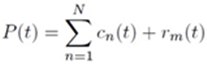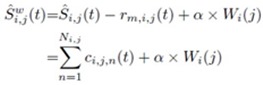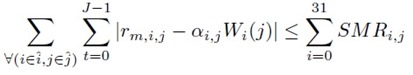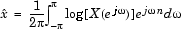|
EMD and Psychoacoustic Model Based Watermarking for Audio
[��úѭ���������ͧ�����ѧ�֡��]
�����ҵ������ػ�ҡ������㹪������ǡѹ�ͧ Lang Wang, Sabu Emmanue �Ѻ Mohan S. Kankanhalli �ҡ IEEE International Conference on Multimedia and Expo (ICME) �� 2010 ��� Suntec City
�����¹������Ԥ EMD (Empirical Mode Decomposition) 㹡���¡�ѭ�ҳ��Դ multi-component �͡���絢ͧ IMFs (Intrinsic Mode Functions)
����������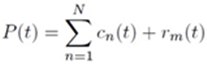
����� P(t) ��� �ѭ�ҳ�����Ҩ��¡ ����¡�� cn ���¶֧ IMF ��Ƿ�� n �ͧ�ѭ�ҳ ��� rm(t) �� final residue ����� monotonic function �͡�ҡ��� �ա���֡�Ҿ���� final residue ���ʶ����Ҿ����ѭ�ҳú�ǹẺ Gauss ��С�úպ�Ѵ MPEG �ٻ��ҹ��ҧ�ʴ�������ҧ N = 8 ������ IMF 8 ���
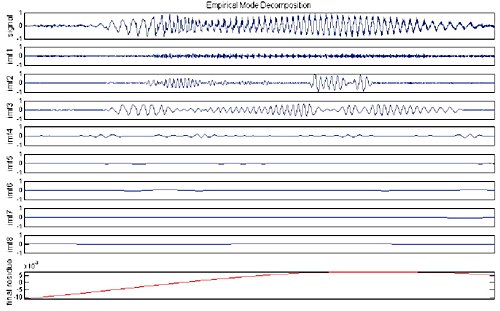
������Ӥѭ�ͧ�Ըչ���� ��ýѧ�������¡�ôѴ�ŧ rm(t) ��Ѻ �Ըա�ýѧ�����ŷ������¹�ʹ���¹�� block diagram ��ѧ�ٻ
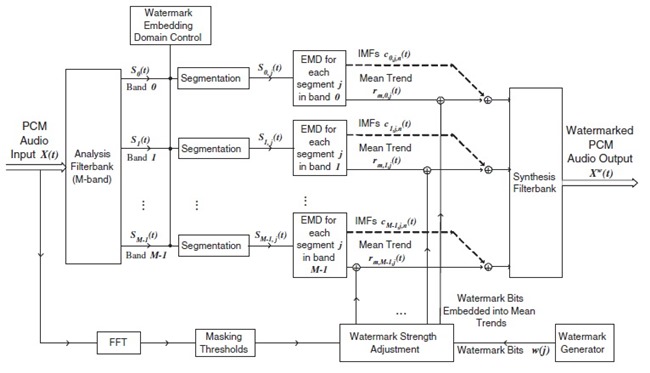
������ҡ���ѭ�ҳ���§ X(t) ������ѭ�ҳẺ PCM �����ѧ analysis filterbank 㹷������ polyphase filterbank (�Դ����� � ������� DFT �����ش������ͧ leakage �Ѻ scalloping loss) ��� filterbank ��ǹ��С�Ш���ѭ�ҳ�鹩�Ѻ�͡�� M = 32 subbands ��� S0(t) ���֧ SM-1(t) ����� ���� subband �ѧ�١���͡�� segment �ա NS segments ������ segment �������� J ��� ��������¹ Si,j(t) ᷹�����ŷ������� segment ��� j �ͧ subband ��� i ��Ҩ��� Si,j(t) = Si(j*J + t) ����� t = 0, 1, ..., J-1 ��� j = 0, 1, ..., NS-1
block �����¹��� Watermark Embedding Domain Control ��� ˹�ҷ��ͧ�ѹ������͡��Ҩнѧ��¹��ŧ� segment �˹ �������Һ͡��� ��ǹ��������������Ѻ��ýѧ��¹�Ӥ�� subband ��� î ��� segment ��� ĵ �й�� segment �����Ҩзӡ�ýѧ��¹�Ӥ�� Ŝi,j(t) := Si,j(t)i∈î, j∈ĵ
