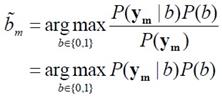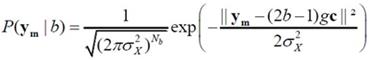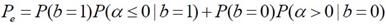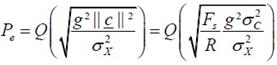|
|
|
Pitch and Periodicity Coding
[��úѭ���������ͧ�����ѧ�֡��]
�����ҵ������ػ�ҡ����� 7 㹪������ǡѹ ˹ѧ��� The Sense of Hearing �� Christopher J. Plack ��������´����� 2 - 6 ����ҡ��úѭ���������ͧ�����ѧ�֡�ҵ���ԧ���ҧ����Ѻ
����繢ͧ����� ��� �к�����Ѻ������§����ö���ʹ���д֧����������ǡѺ�����繤Һ (periodicity) �ͧ���§�����ҧ�� ��觡���Ѻ��������繤Һ�ͧ���§���Ф�Ѻ ������ѹ��Ѻ����ҳ���˹�觷�����¡��� pitch �ӹͧ���ǡѺ��� �����ѹ-�����ѧ �����ѹ�繻���ҳ�ҧ����Ҿ�������ѹ��Ѻ�����ѧ����繻���ҳ�������Ѻ����������������Թ���§ �� subjective ��Ф��ͧ pitch ����繻���ҳ�ҧ����Ҿ���� �������
Pitch����������Թ���§����դ��������Űҹ (fundamental frequency) ���㴤��˹�� ����Ҩ���Ѻ���֧ pitch �������ѹ��Ѻ���������Űҹ��� ��蹤�� �к��е�ͧ�դ�������ö㹡���кؤ��������Űҹ�ͧ���§
������ͧ pitch �������¹��Ф�Ѻ pitch ���ѡɳТͧ����Ѻ������§������ᵡ��ҧ�ͧ�ѹ����ѹ��Ѻ�ӹͧ�ŧ �ٴ�ա���ҧ˹����� ���§㴡������������Ѻ�������ǡѺ pitch (���� ���§㴡����������Ѻ��� pitch ��) ���§��� ������ö��������ҧ�ӹͧ�ŧ��������¹�ѵ�ҡ�ë�ӤҺ�ͧ���§ �������§��������Դ����Ѻ��� pitch ��ҡ�������§���价��繷ӹͧ�ŧ����� �� �س�������ö�����§����������٧���� 5 kHz ���͵�ӡ��� 25 Hz ����ҧ�ӹͧ�ŧ�� ������� ���§㹪�ǧ 25 Hz �֧ 5 kHz ��ҹ�鹷�������Դ pitch ��ǹ���§����դ����������͡��ǧ��� ��������Դ����Ѻ��� pitch
�ٻ��ҹ��ҧ�ʴ� waveform �Ѻ������ͧ���§ 3 ���§ ���§�á ���ش�� pure tone ���§����ͧ�Ѻ����� complex tone ���������§�� pitch ���ǡѹ ���з��������§�դ��������Űҹ���ǡѹ (���������Űҹ�繵�ǡ�˹� pitch) ���������Űҹ�ͧ pure tone ��� �������ͧ pure tone ����Ѻ���������Űҹ�ͧ complex tone ����ѵ�ҡ�ë�ӤҺ�ͧ waveform

�Ӷ������� ��������٧�ش��е���ش (���ͤ��������Űҹ�٧�ش��е���ش) ����÷������ö������Դ pitch 㹡óբͧ pure tone �ա���֡�Ңͧ Attneatve �Ѻ Olson (1971) ����� ����������٧���� 4 kHz - 5 kHz �������ö�������ҧ�ӹͧ�ŧ�� ��й����繤���٧�ش�ͧ���������Űҹ�ͧ complex tone �������ö������Դ pitch ���蹡ѹ㹡óշ���ѹ�������ԡ�á�Ѵਹ ��觤�Ҵѧ����ǡ��ʹ���ͧ�Ѻ�����§�٧�ش (���§����) ���ǧ�����ʵ�������ö�������� piccolo ��ͻ���ҳ 4.5 kHz ��зӹͧ�ŧ������鵤�������٧���ҹ����蹨пѧ�����Ҵ � �س����ö�͡��Ф�Ѻ������§�ѹ����¹�ŧ ���ѹ�������¹�ŧ�Ẻ����������ŧ
�֧��������ԡ�á�ͧ complex tone ���������§ �����§��鹡�����ö������Դ pitch �� ��Ъ�ǧ�ͧ���������Űҹ��������Դ pitch �������Ѻ�����ԡ�������������§ Ritsma (1962) �ʴ���������� �óշ����������Űҹ��ҡѺ 100 Hz ����� complex tone ����������ԡ�� 3 ��ǵ�͡ѹ �������ö������Դ pitch ��������������ԡ��Ƿ���٧���ҵ�Ƿ�� 25 ������Ѻ���§����դ��������Űҹ 500 Hz �մ�ӡѴ�����������ҳ�����ԡ��Ƿ�� 10
�ҧ��ҹ��������� ����� ����Ѻ broadband complex tone ����������ԡ��������á�繵�� ����ö�����蹷ӹͧ�ŧ������������Űҹ 30 Hz ��觡������§�Ѻ�鵵���ش (���§����) �ͧ���� 27.5 Hz
��ػ ���§㹪�ǧ������� 30 - 5 kHz ������Դ pitch
How Is Periodicity Represented?㹡�õͺʹͧ��� pure tone ��� firing rate �ͧ�����������Ѻ�дѺ�ͧ pure tone ����дѺ���§�٧ firing rate ������٧ (�����Ҩ��������) ����ѧ�������Ѻ�������ͧ pure tone ��觤���������Ѻ��������ѡɳ��Тͧ���� firing rate ������٧ ��蹤�� firing rate �ͧ�������鹻���ҷ�Ѻ������§ �繵��������������ǡѺ�������ͧ pure tone ��Ф�������ѡɳ��Тͧ������Ƿ�����ҧ spike �ҡ�ش ���è���ҡѺ�������ͧ tone (���ҧ���¡����дѺ���§���) �͡�ҡ��� ��������ѧ�Ҩ�١���ʹͼ�ҹ�ٻẺ (pattern) �ͧ�Ԩ�����ͧ�ء��������դ�������ѡɳ���ᵡ��ҧ�ѹ �ٻ���仹���ʴ� excitation pattern �ͧ������Դ������� spontaneous rate �٧ �ͧ pure tone �ͧ��Ƿ���դ�������ҧ�ѹ 10%
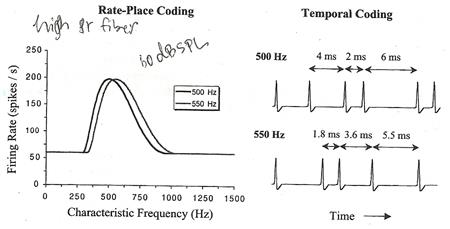
������ ����ᵡ��ҧ�����ҧ�ͧ���§��������١���ʹʹ��µ��˹觨ش�٧�ش�ͧ excitation pattern ��ҹ�� �� firing rate ����������ѡɳ���� � ���ҧ�ѹ���� ����Ѻ�Ҿ��ҹ����ʴ������繼Ũҡ����������§�ͧ����������ͤ�Ѻ���кҧ�ʵ�͡����蹢ͧ basilar membrane ��蹤�� ����١��е���� pure tone �����м�Ե spike ���ҧ�ʢͧ waveform ����� ��ǧ�����ҧ spike ����ҳ�繨ӹǹ�����Ңͧ�Һ�ͧ pure tone �й�� ���������ᵡ��ҧ�ѹ ����������ٻẺ�ͧ spike ���������ᵡ��ҧ�ѹ �� �ó� pure tone ������� 500 Hz (�Һ = 1/500 = 2 ms) ������ҧ�����ҧ spike �������������ҡѺ 2, 4, 6, ... ms ��ǹ pure tone 550 Hz (�Һ = 1.8 ms) ������ҧ�����ҧ spike �������������ҡѺ 1.8, 3.6, 5.5, ... ms (���ٻ�����) ��觡����ͤ�ʹ����Դ��鹡Ѻ�������ͺʹͧ���ⷹ�����Ҩ��繹������㴡��� ��ж֧����ѹ������������� ���ʡ��ѧ����ͤ����
�֧������ҡ�ٴ����� �������ͧ pure tone �١�ʴ����� (1) �ٻẺ�ͧ�Ԩ�����ͧ��������դ�������ѡɳ��е�ҧ � �ѹ������ ��� (2) �ٻẺ�ͧ�Ԩ�����ͧ����������������� �Ӷ����� ������Ẻ (1) ���� (2) �����ͧ��仵դ������ͷ�����Դ����Ѻ��� pitch? �ѧ����դӵͺ�͡�ѹ��Ф�Ѻ ���բ���稨�ԧ�ҧ���ҧ����Ҩ����㹡���Ҥӵͺ��
˹��, ��������ö㹡���¡�������ͧ pure tone �ͧ��Ƿ���������ӡ��� 4 kHz �ͧ����ҹ�� �������ö������ҡ ��гյ�ҡ �����´���ҷ���Ժ������¡������¹�ŧ�ͧ excitation pattern �ٻ���仹���ʴ�����¡�������ͧ pure tone (����դ������ 200 ms) ������������ ������ �������ö��Ǩ�Ѻ����ᵡ��ҧ�����ҧ pure tone ������� 1000 Hz �Ѻ 1002 Hz ��

