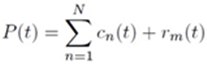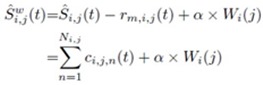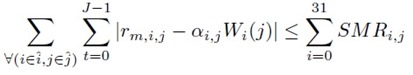EMD and Psychoacoustic Model Based Watermarking for Audio
[��úѭ���������ͧ�����ѧ�֡��]
�����ҵ������ػ�ҡ������㹪������ǡѹ�ͧ Lang Wang, Sabu Emmanue �Ѻ Mohan S. Kankanhalli �ҡ IEEE International Conference on Multimedia and Expo (ICME) �� 2010 ��� Suntec City
�����¹������Ԥ EMD (Empirical Mode Decomposition) 㹡���¡�ѭ�ҳ��Դ multi-component �͡���絢ͧ IMFs (Intrinsic Mode Functions)
����������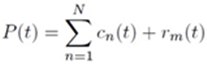
����� P(t) ��� �ѭ�ҳ�����Ҩ��¡ ����¡�� cn ���¶֧ IMF ��Ƿ�� n �ͧ�ѭ�ҳ ��� rm(t) �� final residue ����� monotonic function �͡�ҡ��� �ա���֡�Ҿ���� final residue ���ʶ����Ҿ����ѭ�ҳú�ǹẺ Gauss ��С�úպ�Ѵ MPEG �ٻ��ҹ��ҧ�ʴ�������ҧ N = 8 ������ IMF 8 ���
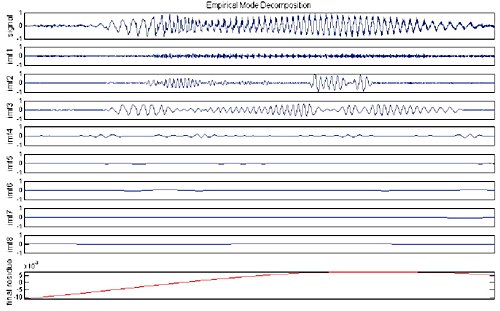
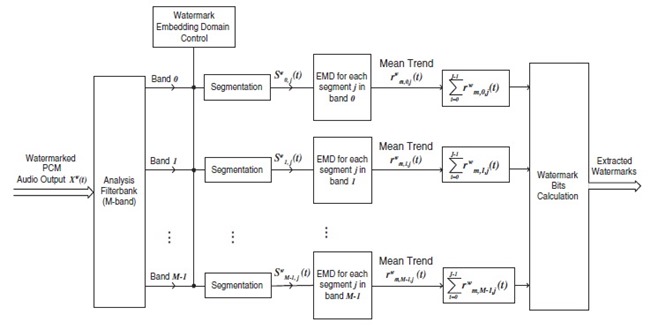
������Ӥѭ�ͧ�Ըչ���� ��ýѧ�������¡�ôѴ�ŧ rm(t) ��Ѻ �Ըա�ýѧ�����ŷ������¹�ʹ���¹�� block diagram ��ѧ�ٻ
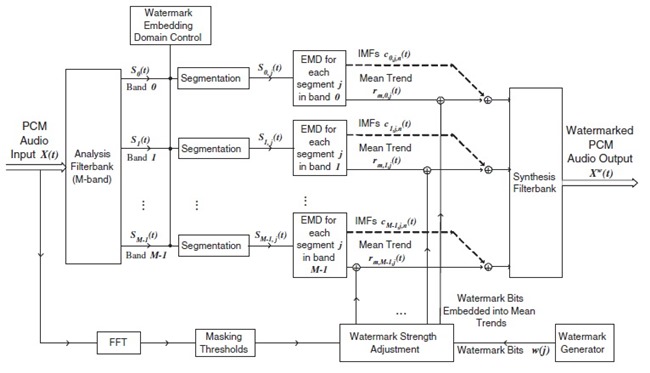
������ҡ���ѭ�ҳ���§ X(t) ������ѭ�ҳẺ PCM �����ѧ analysis filterbank 㹷������ polyphase filterbank (�Դ����� � ������� DFT �����ش������ͧ leakage �Ѻ scalloping loss) ��� filterbank ��ǹ��С�Ш���ѭ�ҳ�鹩�Ѻ�͡�� M = 32 subbands ��� S0(t) ���֧ SM-1(t) ����� ���� subband �ѧ�١���͡�� segment �ա NS segments ������ segment �������� J ��� ��������¹ Si,j(t) ᷹�����ŷ������� segment ��� j �ͧ subband ��� i ��Ҩ��� Si,j(t) = Si(j*J + t) ����� t = 0, 1, ..., J-1 ��� j = 0, 1, ..., NS-1