���������¡ Ŝi,j(t) �����Ԥ EMD ������������áѺ IMFs �������� rm(t) ��� watermark bit Wi(j) (����դ�� +1 ���� -1) �¡��ź rm,i,j(t) ��� ������� αWi(j) ����᷹ ����� α ��� watermark strength, �����
����������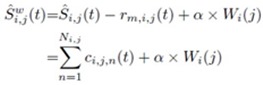
��Ңͧ watermark strength �Ҩҡ����� psychoacoustic model �ӹdz SMR �ͧ���� segment ��������������ѹ�����繨�ԧ
����������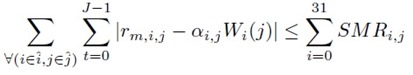
��ѧ�ҡ��� ����ѭ�ҳ��������¹����������� subband ������ѹ���� synthesis filterbank ��������� Xw(t) �ѭ�ҳ���§�������¹�� ���ѹ������鹾Ը� �����¹�͡��� ������Ǣͧ Ŝi,j(t) �ռš�з���� performance �ͧ�к� ��� Ŝi,j(t) ������ �з���� capacity Ŵ ���٤���Ҩе�Ǩ�Ѻ����ᵡ��ҧ�����ҧ�������ѧ�ѧ��¹�����ҡ
block diagram ����Ѻ��кǹ��ô֧��¹���͡���ʴ��ѧ�ٻ��ҹ��ҧ ��ǹ�˭����������Ф�Ѻ ���Шش������ʹ������� rm(t) ��ѧ�ҡ����� rwm,i,j(t) ��ҡ������Ңͧ rwm,i,j(t) ������� t = 0 ���֧ J-1 (�����ҡѺ�ٴ��� ������ rm(t) ��� segment) ��Ҥ�Ҵѧ������ҡ����������ҡѺ 0 ��ҡ�к͡��� w*i,j = 1 ���Ҥ�Ҵѧ����ǹ��¡��� 0 ��� w*i,j = -1 ��Ф�� w* ������ watermark message �����Ҵ֧�͡�Ҩҡ���§ Xw(t)
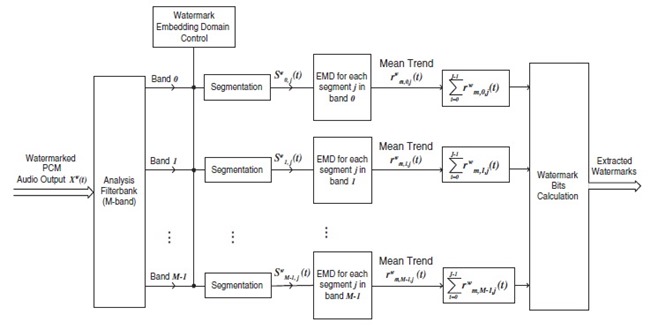
�š�÷��ͧ �� SDG ≈ -0.15, BER Ẻ����� ≈ 0.0153 ����ͤ�����Ǣͧ segment ����Ѻ�� EMD ����¹�ҡ 32 �֧ 1,024 ������, �����������Ǣͧ segment ��ҡѺ 32 ������������մ��¡�úպ�Ѵ MP3 ��������ѭ�ҳú�ǹẺ Gauss ��� BER ≈ 0.0143 ��� 0.0115 ����ӴѺ
| Create Date : 14 �á�Ҥ� 2556 | | |
| Last Update : 15 �á�Ҥ� 2556 1:24:27 �. |
| Counter : 2982 Pageviews. |
| |
|
 |
|
|
|
Arnold Transform (Arnold's Cat Map)
[��úѭ���������ͧ�����ѧ�֡��]
����ŧ�����Ŵ�ͧ�Ҿ 2 �Ե� ��Ҵ N x N ������ҡ
�����
����� (x,y) ᷹�ԡѴ�ͧ�ԡ�������ԡ���Ҿ���ŧ �� x, y ∈ {0, 1, ..., N-1} ��� (x',y') �繾ԡѴ�ͧ�ԡ������ԡ���Ҿ��ѧ����ŧ �ѧࡵ mod N ���¶֧ x' �Ѻ y' �١���Թ�������� modular N ������� x' �Ѻ y' ����㹪�ǧ 0 �֧ N-1