�ͧ, phase locking �����������������������ͤ��������� 5 kHz ����ѹ��ҧ��ͧ�ѹ�ʹաѺ���������������Ѻ��� pitch ����稨�ԧ����ͧ ���������¹������� phase locking ���� temporal coding ���� ��� (2) ����ǹ��������Ѻ����Ѻ��� pitch
�ٻ��ҹ��ҧ �� �ʴ�������ͧ complex tone ��������§ input, ������������ͧ input �������Ԩٴ��ҡѹ ����� complex tone ����դ��������Űҹ��ҡѺ 100 Hz, �ٻ��ҧ �ʴ� excitation pattern ��� �ٻ��ҧ �ʴ���è��ͧ�����蹢ͧ basilar membrane ��� 5 ���˹觷���դ�������ѡɳ��е�ҧ�ѹ (������١��) ��д�ҹ�����ͧ͢�ٻ��ҧ��� waveform �ͧ complex tone

�ѧࡵ ��觤�������٧ bandwidth �ͧ����������觡��ҧ �ѧ��� ���������ԡ��� � ��������á��ҹ�鹷�������ҿ excitation pattern ���ѡɳ����١���蹡��ⴴ�¡�͡�� ���¤������ �������ö���Թ���§�����ԡ�� 4-5 ����á���ͧ complex tone �¡�͡����ǡѺ�����ԡ����ҹ���� pure tone �� ��ǹ��������ԡ�٧ � ���ͷ���������ҧ�ͧ��������٧ � ��� excitation pattern �Һ���º (���п�����������������ԡ���µ�Ǽ�ҹ������Ŵ������Ԩٴ ���ͧ�ҡ bandwidth �ͧ���������ҧ) ��蹤�� �����ԡ�٧ � (�٧���������ԡ��� 10) �����١�¡�͡�� ��ػ���� � ��� ����ʹ٨ҡ�����蹢ͧ basilar membrane �ѹ����ö����¡�����ԡ����� ���¡�����ԡ�٧�����
Plack �Ѻ Oxenham (2005) �͡��� cochlea ����ö�¡�����ԡ 8 ����á�� ��᷺���������Ѻ���������Űҹ �����ҧ�á��� �ӹǹ�ͧ�����ԡ�٧�ش�������ö�¡���Ŵŧ�����������Űҹ��� (��ӡ��� 100 Hz) ���ͧ�ҡ Q �ͧ��������դ�ҹ��·���������ҧ�դ�ҵ��
����������ǡѺ�����ԡ����¡�͡�����е�Ǩж١��������鹻���ҷ�����ٻ�ͧ rate-place coding ��� temporal coding ��觢���������ǡѺ���������Űҹ��� ��Ҿ�� rate-place coding ������ҡ ������Ŵѧ������������ temporal coding �ҡ����֡�Ңͧ Jorin �Ѻ Yin (1992) ����� �����������������ͤ�ʡѺ envelope �ͧ�����蹢ͧ basilar membrane �ѧ��� ��ǧ������ҧ�����ҧ spike �֧������������繨ӹǹ�����Ңͧ�ͧ�Һ�ͧ complex tone ���ͧ�ҡ ���������ö�¡����ᵡ��ҧ�ͧ���������Űҹ����ҡ (��ӡ��� 1% ����Ѻ�����ԡ�¡ ��ҡ��ѧ����ö�¡����ᵡ��ҧ��) �֧���͡ѹ��� temporal coding �繵���Ӥѭ㹡���觢����Ť��������Űҹ

�ٻ����ʴ������蹢ͧ basilar membrane �Ѻ�ٻẺ spike 㹡�õͺʹͧ��������ԡ����¡�͡�ҵ��˹�� (�ٻ����) �Ѻ�����ԡ���� � ��Ƿ������¡�͡�� (�ٻ���) ������ ����»���ҷ���ٹ�Ѻ�����ԡ��Ƿ���¡ ����͡�ʡѺ�ç���ҧ�����´ ��з������·��ٹ�Ѻ�����ԡ�������¡ ����ͤ�ʡѺ envelope
How Is Periodicity Extracted?�Ӷ�� �к��Ѻ������§�Ӣ��������鹻���ҷ�������ҧ�� �����Ըա��� ���ͷ����� periodicity �ͧ���§ ��з��������Ѻ��� pitch?
����͡� Ohm (1843) �Ѻ Helmholtz (1863) �Դ��� pitch �ͧ complex tone �١��˹��¤������ͧ�����ԡ�á �ǡ�ҤԴ��� ���������Թͧ���Сͺ����������§���� � ��� ��ҡ���֧�������ͧͧ���Сͺ����ش�͡�� �ѹ������Ф�ͤ��������Űҹ��� periodicity ���㹪��Ե��Ш��ѹ���� � � ����¹��١��ͧ�Ф�Ѻ ���������Űҹ��ҡѺ�������ͧ�����ԡ�á ��㹻� 1956 Licklider ���ʴ���������� �֧�����Ҩ����� low-pass noise ���ͷӡ�� mask ��ҹ����������dz���������Űҹ�ͧ complex tone ��ҡ��ѧ�����Ѻ��� pitch �������Ѻ�óշ�������� noise ŧ� ���¤������ �֧�����Ҩ�������Թͧ���Сͺ��Űҹ �� pitch �������ѹ��Ѻ periodicity �ͧ complex tone ���������¹�ŧ ��ҡѺ �к��Ѻ������§�е�ͧ����ö�֧����������ǡѺ���������Űҹ�ҡ�����ԡ����٧������
�֧��������ԡ�á�������繵�͡���Ѻ��� pitch ����պ���dz������ҹ�����ԡ�ӴѺ��� � ����Ӥѭ��͡���Ѻ��� pitch ������ҧ�ҡ��÷��ͧ˹�觢ͧ Moore, Glasberg �Ѻ Peters (1985) ���������¹�������ͧ�����ԡ���˹��� complex tone �ѧ�ٻ

