��� eardrum �ѹ����ԧ ������� 20 Hz �����§�Ѻ����������ش�����������Ѻ��� pitch �ͧ complex sound
����§ҹ�ҹҹ��������� absolute threshold �ͧ���§�������Ѻ��ǧ���ҷ�����§��ҡ� �óշ���ǧ���ҵ�ӡ��� 200 ms ��ҵ�ͧ�����§���ѧ�������ͪ�ǧ����Ŵŧ��������Ǩ�Ѻ���§����� �չѡ�Է����ʵ�����¤�ʹ��֡�Ҵ٤�������ѹ�������ҧ threshold �Ѻ ��ǧ���� �ҹ�ؤ�á �ͧ Hughes (1946) ��� Garner �Ѻ Miller (1947) �͡��� 㹪�ǧ���ҷ������������˹�觹�� �������٢ͧ����Ҩ���� (integrate) ��ѧ�ҹ�ͧ��ǡ�е�鹵�ʹ��ǧ���Ҵѧ������������Ǩ�Ѻ tone ��� � �ѹ��� ��Ҥ�Ժ�¹���繨�ԧ�Ф�Ѻ ��Ҩе�ͧ����� I x t = ��Ҥ���� ����� I ��� ����������§�մ���������Ѻⷹ����ҡ�㹪�ǧ���� t (��蹤�� ��� t Ŵŧ, ��Ҩе�ͧ�Ѵ�� I �ҡ���) ��觤���Ҥ�Ҥ��������繤�Ҥ������������Ѻ (����������¹仵��) �������
㹷ҧ��Ժѵ� ���Ѿ�����ҡѺ��������ѹ�� (I - IL) x t = IL x τ = ��Ҥ���� �ҡ���� ����� IL ��� ��������մ������ͧⷹ�óշ���ժ�ǧ������� Garner �Ѻ Miller �դ�������Ф����������Թ IL ��ҹ�鹷��١�������������ҧ���ԧ��� 㹧ҹ�֡�ҵ������ Zwislocki (1960) Penner (1972) �͡��� �����Դ�ѧ����ǹ�ҨмԴ ��� auditory system ����Ҩ��繵�������ѧ�ҹ��е�� ��Ҩ��繡Ԩ�����ͧ�����ҡ���� ����Ҩ�������ҷ�� auditory system ��Ǩ�Ѻ threshold ��ա�����������§��ǡ��� ���������§�����ǡ��������͡�ʡ�õ�Ǩ�Ѻ����Ҩ��Ẻ��������ͧ���ҡ���� ������ѹ������¡��� multiple looks ������Ѻ���ʹѺʹع�ҡ�š�÷��ͧ�ͧ Viemeister �Ѻ Wakefield (1991)
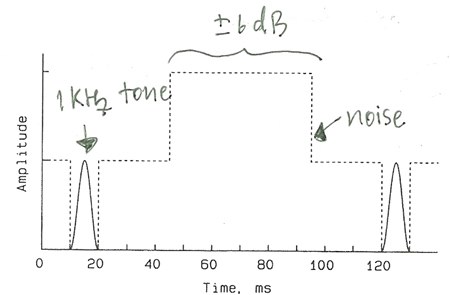
�ǡ���֡�ҡ�õ�Ǩ�Ѻⷹ 1 kHz ��� � ����ҡ� � ��ǧ���ҷ�� 10-20 ms ���/���� 120-130 ms (����ٻ��ҧ��) ����鹻�Ф�� noise ����ǧ���� 50 ms �ç��ҧ��� �дѺ�ͧ�ѹ������¹�ŧ㹪�ǧ ±6 dB �ͧ�����ͺ��÷��ͧ ����� �óշ����ⷹ 2 ⷹ �մ�����������Թ�е�ӡ��ҡó���ⷹ���� (ⷹ���˹�����͵����ѧ ���㴵��˹��) ����ҳ 2.5 dB, ��� auditory system �����ѧ�ҹ�ͧⷹ 2 ⷹẺ������ͧ���������֡���ؤ�á � �ʹ� �մ�����������Թ���ͧ���Ѻ�š�з��ҡ�������¹�дѺ�ͧ noise �ç��ҧ ��š�÷��ͧ��Ѻ����Ңմ������ͧ������Թ����õ���дѺ�ͧ noise �ç��ҧ ��ɮ� temporal integration ������ (I - IL) x t �繤�Ҥ����֧����Ժ�´� � ��ͼš�÷��ͧ��������Ф�Ѻ
�����: �ҧ��ǹ�ҡ����� 2 Absolute Thresholds ˹ѧ��� An Introduction to the Psychology of Hearing (6th Ed) �� Brian C. J. Moore (Emerald, 2012)
| Create Date : 24 �ԧ�Ҥ� 2556 | | |
| Last Update : 24 �ԧ�Ҥ� 2556 10:59:49 �. |
| Counter : 3251 Pageviews. |
| |
|
| |
|
|
|
Subjective Attributes of Sound
[��úѭ���������ͧ�����ѧ�֡��]