����ŧ�����Ŵ����ѡɳ��繤Һ ��觨��Ѻ��Сѹ����Ҿ scrambling �ж١�ӡ�Ѻ����������� ����Ѻ�Һ��� N ��ҧ � �ѹ�ʴ��ѧ���ҧ
�����
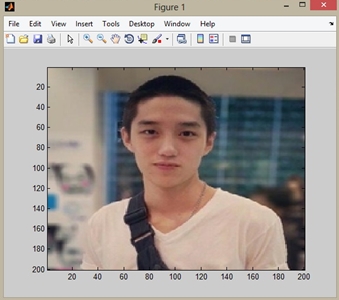
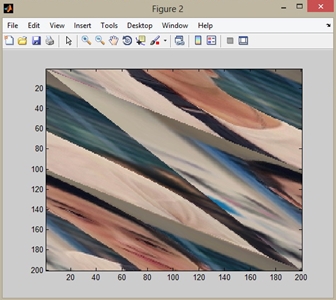
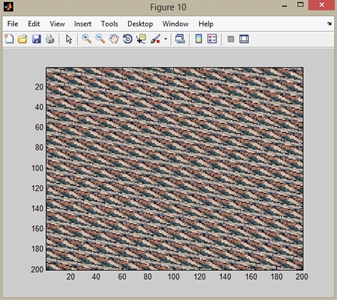
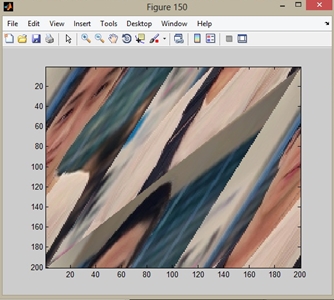
������ҧ Figure 1: �Ҿ�鹩�Ѻ, Figure 2: �ŧ 1 �ͺ, Figure 10: �ŧ 9 �ͺ, Figure 150: �ŧ 149 �ͺ ��� Figure 151: �ŧ 150 �ͺ �ѧ�ٻ
�鴴��� MATLAB
�����
�����
�����: �ٻ����áѺ���ҧ����Ҩҡ�������ͧ K. Ren et al ����ͧ Large Capacity Digital Audio Watermarking Algorithm Based on DWT and DCT (2011 ICMSEEC), ��ǹ source code �Ѵ�ŧ�ҡ�鴢ͧ�Ҩ���� Charles Collins, �Ҿ��ͧ��� ���� �ҡ fc-page �� fb ��л�Ѻ����բ�Ҵ 200 x 200 �ԡ��
| Create Date : 05 �á�Ҥ� 2556 | | |
| Last Update : 5 �á�Ҥ� 2556 23:08:45 �. |
| Counter : 2783 Pageviews. |
| |
|
| |
|
|
|
What is a Cepstrum?
[��úѭ���������ͧ�����ѧ�֡��]
complex cepstrum ����Ѻ�ӴѺ x �ӹdz���¡���� complex natural logarithm �ͧ����ŧ��������ͧ x ������Ҽ��Ѿ���������ŧ�Թ�����ʿ��������ա��
����������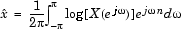
������ҧ�� complex cepstrum 㹡���ʴ� echo ������ҡ���ҧ s1 ��� sine wave ������� 45 Hz ���١�����駷�� 100 Hz �ҡ������ echo ����բ�ҴŴŧ����˹��ŧ� ���� delay time ��ҡѺ 0.2 s ������ s2
���������� peak ��� 0.2 s � complex cepstrum �ѹ����ʴ��֧ delay time �ͧ echo ��ҡѺ 0.2 s
�����: mathworks
| Create Date : 21 �Զع�¹ 2556 | | |
| Last Update : 21 �Զع�¹ 2556 15:41:02 �. |
| Counter : 1889 Pageviews. |
| |
|
| |
|
|
|
Audio Watermarking of Stereo Signals Based on Echo-Hiding Method
[��úѭ���������ͧ�����ѧ�֡��]
�����ҵ������ػ�ҡ������㹪������ǡѹ�ͧ Foo Say Wei �Ѻ Dong Qi �ҡ ICICS 2009