������ �������¹�������ͧ�����ԡ ����� pitch ����¹ �µ���Ţ�����ͧ͢��ҿ��������Ţ�����ԡ�������¹������� (��§��硹���) �ѧ����� Moore ��Ф�о���� �������¹�����ԡ����ͧ ��� ������ �觼š�з���ͤ��������Űҹ㹪�ǧ 100 - 400 Hz �ҡ����ش
����Ѻ�ա��÷��ͧ˹�� Dai (2000) ����� �����ԡ�����դ��������� � 600 Hz �繵���Ӥѭ�ش ��觨��������ԡ��Ƿ������ù�鹢������Ѻ���������Űҹ �� ��Ҥ��������Űҹ 100 Hz �����ԡ��Ƿ��ˡ�繵���Ӥѭ����ش ���Ҥ��������Űҹ 200 Hz �����ԡ��Ƿ��������Ӥѭ�ش
�����������Ţ������ͧ�����ԡ����Ӥѭ��͡���Ѻ��� pitch ��������� �����˹�觷��ҹ�Ԩ�·�������繾�ͧ��ͧ�ѹ��� �����ԡ����¡�͡�� ����ǹ�Ӥѭ����ش��͡���Ѻ��� pitch ���¤������ ��� complex tone ����������ԡ�������ö�¡�͡���� �֧��� complex tone ��ǹ���Ҩ���������ҧ�ӹͧ�ŧ�� ���ѹ����� pitch ������ҡ ���Ѵਹ �͡�ҡ��� ����ѧ����ö�¡����ᵡ��ҧ�����ҧ���������Űҹ�ͧ���������Сͺ���������ԡ�¡ ��ա��ҡ���¡����ᵡ��ҧ�����ҧ���������Űҹ�ͧ������������������ԡ�¡ �ѧ�ٻ

�ҡ�ٻ F0DL = fundamental frequency difference limen ����繤���ᵡ��ҧ����ش㹤��������Űҹ�������ö��Ǩ�Ѻ�� �����§���������º��º���С�������������ԡ 11 ��ǵ�����ͧ�ѹ ������ ��������ö㹡�õ�Ǩ�Ѻ������ҧ���ŧ�������������������Ţ�����ԡ��ҡѺ�Ժ�������ԡ����ش�繵��
�Ӷ������� �к��Ѻ������§���Ըա���㹡���Ҥ��������Űҹ�ͧ complex tone? ���������ŷ���ʹ�����Ҩ���繤ӵͺ���� 2 ���� ��� pattern-recognition model �Ѻ temporal model
����¢ͧ pattern recognition ��� �к��Ѻ������§����ö�� pattern �ͧ������������ԡ㹡�û���ҳ���������Űҹ �� ����������ԡ����դ������ 400, 600 �Ѻ 800 Hz ��ҡ�����������§�ѧ������դ��������Űҹ 200 Hz ���Ͷ���������ԡ 750, 1250 �Ѻ 1500 ��ҡ������Ҥ��������Űҹ��ҡѺ 250 Hz ��駹������������ҧ�����ҧ�����ԡ���Դ�ѹ����ҡѺ���������Űҹ �й���������ԡ��� � ����¡�͡�����ͧ��ǡ���§����������Ѻ����Ѻ��� pitch
㹡�÷� pattern recognition ���բ���ʹ���Ҥ����� harmonic template �ѧ�ٻ��ҹ��ҧ

����Ѻ���Ź�� �ѹ�Ѻ�á �к��е�ͧ�¡�����ԡ��� � ����������ԡ�¡�͡�ҡ� ���Ǵ���������ԡ�¡����ҹ����ҡѹ�Ѻ template �ѹ�˹�ҡ����ش �ѭ�Ңͧ���Ź���� �ѹ�������ö��Ժ�¡���Ѻ��� pitch �ͧ���§�������������ԡ�¡��
�ա����˹�� temporal model �Ҥ��������Űҹ�ҡ��ô��ٻẺ spike ���鹻���ҷ��駨ҡ�����ԡ�¡�������¡ �ѧ�ٻ

�ٻ�ʴ������蹢ͧ basilar membrane ��� phase locking ���鹻���ҷ���ͺʹͧ��������ԡ���˹�� �ͧ ��� ˡ ��з�������� 1600 Hz (�����������ԡ����¡) ����¢ͧ���Ź���� �е�ͧ��������ҧ�����ҧ spike �ͧ���� � (���¡��� inter-spike interval) ���������·���з��֧���������Űҹ�ͧ���§ (�ʴ��Һ�����١��) ����Ըշ���ջ���Է���Ҿ㹡���ҤҺ�ѧ����� ������鹴��¡�÷� autocorrelation �������º��º�ѭ�ҳ� � �Ѻ�ѭ�ҳ˹�ǧ���� (���������˹�ǧ��ҧ � �ѹ) �ͧ����ѹ�ͧ �ѧ�ٻ

���������� �������˹�ǧ��ҡѺ�ӹǹ�����Ңͧ�ѵ�ҫ�ӤҺ�ͧ waveform ��� correlation strength (�Ҩҡ ������ͧ�Ťٳ�����ҧ�ѭ�ҳ�鹩�Ѻ�Ѻ�ѭ�ҳ˹�ǧ���� � ����� �) ���դ���٧ ��ѧ�ҡ��� �����Ҽ��Ѿ��ҡ autocorrelation ������� �ء��� ������ѹ�ç � �����ҤҺ���� ��觤Һ������ǹ�����Ф�Ѻ����ǹ��Ѻ�ͧ���������Űҹ ��ʹ��¢ͧ���Ź���� �ѹ��Ժ���������� �����������ö�¡����ᵡ��ҧ�ͧ���������Űҹ��� ��з��� pitch �֧�դ����Ѵਹ��������§����������ԡ�¡�������º�Ѻ���§�������������ԡ�¡ ��ʹ����ա��С���Ҩҡ��÷��ͧ��Ҿ�ū�ҧ����͡�Ẻ�������з��Ѻ�Ũҡ autocorrelation ������¤������ ���Ź��������������Űҹ������ �Ѵ�Ѻ�š�÷��ͧ�����ѧ���Թ pitch Ŵŧ
����ʹͤ�� ���������ա���¡��ҧ�ҡ�ҡ�ѹ����Ѻ�����ԡ�¡��������ԡ����¡ ���� pattern recognition �֧�ѧ���͡�ʶ١ ����ѹ��Ժ�����§�������������ԡ�¡����� ����ѧ������ͧ�������������ҧ��ä鹤��Ҥ�Ѻ
| Create Date : 20 ����Ҥ� 2556 | | |
| Last Update : 23 �ԧ�Ҥ� 2556 15:37:05 �. |
| Counter : 3933 Pageviews. |
| |
|
 |
|
|
|
Audio Watermarking Based on Spread Spectrum Communication Technique
[��úѭ���������ͧ�����ѧ�֡��]
�����ҵ������ػ�ҡ����� 7 How could music contain hidden information? ˹ѧ��� Applied Signal Processing: A MATLABTM-Based Proof of Concept (Springer, 2009) ��¹�� C. Baras, N. Moreau �Ѻ T. Dutoit
�������ö�ͧ watermarking ��ѭ�ҳ���§������ͧ�ͧ�ѭ�ҡ�����ӴѺ�Ե 1 �Ѻ 0 ��ҹ��ͧ�ҧ������÷���� noise �����ҡ�繾�������Ѻ �¡���ͧẺ��� �Ե�����Ҩ��觡��� watermark bit ��� noise ��� �ѭ�ҳ���§����ͧ �й�� ��÷� watermarking ����º��ҡѺ����͡Ẻ����Ѻ��е���觷���ʹ���ͧ�Ѻ��ͧ�ҧ����� �ٻ��ҹ��ҧ�ʴ�����ͧ watermarking �繻ѭ�� communication �ѭ��˹��

����Ѻ watermarking ��ҵ�ͧ�͡Ẻ SNR ������ҡ (SNR = Psignal/Pnoise) ��������٤��������ö���Թ�����ŷ��нѧ���ͫ� ������ͧ�ҡ SNR ��Ӥ�� bit rate ��ӵ�� (�շ���ش����������������ѡ���ºԵ����Թҷ�) ��� error rate �դ���٧ (����ҳ 10-3 �������º�Ѻ�к�����������ҧ ADSL ��������� 10-6)
Spread Spectrum Signals������á ���������ô����Ԥ Spread spectrum (SS) ��㹧ҹ�ҧ��ҹ��÷��� ���Т���蹢ͧ�ѹ��� 1. �Ըչ�鷹�ҹ (robust) ��͡��ú�ǹ㹪�ǧ�������᤺ �, 2. �繡����Ẻ�ͺ � �� � ��� 3. ������ʹ���㹡���觢�����
�ѭ�ҳ SS ���ѡɳ������� 2 ��С��
1. bandwidth �ͧ�ѭ�ҳ SS �١�������ҧ���� bandwidth �ͧ������������ҧ�ҡ (����任���ҳ 10-100 �������Ѻ�ҹ��ҹ�ҳԪ�� ��л���ҳ 1,000 - 106 ��� ����Ѻ�ҹ��÷���) ��÷���ѧ�ҹ�ѹ���Ш�� (spread) ���ҹ�����ҧ��� ����� PSD ���ŧ ������ѭ�ҳ SS ���͡��仵աѺ�ѭ�ҳ��ҹ�������᤺����ŧ ������������ҹ�������᷺᤺�������к� SS �������� ������ҵ���Ѻ�ͧ�к����Ǻ����ѭ�ҳ��ʹ��ҹ�����ҧ�ҡ � 㹡�ô֧�������͡�� ��ʹ��ա��С�èҡ PSD ��Ӥ�� �������ö������ѹ��ӡ��� PSD �ͧ noise �� �ѹ������Ф�Ѻ����ѡɳ���㹡���觢�����Ẻ�ͺ � �� � �ͧ�ѹ
2. �ա���� spreading sequence (�ҧ�ա����¡ spreading code ���� pseudo-noise) 㹡�����ҧ�ѭ�ҳ SS ��ҹ���������ҧ�ҡ�����ŷ����� ����� spreading sequence ���е�ͧ�繷�����ѹ ���ç�ѹ ��駽������н���Ѻ
�ѡɳ� 2 ���ҧ����繢�ʹ������¤�Ѻ �Ӷ�� ��ͧ���������繡���š����¹����? �ӵͺ spectral efficiency ���ͻ���Է���Ҿ�ͧ�����Ŵŧ ����Է���Ҿ�ͧ�����������ҡ�ѵ����ǹ�����ҧ�Ե�õ��� bandwidth ����Ԥ SS ������ҷ���ӡ��� 1/5 ��з���Ԥ�ҵðҹ��� � �������ͺ 1
Direct Sequence SS (DSSS)� DSSS ���� time hopping ��� �ѭ�ҳ DSSS �����ҧ�ҡ��äٳ���ФҺ���Ңͧ˹�觺Ե (bit-sized period ���� Tb) �ͧ�ѭ�ҳ������ (㹷�����ѭ�ҳ�����觤�� watermark) ���� pseudo-noise ����Сͺ�ҡ�ӴѺ�ӴѺ���ҧ�����ͧ��ū����������� ±1 ����դҺ��ҡѺ Tc �ѧ�ٻ

�ٻ��� ���ش����ѭ�ҳ������ (watermark) �� Tb = 0.2 �Թҷ� �ٻ��ҧ��� pseudo-noise �� Tc = Tb/16 ����ٻ��ҧ����ѭ�ҳ SS �����ҡ��äٳ���ФҺ Tb �ͧ�ٻ�������ٻ��ҧ ����Ѻ�ٻ���� �ʴ� PSD �ͧ�ѭ�ҳ������ (���� �ٻ��Һ�) �Ѻ PSD �ͧ�ѭ�ҳ SS ����� Tc = Tb/4 ��� Tb/16 ����ӴѺ ������ Tc ��觵�� PSD ��觵�� ��з�� Tc = Tb/16 ��ӡ��� PSD �ͧ noise
��Ҥӹdz PSD �ͧ�ѭ�ҳ SS ������ҡ �ҡ�������ѭ�ҳ�����觹��������亹��������Ẻ NRZ ����Сͺ�ҡ��ū������������Һ Tb ��������Ԩٴ ± 1/Tb ��Ҩ���
����������PSDNRZ(f) = [sinc2(fTb)]/Tb
������ͧ�ҡ�ѭ�ҳ SS �ͧ�����ѭ�ҳ NRZ ����ū��դҺ��ҡѺ Tc ��������Ԩٴ ± 1/Tb �����
����������PSDSS(f) = [Tcsinc2(fTc)]/Tb2 �����(�ѧ���͵��ٻ����)
Communication Channel Design������ҡ����� (Emitter) ���к���������ʴ��ѧ�ٻ��ҹ��ҧ �ѭ�ҳ���§ x(n) 㹷������ noise �ͧ�к� ���ѵ������������ҧ��ҡѺ Fs Hz �١��������ҡѺ v(n) �����ѭ�ҳ SS �ͧ watermark ������ҧ�Ҩҡ��äٳ (�����ʹ��ŵ) �ӴѺ�ͧ watermark (bm ∈ {0,1}) ����դ�����Ǣͧ�ӴѺ��ҡѺ M �Ե �Ѻ pseudo-noise (���� spreading sequence, c(n)) ����Сͺ���µ�����ҧ�ӹǹ Nb ��� �����¹᷹�����ǡ���� c = [c(0), c(1), ..., c(Nb - 1)]T