block �����¹��� Watermark Embedding Domain Control ��� ˹�ҷ��ͧ�ѹ������͡��Ҩнѧ��¹��ŧ� segment �˹ �������Һ͡��� ��ǹ��������������Ѻ��ýѧ��¹�Ӥ�� subband ��� î ��� segment ��� ĵ �й�� segment �����Ҩзӡ�ýѧ��¹�Ӥ�� Ŝi,j(t) := Si,j(t)i∈î, j∈ĵ
���������¡ Ŝi,j(t) �����Ԥ EMD ������������áѺ IMFs �������� rm(t) ��� watermark bit Wi(j) (����դ�� +1 ���� -1) �¡��ź rm,i,j(t) ��� ������� αWi(j) ����᷹ ����� α ��� watermark strength, �����
����������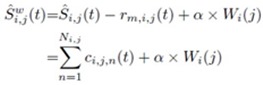
��Ңͧ watermark strength �Ҩҡ����� psychoacoustic model �ӹdz SMR �ͧ���� segment ��������������ѹ�����繨�ԧ
����������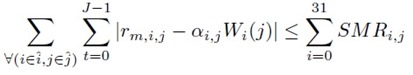
��ѧ�ҡ��� ����ѭ�ҳ��������¹����������� subband ������ѹ���� synthesis filterbank ��������� Xw(t) �ѭ�ҳ���§�������¹�� ���ѹ������鹾Ը� �����¹�͡��� ������Ǣͧ Ŝi,j(t) �ռš�з���� performance �ͧ�к� ��� Ŝi,j(t) ������ �з���� capacity Ŵ ���٤���Ҩе�Ǩ�Ѻ����ᵡ��ҧ�����ҧ�������ѧ�ѧ��¹�����ҡ
block diagram ����Ѻ��кǹ��ô֧��¹���͡���ʴ��ѧ�ٻ��ҹ��ҧ ��ǹ�˭����������Ф�Ѻ ���Шش������ʹ������� rm(t) ��ѧ�ҡ����� rwm,i,j(t) ��ҡ������Ңͧ rwm,i,j(t) ������� t = 0 ���֧ J-1 (�����ҡѺ�ٴ��� ������ rm(t) ��� segment) ��Ҥ�Ҵѧ������ҡ����������ҡѺ 0 ��ҡ�к͡��� w*i,j = 1 ���Ҥ�Ҵѧ����ǹ��¡��� 0 ��� w*i,j = -1 ��Ф�� w* ������ watermark message �����Ҵ֧�͡�Ҩҡ���§ Xw(t)
�š�÷��ͧ �� SDG ≈ -0.15, BER Ẻ����� ≈ 0.0153 ����ͤ�����Ǣͧ segment ����Ѻ�� EMD ����¹�ҡ 32 �֧ 1,024 ������, �����������Ǣͧ segment ��ҡѺ 32 ������������մ��¡�úպ�Ѵ MP3 ��������ѭ�ҳú�ǹẺ Gauss ��� BER ≈ 0.0143 ��� 0.0115 ����ӴѺ
| Create Date : 14 �á�Ҥ� 2556 |
| Last Update : 15 �á�Ҥ� 2556 1:24:27 �. |
|
0 comments
|
| Counter : 2971 Pageviews. |
 |
|
|
|
|

 �ҡ��ͤ�����ѧ����
�ҡ��ͤ�����ѧ���� ���Դ������͡ : 85 �� [
���Դ������͡ : 85 �� [