�������ҷ� echo hiding ��Ҩ��� delay time �ͧ echo 2 ������ͽѧ������ "0" �Ѻ "1" �躷������� �����¹�ʹ��Ըշ���� delay time ����§������� ��� 0.001 s �Ѻ decay rate = 0.4 㹡�ýѧ������ŧ��ŧẺ stereo (�� 2 channels) ����ѵ�������� 44.1 kHz ����觽ѧ�Ե�з� ���� 0.01 s ������͡�ѧ������� non-silent segment ��蹤�� �ա�äԴ��ѧ�ҹ�ͧ���з��� ���ǽѧ������ŧ㹷�����վ�ѧ�ҹ�Թ��� threshold ����˹����ҧ��� �Ԥ�����ʹ�㹡�äӹdz��ѧ�ҹ�ͧ�����¹��� ����з� (0.01 s) ���ѧ���͡�� 3 ������ ���Ǥӹdz��ѧ�ҹ�ͧ���з����� ����շ�����㴷�����˹�觷���ѧ�ҹ��ӡ��� threshold ��ж����ҷ�� segment (3 ������) �� non-silent segment
�չ�� ���ͧ�ҡ�� delay time ������� �����Ը��¡�Ե 0 �Ѻ 1 ���ҧ��, ��ԡ�������¹����������� echo �١�ѧ��� channel �˹ �� ������ѭ�ҳ��ͧ��⾧���� ������ҺԵ 0 �������ѭ�ҳ��ͧ��⾧��� �����ҺԵ 1
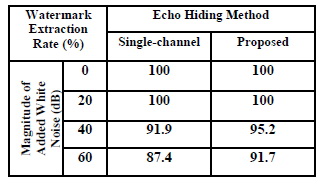
�����¹���º��º�����ҧ single-channel �Ѻ�Ըշ���ʹ��´����º��º��� extraction rate (%) ����ͼ�ҹ������� 3 Ẻ ��� ��� white noise, ����¹ sampling rate �繤��㴤��˹�������ŧ��Ѻ�� 44.1 kHz, �Ѻ��úպ�Ѵ�� MP3 �����ŧ��Ѻ���� WAV �ŷ�����ʴ��ѧ���ҧ �������ҡóչ�� ����Է���Ҿ���ա��� (extraction rate ����٧����) �����繷��Ҵ�����������ǹФ�Ѻ
���������� 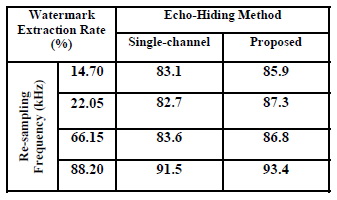
����������
| Create Date : 20 �Զع�¹ 2556 | | |
| Last Update : 12 �á�Ҥ� 2556 21:35:46 �. |
| Counter : 974 Pageviews. |
| |
|
| |
|
|
|
Experimental Research on Parameter Selection of Echo Hiding in Voice
[��úѭ���������ͧ�����ѧ�֡��]
�����ҵ������ػ�ҡ������㹪������ǡѹ�ͧ Li Li �Ѻ Ya-Qi Song �ҡ 8th International Conference on Machine Learning and Cybertics, Baoding, 12-15 July 2009
�����¹�͡��� ���ͧ�ҡ�ѧ��������֡���Ըա�����͡����������������Ԥ echo hiding �Ҩ֧��ӡ�÷��ͧ�����ʹͤ�Ҿ������������������ ������¶֧���������������� recovery rate �դ���٧ ����Ѻ�Ԥ single echo hiding (��������´����ǡѺ�Ԥ Echo hiding �Ҵ���㹺��͡���˹�� �����¹������� 2 � �� Echo Data Hiding)
