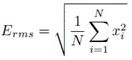Experiments with and Enhancements to Echo Hiding
[��úѭ���������ͧ�����ѧ�֡��]
�����ҵ��� ����ػ�ҡ������㹪������ǡѹ�ͧ Sameer Mitra �Ѻ Sathiamoorthy Manoharan � 4th International Conference on Systems and Networks Communication �� 2009
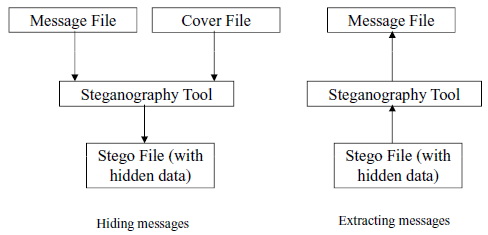
INTRODUCTION�����¹�й��к� steganography �����繽�觫������� (Hiding message) �Ѻ��觴֧�����ŷ��������͡�� (Extracting message) �ѧ�ٻ
�Ԥ���ٴ�֧㹺�������§ 2 �Ԥ��� LSB steganography �Ѻ Echo hiding �����ǹ�ͧ�Ԥ LSB ��¡������ҧ LSB Ẻ���·���ش ��� ����¹�Ե�ش���� (LSB) ��������ŷ��Ы� ����������ҨЫ�����ѡ�� C (���� ASCII �ͧ�ѹ��� 0x43 ���� 01000011 �ҹ 2) ŧ������Ţͧ���§�鹩�Ѻ 8 ������ ��������������� 8 �Ե ���� 11010010, 01001010, 10010111, 10001100, 00010101, 01010111, 00100110 �Ѻ 01000011 ��ҡ�����¹ LSBs �ͧ��� 8 ���������§�����Ңͧ C ���кԵ ���Ѿ������ ��� 11010010, 01001011, 10010110, 10001100, 00010101, 01010110, 00100111 �Ѻ 01000011 ��Ǣմ������͵�Ƿ������¹�ŧ (����������� ����˹�觢ͧ LSBs ������¹�ŧ) �٢ͧ����������ö��Ǩ�Ѻ������ҧ�����ҧ���§�鹩�Ѻ�Ѻ���§���� C ŧ����ǹ�������ҧ�ҡ ������·��Ѵਹ�ͧ�Ԥ LSB ��� �ѹ����ǵ�͡�ô��Թ��û����ż��ѭ�ҳ��ҧ � �� re-sampling, filtering, lossy data transformation ���������٭���¢����ŷ��ѧ�¡������¹ LSB �
�Ԥ Echo ������ǵ�͡�ô��Թ���Ẻ�ѧ���������ҡ��� LSB, ���й�� �������ա�ô��Թ���� � ��¡Ѻ�ѭ�ҳ���§���ѧ���������º�������� ���;ٴ�ա���ҧ��� �������Ҿ�Ǵ����Ẻ closed loop �Ԥ LSB ������ö�֧�������͡���� 100% ��з���Ԥ Echo �� recovery rate ����ӡ��� 100%
�ش���ʧ��ͧ���������͡�ҡ�з��ͧ���ʹٸ����ҵԢͧ�Ԥ Echo ���� �����¹�ѧ�͡����������Ը����� recovery rate �¡����ش����Ẻ self-synchronizing ������¡��� T-code ��觡����Ф�Ѻ��ҡ������ recovery rate �դ����������ǡѺ������� robustness �ͧ�Ԥ Echo hiding
ECHO HIDING & RELATED WORK[����Ѻ��������鹰ҹ�� Echo Data Hiding] ��� x[n] �繤�������Ţͧ�ѭ�ҳ�鹩�Ѻ, α �� echo decay rate �·�� 0 < α < 1, ��� γ ��� echo delay �����Ҩ����� delay �ͧ��� �������˹�������Ѻ��Ң����ŷ������ҫ��� 0 ���� 1