����ǡ���� c �������Ҩ�ѧ���������Ҩҡ������ҧ�ӴѺ������������դ��� {-1, +1} �ҷ� Walsh-Hadamard sequence ���� Gold sequence
��������� bm �����µç ���� bm ∈ {0, 1} ��ҡ��ŧ�ѹ���ѭ�ѡɳ�ش�������¡��� am = 2bm - 1 ∈ {-1, +1} ������ٳ�Ѻ c ����� vm
����������vm = amc
���;ٴ��� vm = +c ��� am = 1 (���� bm = 1) ��� vm = -c ��� am = -1 (���� bm = 0) ��ѧ�ҡ��鹨���� v(n) �Ң��´��� gain g ���ͤǺ��� SNR �����ҧ v(n) �Ѻ x(n)
�������� ����觢����� (���ͽѧ������) 1 �Ե�ء � ������ҧ Nb ��� �ѧ��鹺Ե�õ R �֧�ӹdz��ҡ Fs/Nb
�Ҵٷҧ��ҹ����Ѻ (Receiver) ��ҧ �ҡ�ٻ ����� ym = gvm + xm ���� ym = +gc + xm ����� am = +1 ��� ym = -gc + xm ����� am = -1 �� xm = [x(mNb, x(mNb+1), ..., x(mNb+Nb-1)]T ���ǡ����ͧ������ҧ�ͧ noise (�������§) 㹪�ͧ�ҧ������� ��� m ��� frame index
����Ѻ�Ե����Ѻ����ҡ
����������
(arg max = argument of the maximum, �ѭ�ѡɳ��ҧ�����¶֧ ��� b ������� P(b|ym) �դ���٧�ش)
㹡óշ���ͧ�ҧ�����������繪�ͧẺ AWGN (additive white Gaussian noise) ���ͪ�ͧ�ҧ���ǡ white noise (���¶֧�ѭ�ҳ��������� PSD �����) ��������Ԩٴ�ͧ noise �ա�á�Ш��Ẻ���� (���� Gaussian distribution) ��Ҵѧ����Ǩ�����šѺ��û���ҳ�ҡ����ͧ���¢ͧ�Ťٳ����� (αm) �����ҧ ym �Ѻ c
����������
���� �����᷹��� P(b|ym) �����������ѹ��ͧ��� �����
����������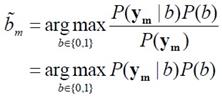
�·�� P(ym) �� priori probability �ͧ ym �������ռš�з���͡�û���ҳ��� bm ��� P(b) ��� priori probability �ͧ���Ф�ҷ�������ͧ b ���㹡óշ��������������ҡѹ �ѹ�������ռŵ�͡�û���ҳ bm �����蹡ѹ �й��
����������
㹡óժ�ͧ�ҧ�������Ẻ AWGN ��� xm �� ��������� Gaussian Ẻ Nb-dimensional multivariate ����դ���������ҡѺ 0 �������ԡ������û�ǹ���� (covariance matrix) ��ҡѺ σx2I ����� I �������ԡ���͡�ѡɳ� Nb �Ե� �չ�� ym ���繵�������� Gaussian ����� Nb ����ô��� ���� ym = gvm + xm ���դ���������ҡѺ amgc �������ԡ������û�ǹ�������ǡѺ xm �֧��
����������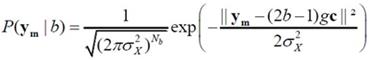
����
����������
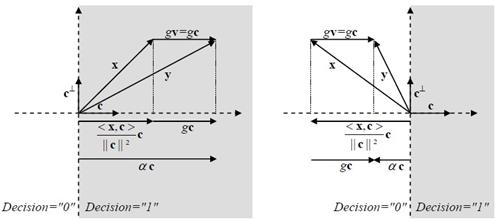
���ͧ�ҡ b ∈ {0, 1} ��蹷���� (2b - 1)2 = 1 ������ b ���դ������� ��÷Ѵ�ش���¢ͧ����ù��֧�͡��� �������ö�� bm ��ҡ ����ͧ���¢ͧ�Ťٳ�ԧ����� αm �����ҧ ym �Ѻ c
����������
�ٻ���仹���ʴ��Ҿ�óսѧ bm = 1 ŧ��ǡ�������§ x ���ǡ������ѧ�ҡ�ѧ���� y ��觤ӹdz�ҡ gv + x ���� gc + x ���� bm = 1 ��зҧ����Ѻ�еդ������ "1" ��� α > 0 �ٻ�����ʴ��ó� <x,c> �繺ǡ ��������� g ���繤�Һǡ����á��� ��������� α > 0 �й�� bm = 1 ��蹤�ʹ֧�����Ѻ��������ç�Ѻ���ѧ������ ����Ѻ�ٻ��� �繡óշ�� bm = 0 ���ͧ�ҡ <x,c> �繤��ź ��� g �����Թ� �óչ��֧�����Ѻ��������Դ�Ф�Ѻ �����ҡ����Ѻ��١ ��ͧ�ҷҧ����� g > <x,c>/|c|2
Error RatePDF �ͧ αm ��� g = 1 ��� σx2 = 20 dB �ʴ��ѧ�ٻ ����ͤ�� R ��ҡѺ 50, 100 ��� 120 ����ӴѺ (R = Fs/Nb �·���� Fs �繤�Ҥ���� 44.1 kHz �й�� �Ҩ�ٴ��� ��ҿ�����͵��������� Nb ��ҧ � �ѹ) �ٻ���¤�͡ó� b = 0 �ٻ��� b = 1

αm �繵�������� Gaussian �Ե����� ����դ������� (2bm - 1)g ��Ф����û�ǹ σx2/|c|2
����������
���������� ������Ҩ��繷�� αm �繺ǡ����� bm = 0 ��Ф�����Ҩ��繷�� αm ��ź����� bm = 1 �����ҡѺ�ٹ�� (���¤������ �ѹ���͡�ʷ����Ѻ���ʹ֧�Ե�͡����Դ���) �������ͤ�� R �ҡ��� (��ҿ PDF ����ŧ ��С�Ш�¡��ҧ���) ������Ҩ��繴ѧ����Ƿ�� 2 �óա������ҡ��鹵�� ������Ҩ��繷�����ҹ�����Դ��Ҵ�������ҡ
����������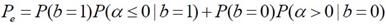
����ѭ�ѡɳ����е���� priori probability ���ǡѹ (��蹤�� P(b=1) = P(b=0)) ������Ҩ��繢ͧ error ����ö����ҳ�����ҿ��ҹ�� �դ����ҡѺ ��鹷����Ѻ�ѹ�ͧ P(αm|bm = 0) ��� P(αm|bm = 1) �����ҨФӹdz Pe ��
| ���������� | 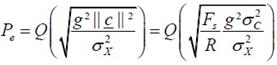 | �·�� | 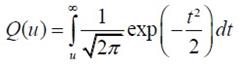 |
�����ù������� σc2 = |c|2/Nb = ���ѧ�ͧ pseudo-noise ���� spreading sequence �»���ҳ
������ ������Ҩ��繷�����ҹ��ҼԴ�������Ѻ SNR �ͧ watermarking (= g2σc2/σx2) �Ѻ R �ٻ��ҹ��ҧ�ʴ���ҿ ���� ���͵ Q(√u) �Ѻ u ��Ҿ��͵ Pe(R) �Ѻ R ����� SNR ��ҧ � �ѹ ����� Fs = 44.1 kHz