��÷��ͧ�����§�ٴ�ӹǹ 20 ��Ի ���������� 16 �Ե㹿������ WAV ������ѵ������������ҧ (sampling rate) ��ҡѺ 8 kHz, 16 kHza ��� 22.05 kHz �����ŷ����ѧ�� text �½ѧ���кԵŧ� segment ����դ������ 0.1 s �ͧ��Ի ����� Recovery Accuracy (RA) �繵���Ѵ ��
����������RA = [(�ӹǹ�Ե���ʹ���������ҧ�١��ͧ)/(�ӹǹ�Ե���ѧ)] x 100%
��÷��ͧ�á���͡�� α = 0.4 (decay rate = 0.4) ������ Gruhl ��Ф�����ʹ������Ҥ�� decay rate ������������� 0.3 < α < 0.4 �ش���ʧ��ͧ��÷��ͧ������Ҥ�������ѹ�������ҧ RA �Ѻ delay time (�ѭ��ѡɳ������������� d0 ����Ѻ delay time �ͧ kernel ���ѧ�Ե 0 ��� d1 ����Ѻ�ѧ 1) ���Ѿ��ҡ��è��ͧ�ʴ��ѧ�ٻ a) - c) �������
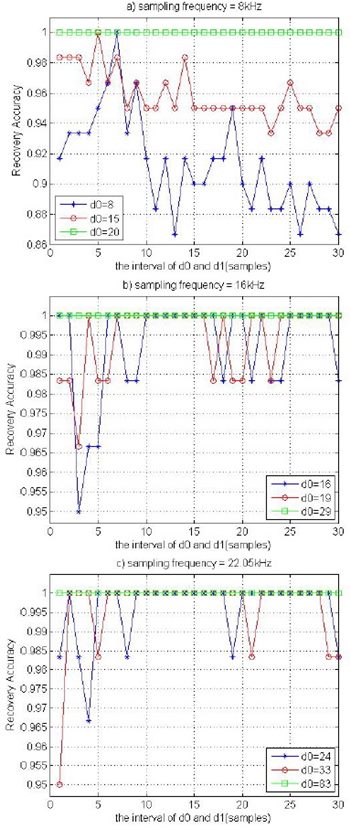 | 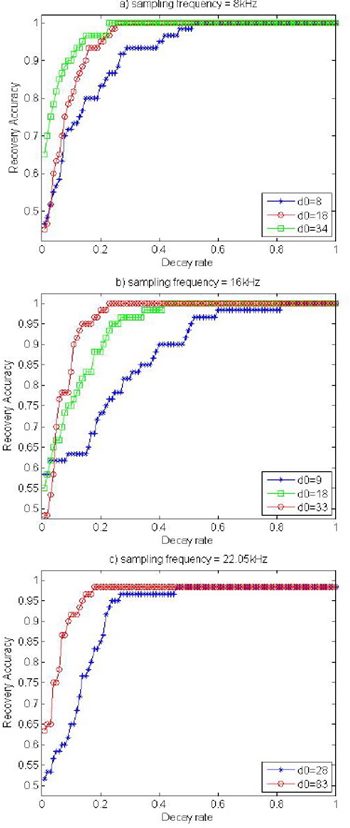 |
�ٻ a) - c) ��� �ó� sampling rate = 8 kHz, 16 kHz, 22.05 kHz ����ӴѺ ������ҧ�ٻ a) d0 = 8 ������ (���� 1 ms) ������ ��� d0 �����ҡ��� �š�з��ͧ |d0 - d1| ��� RA Ŵŧ ����Ԩ��������ػ�ѧ���
1. ��������駷�� 8 kHz, ��� d0 ��������������㹪�ǧ 18-40 ������ (2.25-5 ms) ��Ңͧ d1 ����˹� ���� d0 ����㹪�ǧ 8-18 ������ ��Ңͧ |d0 - d1| ������������ҧ 1-10 ������
2. ��������駷�� 16 kHz, ��� d0 ��������������㹪�ǧ 23-80 ������ (1.44-5 ms) ��Ңͧ d1 ����˹� ���� d0 ����㹪�ǧ 16-22 ������ ��Ңͧ |d0 - d1| ����ҡ���� 10 ������
3. ��������駷�� 22.05 kHz, ��� d0 ��������������㹪�ǧ 31-102 ������ (1.41-4.63 ms) ��Ңͧ d1 ����˹� ���� d0 ����㹪�ǧ 22-31 ������ ��Ңͧ |d0 - d1| ����ҡ���� 10 ������
������繡�÷��ͧ�����Ҥ�������ѹ�������ҧ RA �Ѻ decay rate ��觼��Ѿ���ʴ��ѧ�ٻ a) - c) ������ ���Ѿ���ѹ�������������� ��� delay time ����㹪�ǧ��������ǵ����� 1. - 3. ��� RA > 0.99 ����� α > 0.2 ��蹤�� �ҡ���͡ α ������������ҧ 0.2 �Ѻ 0.4 ��� delay time ���������ʹ�� ���� RA ����٧
| Create Date : 20 �Զع�¹ 2556 | | |
| Last Update : 20 �Զع�¹ 2556 21:13:58 �. |
| Counter : 1198 Pageviews. |
| |
|
| |
|
|
|
|

 �ҡ��ͤ�����ѧ����
�ҡ��ͤ�����ѧ���� ���Դ������͡ : 85 �� [
���Դ������͡ : 85 �� [