�������Ҿٴ�֧���§ �������§����� ����ѡ�к��������§�������ѵ� (attribute) ���ͻ���ҳ 4 ���ҧ ���� �����ѧ (loudness) pitch (�дѺ���§, �������ҧ�Ѻ�дѺ���§㹤������� sound level �Ф�Ѻ, �Ѿ��ѭ�ѵ��Ҫ�ѳ�Ե�ʶҹ �ѭ�ѵ� pitch = �дѺ���§ 㹡�����Ѿ���ѷ��ʵ�� ��觨����¶֧���§�٧ ���§��� �ѹ�������ѹ��Ѻ����ҳ�ҧ����Ҿ��ͤ������ �� sound level �繡���Ѵ�����ѹ���ͤ���������§, 㹺��͡�������� �������� �дѺ���§ = sound level �й�����Ҿٴ�֧ pitch �֧����� �Ե�� ������������дѺ���§����Ѿ��ѭ�ѵ� ����Ҩ�з���駧), timbre (�����, ������§㹤������¤س�Ҿ���§����������§ᵡ��ҧ�ѹ����Ф�������������ͧ�����) ��� ��ǧ�������-��� (duration)
���ѵ����ͻ���ҳ��� 4 ��ǹ���繻���ҳ�ԧ�Ե����� (subjective) ���������Ѻ����ҳ�ҧ����Ҿ�������ö�Ѵ���ԧ�ѵ������� �������Ѻ�����ҡ�������˹����ʴ��ѧ���ҧ��ҹ��ҧ��� ��� "+" �ҡ �����¶֧ ����ҳ�ԧ�Ե����µ�ǹ�鹢������Ѻ����ҳ�ԧ�ѵ��������ҡ

(�����˵� ���������º���§�ҡ�ҧ��ǹ�ͧ 5.8 Subjective Attributes of Sound, The Science of Sound 3rd Ed, �� Rossing, Moore, �Ѻ Wheeler)
| Create Date : 24 �ԧ�Ҥ� 2556 | | |
| Last Update : 24 �ԧ�Ҥ� 2556 9:41:25 �. |
| Counter : 1116 Pageviews. |
| |
|
| |
|
|
|
Orthogonality
[��úѭ���������ͧ�����ѧ�֡��]
���ա˹�� concept ��������� DSP, ����� orthos ���ҡ�ա ���¶֧ ��駩ҡ ���� ����ҡ, 㹷ҧ��Ե��ʵ�� �ǡ���쪹Դ�� a �Ѻ b �е�駩ҡ�ѹ����� inner product a*b′ = 0 �ѧ�ٻ
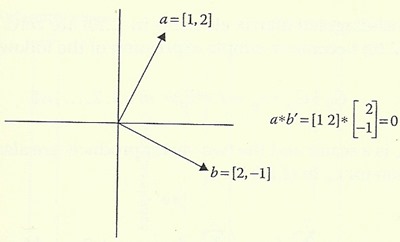
������������������ N �����Ũҡ�ѧ���� 2 �ѧ���� a(t) �Ѻ b(t) ���١����������ҧ��� t = 0, T, ..., (N-1)T �������ҧ�ǡ���� [a0 a1 ··· aN-1] �Ѻ [b0 b1 ··· bN-1] ��������Ѻ orthogonality 㹺�Ժ��ͧ������ N ��ǹ����
����������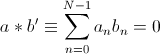
�� an = sin(2πn/N) ��� bn = cos(2πn/N) �繿ѧ���蹷���駩ҡ�ѹ�������������ǡ�������ͧ�� elements ���١�������� step ����� T Ẻ���ǡѹ ��С�÷����������ҿѧ�����˹��駩ҡ�ѹ����ջ���ª��Ф�Ѻ ���ҧ㹡���� least-squares coefficient ��� approximating function f̂(c,nT) ��Сͺ���¿ѧ���� gm �ӹǹ M �ѧ���蹷���駩ҡ�ѹ��Сѹ ��äӹdz��Ч��¢��
�����: ��Ǣ�� 2.3 Orthogonality ˹ѧ��� Digital Signal Processing with Examples in MATLAB �ͧ S. D. Stearns �Ѻ D. R. Hush
| Create Date : 28 �á�Ҥ� 2556 | | |
| Last Update : 28 �á�Ҥ� 2556 20:08:32 �. |
| Counter : 1573 Pageviews. |
| |
|
| |
|
|
|
|

 �ҡ��ͤ�����ѧ����
�ҡ��ͤ�����ѧ���� ���Դ������͡ : 85 �� [
���Դ������͡ : 85 �� [