�������ö��Ѻ���������� α �Ѻ γ ��������餹�ѧ������Թ echo ����� recovery rate ������
�ó��Ԥ Echo hiding Ẻ��ԡ ��Ңͧ��������ѧ�ҡ��� echo ���� y[n] = x[n] + αx[n - γ] �ٻ���仹���ʴ�������ҧ original segment (�絢ͧ x[n]) ���� �Ѻ encoded segment (�絢ͧ y[n]) ��� ����ӴѺ
��� γ Ŵŧ �з�����ѭ�ҳ�鹩�Ѻ�Ѻ echo ����ѹ �֧�ش˹�� (����ҳ 1 ms) �٤���ҡ��¡�ͧ�ѭ�ҳ�������͡ ��ǹ α ���繵�ǡ�˹������Ԩٴ�ͧ echo ��觺ҧ�� �ѹ���������������Ԩٴ�ͧ echo ���٧���Ҥ���٧�ش�������Ѻ�� �óա�е�ͧ�� scaling factor ����Ŵ�����Ԩٴ�ͧ�����ŷ�� segment
㹡�ô֧�������͡�� ����� auto-correlation c[n] �ͧ cepstrum: c[n] = F-1(log((F(x))2))
����� x ��� �ѭ�ҳ����������ŧ�����, F(x) ��� ����ŧ Fourier �ͧ x, F-1 ��� ����ŧ Fourier ���ѹ ������ҧ auto-correlation �ͧ�ѭ�ҳ�ʴ��ѧ�ٻ
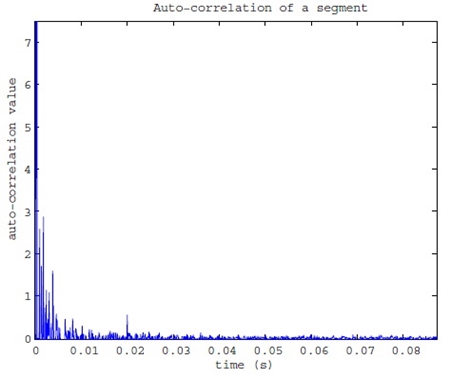
spike ���� �����ū���ⴴ�٧�͡����ѧ�ҡ�����ū��ѹ�á � ������������ γ0 ���ͧ������ γ1 �Թҷ� ��ѡ㹡�ô���Ң����ŷ��������� 0 ���� 1 ������� spikes ��� γ0 �Ѻ γ1 ����ѹ�˹�բ�Ҵ�˭���ҡѹ �ٻ�����繹���繵�����ҧ����� echo delay γ0 = 0.01 �Թҷ� ��� γ1 = 0.02 �Թҷ� ��������� spike ��� 0.02 �Թҷ��˭���ҷ�� 0.01 �Թҷ� �й�� segment �ѧ�����������ͧ�� 1 ������
Oh ��Ф�оѲ���Ԥ echo hiding ������� dual echo kernel ����Ǥ���� echo �ͧ�١ �١˹���繺ǡ �ա�١��ź
����������y[n] = x[n] + α1x[n - γ1] - α2x[n - γ2]
�·���� |γ1 - γ2| ≤ 5 ��ж֧��� dual kernel ���оѲ�Ң�鹨ҡ single kernel Ẻ�á������Ƕ֧ ���õ�Ǩ�Ѻ cepstrum ���ѧ����Ҿ�� ����� Kim ��Ф�Ш֧���ʹ� Backward & Forward kernel ������� recovery rate �٧�������
����������y[n] = x[n] + αx[n - γ] - αx[n + γ]
�մ�ӡѴ��ѡ�ͧ�Ԥ echo hiding ��� �ѹ�繡���ҡ���Ы����������ǹ�����º�ͧ���§ ������Ҩ����Թ echo ������������§ �֧���ա�þѲ�� adaptive echo hiding ����Ǥ�� �ա������¹�ŧ��� decay rate �����������Ѻ���� segment 㹡�á�˹�����٧�ش�ͧ decay rate ������� segment ��� ���������ҡ��äӹdz��ѧ�ҹ�ѭ�ҳ�ͧ segment ����ٵ�
����������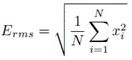
��Ҿ�ѧ�ҹ���ж١������º��º�Ѻ threshold ����ҨЫ�������ŧ� segment ����վ�ѧ�ҹ�٧���� threshold ��ҹ�� ���Ǩ֧�� gain control ���ͻ�Ѻ��� decay rate ���ͷ���� echoes �����ӡ��� mask (������������ҡ��������Թ echo) �����¹�͡���㹡�äӹdz mask �����Ը���Ը�˹��� 3 �Ըյ��仹�� (1.) Signal Dependent Attenuation: �óչ�� mask ���� original host signal �����ѭ�ҳ�鹩�Ѻ ������� segment �л�Ѻ decay rate �Ẻ������� echoes ��ͺ�����������ӡ����ѭ�ҳ�鹩�Ѻ, (2.) Psychoacoustic Model: mask ��ӹdz����������������Ѻ 26 critical bands ������Ţͧ�ѹ������Ф�Ѻ �������� segment �л�Ѻ��� decay rate �Ẻ�������ͧ���Сͺ�������ͧ echo ���ҹ 1 kHz �֧ 5 kHz �����ӡ��� mask, (3.) Perceptual Filter: maks �١�ӹdz������������� perceptual filter ����ԧ����Ѻ LPC (Linear Predictive Coding) ��觷����»��ѭ�ҳ�鹩�Ѻ�����ѧ perceptual weighting filter
㹡ó� adaptive ��� �����ŵ��˹觷�����¹�� (��������� segment �˹����ա�ýѧ��������¹��ŧ�) �е�ͧ�١�ѹ�֡������� recovery
T-CODEST-code ��� �����¢ͧ�� Huffman code �������������� �Ըա�����ҧ T-code ������кǹ��÷�����¡��� T-augmentation ������ҡ�絢ͧ T-code ���ҧ���·������ alphabets 㹡ó� binary alphabet �絴ѧ����ǡ��� S = {0, 1} ��ҵ�ͧ��� code set ����˭��� ��ҡ����Ըյ��仹�����Ƿӫ��������� � ��Ѻ ��� (1.) ź��Ҫԡ˹�觵���͡�ҡ�� (2.) ����Ҫԡ��Ƿ��ź�͡�ҡ���� prefix �Ѻ��Ҫԡ�ͧ�絵������� ����������Ҫԡ�����������������Ңͧ��
������ҧ �ҡ S = {0, 1} ���������͡ 0 �� prefix ��ҡ���� S(0) = {1, 00, 01} �дѺ�Ѵ�� ���������͡ 1 �� prefix ��ҡ���� S(0,1) = {00, 01, 11, 100, 101} ������дѺ���ǡѹ��� ������͡ 01 �� prefix ����� S(0,01) = {1, 00, 011, 0100, 0101} ��觡�Ѵਹ��� �������͡ prefix ������͡��� code word ������ � ������� codes � code set �ش���¨������ �
�ӹǹ��Ҫԡ��� T-code ����дѺ T-augmentation ��ҡѺ n ��� 2n + 1
��ʹբͧ T-code ����ѹ�з� self-synchronize �����ҧ��� decode �ѧ��� ����ͺҧ�Ե�Դ�ջѭ�Ң����� stream ����������Ẻ T-code ��Ƕʹ���ʨз� syncronize �����ѵ��ѵ� �ٵ�����ҧ�Ф�Ѻ ����������Ҩ��觢�ͤ��� helloworld! ��������ѡ�� 8 ��� ��� {h, e, l, o, w, r, d, !} ������е���դ������ {1, 1, 3, 2, 1, 1, 1, 1} ����ӴѺ ��ҵ�ͧ���� T-code ��� T-augmentation �дѺ 3 (�����дѺ 2 �յ���ѡ��������� 5 ��� �������) ����� S(0,1,00) = {01, 11, 100, 101, 0000, 0001, 00100, 00101} �����������ҧ���ҹء���ѧ���ҧ
����������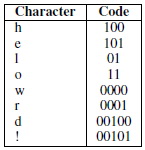
����� helloworld! = 100.101.01.01.11.0000.11.0001.01.00100.00101 ����·���� �����Դ��Ҵ���Դ����� 3 Ẻ ��� �ҧ�Ե���� (bit loss), �ҧ�Ե����¹��� (bit inversion) ��кҧ�Ե�Թ����� (bit addition)
1. Bit loss: �������ҺԵ���մ��������� 100.101.01.01.11.0000.11.0001.01.00100.00101 �й�鹺Եʵ���������� 10010101011100001001010010000101 ��е�� decoder �жʹ������ 100.101.01.01.11.0000.100.101.00100.00101 = hellowhed! (�����˵�: ������ҧ������ç�Ѻ������Ф�Ѻ ���е�����������仢մ�����Դ��� ��µ����� �ʹ���ʵ�����մ�Դ���������)
2. Bit inversion: �������ҺԵ���մ���������¹��� �ҡ 100.101.01.01.11.0000.11.0001.01.00100.00101 �� 1001010101110001100001010010000101 ��Ƕʹ���ʨжʹ�� 100.101.01.01.11.0001.100.00101.00100.00101 = hellorh!d!
3. Bit addition: �������ҵ�Ƿ��մ������ͺԵ������������ 100.11101.01.01.11.0000.11.0001.01.00100.00101 ���� 100111010101110000110001010010000101 ��Ƕʹ���ʡ����ҹ����� 100.11.101.01.01.11.0000.11.0001.01.00100.00101 = hlelloworld!
�����¹���� T-code ����������ʢ����š��нѧŧ��ŧ �ҧ����Ѻ���ͧ�ʹ���� T-code ����ҹ �͡�ҡ��� ���ҹء�������������ʨе�ͧ�繷�����ѹ����ͧ����
EVALUATION�����¹���ŧ������ѡɳдѧ��� 8 �Ե/������, 44 kHz ��ͧ���� WAV file ��Т�ͤ���������� "Hello World!" �ŧ������դ������ 60 �Թҷ� �١���� segment ���� 0.25 �Թҷ� ���������ö�����������٧�ش 60/0.25 = 240 �Ե �ŧ��Ъ�Դ�ͧ�ŧ����鷴�ͺ�ʴ��ѧ���ҧ ���ŧ��͡�Ѻ��ͻ���վ�ѧ�ҹ�ѭ�ҳ�٧ ��з���ŧ����ŧ���ͤ����ԡ���ջ���ҳ��ҧ � ��ǹ���§�ٴ����ժ�ǧ��ҧ�ҡ���վ�ѧ�ҹ����ش
����������
㹡���Ѵ recovery rate �����Ңͧ Bit Recovery Rate (BRR) ������¶֧ �Ѵ��ǹ�ͧ�Ե�������ö��ҹ�����ҧ�١��ͧ �Ѻ Character Recovery Rate (CRR) ������¶֧ �Ѵ��ǹ�ͧ����ѡ�÷����ҹ�����ҧ�١��ͧ �����¹�������÷��ͧ�á���¡�ô���Ҫ�Դ�ͧ�ŧ�ռŵ�� RR ������� �¡�˹� α = 0.8, γ0 = 0.001 ��� γ1 = 0.0012 �ŷ����ѧ���ҧ
����������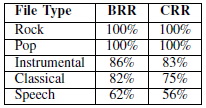
���������§����ժ�ǧ��º�ҡ���;�ѧ�ҹ��Ө��� RR ���
����ҴټŢͧ γ ��� RR ������� α = 0.8 ����� �ŷ�����ʴ��ѧ���ҧ (��� BRR, CRR �ӹdz������������Ţ��Ե�ͧ�ء�ŧ)
����������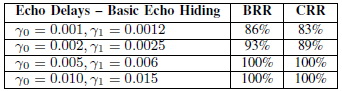
�����ҡ���� γ ����դ���ҡ ����� RR �٧ ���й�� ��������ѧ����ö���Թ���§ echo
����� �ټŢͧ α ��� RR ������� γ0 = 0.001 ��� γ1 = 0.0012 ����� �ŷ�����ʴ��ѧ���ҧ
����������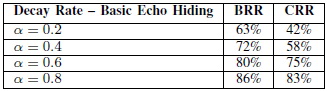
��仵���Ҵ ��� ��� α �դ���٧, RR ���٧��� ���з�� α ��� ��Ҩ��¡�����ҧ echo �Ѻ noise �������͡
����� �����¹�ͧ����¹����Ԥ echo hiding Ẻ��ҧ � ���������Ẻ��� RR �����ҧ�ú�ҧ ����� α = 0.8, γ0 = 0.001 ��� γ1 = 0.0012 ����� ���Ѿ�������ʴ��ѧ���ҧ
����������
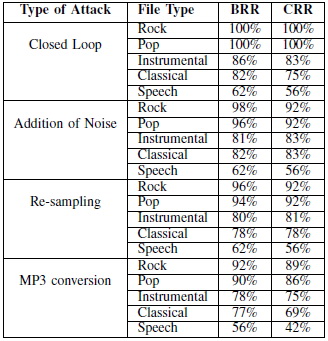
����� �繡�÷��ͺ robustness ���ա������ 3 Ẻ ��� (1) ���� Gaussian white noise ����� SNR = 30 dB, (2) ����¹ sampling rate �ҡ��� 44.1 k �� 22.05 k ������꾡�Ѻ�� 44.1 k �����ŵ���Թҷ�, (3) �ŧ WAV �� 128 kbps MP3 �����ŧ��Ѻ�� WAV
�Ũҡ���ҧ���仹���ʴ���������Ҫ�Դ�ͧ�ŧ �Ѻ RR ����ͼ�ҹ�������Ẻ��ҧ � ���� �դ�������ѹ��ѹ���ҧ�� ��ǹ���ҧ�Ѵ��ʴ� RR ��������ԤẺ��ҧ � ��÷��ͧ�������ӷ�� α = 0.8, γ0 = 0.001 ��� γ1 = 0.0012
����������
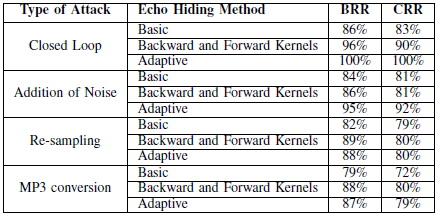
����������
����� �����¹���ͧ�Ѳ���Ԥ echo hiding ��������� T-code �����份ѧ��ŧ ����Ѿ��ѧ���ҧ
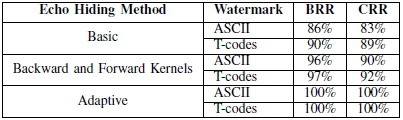
����������
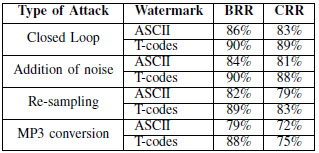
������ RR ������鹹Ф�Ѻ ����������ҡ����� �͡�ҡ��� 㹵���¼����¹�ѧ����Ƕ֧��ʹբͧ����� T-code �ա 2 ���ҧ��� ��ӹǹ�Ե���¡��� ASCII ��ҡѺ���� capacity �Ѻ �Ҩ�繡������ security �㹵�� ���м�������������ҡ��ѧ�� T-code
| Create Date : 15 �Զع�¹ 2556 |
| Last Update : 16 �Զع�¹ 2556 17:30:33 �. |
|
0 comments
|
| Counter : 1822 Pageviews. |
 |
|
|
|
|

 �ҡ��ͤ�����ѧ����
�ҡ��ͤ�����ѧ���� ���Դ������͡ : 85 �� [
���Դ������͡ : 85 �� [