Informed Watermarking��к�������÷������������� noise �ͧ��ͧ�ҧ���������ǧ˹�� �֧������ѹ�������ª��㹡�û�Ѻ gain ������������� ������Ѻ watermarking ��� ������Ѻ ���� noise 㹷���������§�����Ҩ����������
��Ҩ���������¡�ô��Ըյç仵ç�����ҧ��û�Ѻ gain ��������Ǩ�Ѻ�����������ҧ����բ�ͼԴ��Ҵ ��蹤�� �ҧ��������ͽ��������ʨе�ͧ�ա�û�Ѻ��� g ����繿ѧ���蹢ͧ�������ͪ��¤����ѹ�ǹ�ͧ���ѧẺ�ѹ�շѹ���ѭ�ҳ���§ ����ѡ�� SNR ��餧��� ��觷������ � �¡�û���ҳ��� σx2 �ͧ������§ (~ 20 ms) ���ǡ�˹���� g ����õ�� σx
�������Ѻ仴١�ҿ PDF �ͧ α ������ ��ҷ���� error ��������¡�÷�����ҿ��� 2 �¡�͡��ҧ�ҡ�ѹ ��з����¡��������� g �����һ�Ѻ����� g �ͧ��������ʹ���ͧ�Ѻ
����������
�ŷ����������� error �ҧ����Ѻ������ (��ͨҡ��� ��� g ������¹��������� ��Ҩ���¹᷹ g �ͧ����������� gm) �Ըա�˹���� g �Ҩ���� ��� βm ������ͧ�������ǡѺ am ��� gm �繤�Һǡ����á��� ���� βm ������ͧ���µç�ѹ�����Ѻ am ���˹������ gm = -βm/am
���ҧ�á��� 㹷ҧ��Ժѵ� ��ͧ�ҧ������á������ noise ������ա����� �й�� �ǡ���������Ѻ���Ѻ�֧����� ym ���� ym+pm �����
����������
�֧��ͧ�ա���������� Δg ���仴��� (Δg ��˹��ҡ�����û�ǹ�»���ҳ�ͧ�ѭ�ҳú�ǹ�ͧ��ͧ�ҧ�������) ���ͤ���������л�ʹ�������к��ѧ���� error-free �й�� gm �е�ͧ��ҹ����
����������
�ٻ��ҹ��ҧ�ʴ� inform watermarking �ͧ�ǡ�������§ x ���١�ѧ���� "1" ����Ѿ�����ǡ���� y = gv + x = gc + x �����ҵ�ͧ���͡��� g ���ͷ���� y ������㹾�鹷���������Ң����� (�����赡㹾�鹷���� ����Ѻ�������ҹ���� "1") �ٻ�ʴ���������´ 2 �ó� �ó��á x(1) ������͡��� g ������Դź���á��� �� 0 �ǡ���� y �絡����㹾�鹷������ ����Ѻ�óշ���ͧ x(2) ��ҵ�ͧ���͡��� g �٧ � ��������ͧ�Ѻ noise ��� � 㹪�ͧ�ҧ������� ������ҧ 2Δg �١�������繪�ͧ��ҧ�����ҧ��õѴ�Թ� "1" ���� "0" �ͧ����Ѻ

����Ѻ �ѭ�ҷ���Դ�ҡ��÷���� error-free �����Ըչ���� �س�Ҿ���§�ͧ y �е��������§�Դ���¹�ҡ������� gv ��� g �ҡ � ��ҡѺ x �ҧ�͡��ͻѭ�ҹ���������ѵ��Ѻ������§�ͧ����������Ҫ��·�������������Թ������ watermark �Ըա�ä�� ����� Psychoacoustic Model (PAM) �Ҫ���㹡�äӹdz masking threshold (��������´�ͧ PAM ������¹�֧㹺��͡���蹹Ф�Ѻ ��������ҵ��˹ѧ��ͺ���� �����¹�����Ҽ����ҹ���ѡ PAM �������ҧ������) ��蹤�� ��� PSD �ͧ watermark Sw(f) �����ӡ��� PSD �ͧ masking threshold Φ(f) �ѹ�з�������������Թ watermark ���;ٴ�ա���ҧ˹����� ���§�鹩�Ѻ���١ú�ǹ ������ͧ�ҡ����Է���Ҿ�ͧ�к� watermarking �繿ѧ���蹢ͧ SNR �й�� ����Է���Ҿ���ش����Դ��鹷�� Sw(f) = Φ(f)
�������ö��������ҿ��������дѴ�ŧͧ���Сͺ�������������Ѻ��� G(f) ���� perceptual shaping filter �᷹��� gain g �ѧ�ٻ

| �¤���������� G(f) �� all-pole filter: |  |
��� v(n) �ͧ����������ѡɳ�Ẻ���ǡѺ white noise (����������ҡѺ�ٹ����Ф����û�ǹ��������) ��û�Ѻ�������Է���ͧ�������������� output w(n) �ͧ�ѹ�� PSD Sw(f) ��� �繻ѭ���ѧ���������ͻѭ���͡Ẻ���������� � � (��ش�ͧ������ԧ��� Yule-Walker) �ҧ��ҹ����Ѻ ���ͧ���� G-1(f) �� demodulator ��չ���ջѭ����� �ѧ�Ѻ����� x(n) (�� watermarking ��Դ blind) ��� x(n) �繵�Ƿ����������ҧ G(f) �й�� G-1(f) �֧��ͧ���ҧ�����Ẻ����ҳ � �ҡ y(n) �¤�������Ӣͧ��� G-1(f) Ẻ����ҳ���������Ѻ 1. robustness �ͧ PAM ��� watermark ��� 2. noise ��� � 㹪�ͧ�ҧ�������
��ѧ�ҡ��� ��Ҥӹdz bm �������� ����ǹ����Ҵ�����ͧ���¢ͧ <zm,c> ᷹ ����� z(n) ��� output �ͧ G-1(f) �����Ҷ����������������� G-1(f) ������� � ����Ѻ�������ö�١���ҧ������Թ�����ʢͧ G(f) ���ԧ � ��Ҩ��� zm = vm + rm ����� r(n) ��� x(n) ��ѧ�ҡ��ҹ G-1(f)
����� G-1(f) (�ժ������¡ zero-forcing equalizer) ���觼���� SNR ��� output �ͧ�ѹ�դ�ҵ���ҡ ����Ǥ�� ���ѧ�ҹ�ͧ�ѭ�ҳ v(n) �դ�ҹ��� � �������º�Ѻ���ѧ�ҹ�ͧ�ѭ�ҳ���§����ҹ equalizer ���� r(n) ���ͧ�ҡ PSD �ͧ v(n) �Ѻ r(n) ᵡ��ҧ�ѹ �ѧ��� �֧�������п������ z(n) �Ẻ�����Ѿ��ҡ��ÿ������������� SNR ��觷����¡�â���ͧ���Сͺ������ͧ z(n) ������������ v(n) ���Ŵ�ͧ���Сͺ������ͧ z(n) ������������ r(n) ˹�ҷ��ѧ������繢ͧ FIR Wiener filter H(z) �ѧ�ٻ��ҧ�����������仵�ͷ��� G-1(f) ���ǹ�ͧ����͡Ẻ������������¹�֧�ա��㹺��͡���� �ѹ����ԧ ������㹺���� ��ѧ�ҡ�����¹�й� Wiener filter �ʴ������ transfer function �Ѻ �ش����� Wiener-Hopf ���ǡ稺��Ҥ��ɮ���¤�Ѻ
| Create Date : 05 ����Ҥ� 2556 | | |
| Last Update : 6 ����Ҥ� 2556 16:26:38 �. |
| Counter : 3534 Pageviews. |
| |
|
| |
|
|
|
A Journey Through the Auditory System
[��úѭ���������ͧ�����ѧ�֡��]
�����ҵ������ػ�ҡ����� 4 㹪������ǡѹ ˹ѧ��� The Sense of Hearing �� Christopher J. Plack �����������Ǩҡ��Ǣ�� 4.2 The Cochlea ����Ǣ���á 4.1 From Air to Ear �����ٴ�֧仡�˹�ҹ��㹺��͡���� � ����� ����Ѻ��������ػ�ͧ����� 2 ��� 3 �� The Nature of Sound (��ػ) �Ѻ Production, Propagation, and Processing of Sound (��ػ) �� �ӴѺ�����ҷ�����ػ㹵��� ��������§�繢�͵����ǹ Summary ���� 2 ���á �����§����ӴѺ��Ǣ�ͧ͢˹ѧ���
The Cochlea��� cochlea �ͧ�٪��㹹�����Ф�Ѻ�������蹢ͧ�������§�١�ŧ���ѭ�ҳ俿�� (electrical neural activity) cochlea �繷�͢�Ҵ����բͧ������������ ��ǻ���ҳ 3.5 �繵����� ��鹼�ҹ�ٹ���ҧ����� 2 ��������� �ѹ����ԧ ��鹼�ҹ�ٹ���ҧ�Ф��� � ���ŧ���������ҧ�ҡ˹�ҵ�ҧǧ�����ͺ���dz������¡��� base ����鹼�ҹ�ٹ���ҧ����ش��� apex ���颴�繡���»���ҳ 2.5 �ͺ ��ѧ�秹Ф�Ѻ����¡�д١ �й�� ��ҨШѺ cochlea ��袴�繡�����͡�Ҥ�������鹵ç�����

�ٻ��ҹ��ҧ�ʴ��Ҿ�Ѵ��ҧ�ͧ cochlea �����ҷ�͵������Ƕ١���� membrane �ͧ�ѹ ���� Reissner's membrane �Ѻ basilar membrane ������Դ��ͧ���ͪ�ͧ��ҧ���ͷ�����«�����仴��¢ͧ���� 3 ��ǹ �ժ������¡ scala vestibuli, scala media �Ѻ scala tympani ��� s. vestibuli �Ѻ s. tympani �������͡ѹ��ҹ��ͧ�Դ��� � ���¡ helicotrema �����ҧ basilar membrane �Ѻ��ѧ�ͧ cochlea ��� apex (���ٻ) ��ǹ media �繷�����·���¡�͡仵�ҧ�ҡ ����ǹ��Сͺ�ͧ���� (endolymph) ᵡ��ҧ�ҡ�ա�ͧ������� (perilymph)


�ٻ��������Ҿ�Ѵ��ҧ�����ç���ҧ�������ҵԹ�� basilar membrane ���¡��� tectorial membrane ����� organ of Corti ���������ҧ membrane ����ͧ organ of Corti ��Сͺ���� hair cells ������ (hair cells �����쪹Դ����ɪ�Դ˹�� �ǡ�ѹ������ǹ����¢���� � ���¡��� stereocilia ����͡��) �������ʹѺʹعẺ��ҧ � ����֧���»���ҷ (nerve endings) � cochlea �ͧ�� ���� hair cells ˹���Ƿ�������ҹ� ���¡��� inner hair cells ��д�ҹ�͡�����ҡ�֧ 5 �� ���¡ outer hair cells ��ʹ������� cochlea �Ҵ����� hair cells ������� 3,500 ���� �����¹͡��� 12,000 ���� ��� �����ش�ͧ stereocilia �ͧ outer hair cells �з����ѧ����� tectorial membrane (��з�� hair �ͧ inner ���ѧ�Ф�Ѻ) ˹�ҷ��ͧ outer hair cells ��� ����¹���ѵ��ԧ�Ţͧ basilar membrane (��������´�оٴ�֧㹺��͡����) ��ǹ˹�ҷ��ͧ inner hair cells ��� �ŧ�����蹢ͧ basilar membrane ����ѭ�ҳ俿��

The Basilar Membrane���§������ѧ cochlea ��ҹ�ҧ˹�ҵ�ҧǧ�� (�ѹ��� membrane �ѹ˹�觷��Դ��������ҧ�٪�鹡�ҧ�Ѻ cochlea) �ͧ����� cochlea ᷺�������ö�պ�Ѵ�� �ѧ��������˹�ҵ�ҧǧ�ն١��ѡ������ cochlea ���ͧ�ҡ�����蹢ͧ��д١�Ź ��� Reissner's membrane ��� basilar membrane �ж١��ѡŧ ���˹�ҵ�ҧǧ�����������ա��ҹ˹�觢ͧ base �ж١��ѡ�͡ ��蹤�� �����蹢ͧ��д١�Ź����� basilar membrane ���
basilar membrane ����ǹ�Ӥѭ��͡���Ѻ������§��ѵ������§�١���¹� �ѹ��˹�ҷ���¡ͧ���Сͺ�ҧ�������ͧ���§ ����dz base ���Ѻ˹�ҵ�ҧǧ�չ�� basilar membrane ᤺����秷��� ����dz�ѧ����ǹ������ǵ�ͤ�������٧ ��ǹ�������ա��ҹ˹�� ����dz apex �С��ҧ�����������秷������ �֧�繺���dz�������ǵ�ͤ�������� (���ٻ��ҧ�� �������� basilar membrane ���ҧ�������� cochlea �բ�Ҵ���ŧ) ���ѵ��ѹ���ͧ membrane ����¹�ŧ���ҧ������ͧ�ҡ base �֧ apex �ѧ��� ���е��˹觺� basilar membrane ������ǵ�ͤ�������кҧ��� (������¡ characteristic frequency)
������ҧ���º��º����������㨡�䡡�÷ӧҹ�ͧ basilar membrane ���֡�֧ʻ�ԧ�ǹ����������§�ѹ�����ѹ����������ҧ��Ǣ�ҹ�Ѻ����š ��ʻ�ԧ�����ѹ�١�Դ����Ѻ��š�˹�� ʻ�ԧ��������������ش�秷����ش (stiff) (����¹ �.���� stiffness �ͧʻ�ԧ��Ҩ��ʴ����¤�Ҥ����ʻ�ԧ���ͤ�ҹԨʻ�ԧ k ��觤������ͧ����������Ẻ������������ԡ�ͧ��ŵԴʻ�ԧ¡���ѧ�ͧ���õ�� k ����ü��ѹ�Ѻ���) ��Ф����秷��ͧ͢ʻ�ԧ�����ѹ����ǹ������ ���� � Ŵŧ������ � �����ʻ�ԧ�ǹ�����·ҧ��ҹ����ҡ��� � ��蹤�� ʻ�ԧ�������ش ��ʻ�ԧ����������ͤ��·���ش �ѹ�����ҡ��ѧ���º��º����к�ʻ�ԧ�Դ��ź�������� basilar membrane �«�����ͤ�� base ��Т�Ҥ�� apex
�������������ʻ�ԧ�ѹ˹�� ���Ǽ١���´�ҹ˹�觢ͧʻ�ԧ�Դ�Ѻ��� ���ǻ��������ѹ���������ŧ�駴�� � �ͧ�ѡ�ѡ��������ҵԡ���ش��� �ѵ�ҡ����蹢ͧ��Ź�����Ф�Ѻ��ͤ���������ṹ��ͧ�к� ���ʻ�ԧ�秷����ҡ ��š���駴�맴��¤��������٧ ��蹤�� ��������ҡ ����ʻ�ԧ���� (loose) ��š�����������ŧ��� �դ�������� �չ�� ��Ҥس����ͨѺ�����ա��ҧ˹�觢ͧʻ�ԧ ����������͢��ŧ���¤�������٧���Ҥ���������ṹ��ͧ�к� ��š���������ҡ ������ͧ͢�س���������ŧ���¤���������ṹ�� �����蹡���ҡ
��Ѻ�ҷ�����������ʻ�ԧ�Դ��ż١���§������� �����ҨѺ������� �����Ǣ�ҹ�Ѻ����š ���������������ŧ���¤��������˹�� ��觷����Ҩ���繤�� ����š����˹������ҡ������ŷ������� ��駹�������� �������ͧ��������������ŧ�����§�Ѻ����������ṹ��ͧ��š������� ��Ҥ������ͧ������դ�ҹ��� � ��ŷ������ç������ҧ��� (apex) �ͧ����� ���Ҥ������ͧ������ҡ ��Ũ�����ҧ���� (base) �չ�� ��Ҥس����ö�����������ŧ��ٻẺ����դ�������ͧ�������ѹ (����Ф�Ѻ �֡�Ҿ��ͨѺ�������� � ���¤�������٧ ������ǡѹᢹ��¡������ � ��鹢��ŧ���¤��������) �����蹢ͧ��ŷҧ��ҹ���¨������Ф�������٧ ��ǹ�����蹢ͧ��ŷҧ��Ҩ������Ф�������� ��������Ѻ�к����ͧ�������ö�¡������������ѹ�����͡���� �������§�Ҿ���� � �ͧ����¡ͧ���Сͺ�ҧ������� ��з�� basilar membrane �Ѻ cochlea �դ����Ѻ���ҡ���ҹ������
����������ͧ basilar membrane �������Ѻ��������¢ͧ�ͧ���Ƿ�������ͺ �, ���ṹ��� tectorial membrane, stereocilia �ͧ outer hair cells �����ǹ�Ӥѭ��� �������ԧ�� (mechanical action) �ͧ outer hair cells (��������´��ǹ outer hair cells ���� basilar membrane ���ҧ�� �С���Ƕ֧㹺��͡����)
�ҡ��䡷�������� �������Ҿٴ����� basilar membrane �ӵ�������Ѻ band-pass filter ���� � �ѹ (bank) ����ժ�ǧ bandwidth ����������¼�ҹ���Ѻ�ѹ �ѧ�ٻ
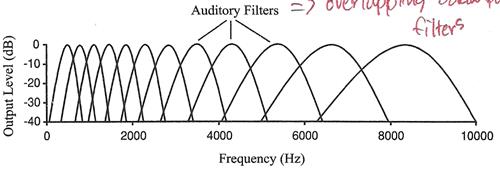
���е��˹觺� basilar membrane �� characteristic frequency, bandwidth ��� impulse response �е�� �������§����դ����������ѹẺ�Ѻ���Թ�ҧ�������� ͧ���Сͺ��������٧�ͧ���§��鹨С�е�� basilar membrane �� � base ��з��ͧ���Сͺ��������ӨС�е���� � apex �ѧ��� basilar membrane �֧�����Ѻ�����������������ͧ���§�������� �ѧ�ٻ

characteristic frequency �ͧ���˹觵�ҧ � �� basilar membrane ���������¹�ŧ���ҧ���ԧ��鹨ҡ base �֧ apex �����ҧ�� logarithm �Ф�Ѻ ��������٧���������Դ�ѹ�ҡ���Ҥ�������� �ѧ�ٻ

The Traveling Wave�֧��� basilar membrane ���բ�Ҵ��� ��ǹ�����ҧ����ش�� 0.45 �����������ҹ�� ���ѧ����㹼�ѧ�秤���¡�д١�ͧ cochlea ��ѡ�Է����ʵ�������ö�֡�ҡ���������ͧ basilar membrane 㹡�õͺʹͧ������§���µç�ҡ��ü�ҵѴ ��Ф��á���ء�ԡ����ͧ����� Georg von Békésy (���Ѻ�ҧ�������Ң�ᾷ��� 1961 �ҡ����ͧ������Ф�Ѻ) ���֡�ҡ���������ͧ basilar membrane � cochlea ���Ѵ�͡�ҨҡȾ������ѵ�� �ѹ����ԧ�Ҵ١���������ͧ��Ҥ�Թ�����¡�Ш�����躹 Reissner's membrane ����ѹ���������仾�����Ѻ�ç���ҧ�ͺ � scala media ����֧ basilar membrane ��� organ of Corti �й�鹡���������ͧ��Ҥ�Թ����ҹ�������ö��͡����������ͧ basilar membrane �����
 
von Békésy �ѧࡵ��� �����һ� pure tone ����� �ٻẺ�ѡɳ��Тͧ�����蹨��Դ��鹺� basilar membrane �����ҹ֡�Ҿ���� cochlea ����繷�͵ç��� ����������ͧ basilar membrane �д٤���¤��蹹���Թ�ҧ�ҡ base ��ѧ apex �ٻẺ�����蹹�����¡��� traveling wave �ѧ�ٻ��ҧ��
�������ͧ��� traveling wave �ҡ base ��ѧ apex ��Ҩ������Ҥ��蹤��� � ⵢ�鹡�з�觶֧�ش�٧�ش �ѹ�繨ش�� basilar membrane ��������ṹ����������ͧ tone �����蹨����ŧ����������ҧ�Ǵ���� �ô���֡��� ���� traveling ��� �繼�����ͧ�ҡ��÷�����е��˹觺� basilar membrane ������������ŧ㹡�õͺʹͧ��͡�á�е�鹴��� pure tone �·��������ͧ���������е��˹觹�鹨���ҡѺ�������ͧ pure tone
����ͧ������㨼Դ�ѹ��������ͧ˹�觤�� ����������ͧ traveling wave �ҡ base �֧ apex �繼Ũҡ�������¹�ŧ�����ѹ���������ѧ cochlea ��ҹ˹�ҵ�ҧǧ�շ�� base �ѹ���Դ�Ф�Ѻ �������§������������ҡ㹢ͧ����� cochlea �й�� �ء�ش�� basilar membrane �֧���Ѻ��á�е��᷺�о���� � �ѹ�����դ����ѹ����¹�ŧ�Դ��鹷��˹�ҵ�ҧǧ�� ����������Ẻ�ѡɳ��дѧ����Ǣͧ traveling wave �Դ��������ա��˹�ǧ�� (phase delay) ���������鹨ҡ base �֧ apex ����� membrane ��� apex ��蹪�ҡ��ҷ�� base ��С��˹�ǧ����繼Ũҡ�ѡɳзҧ����Ҿ�ͧ membrane �����ǹ base �դ����秷������᤺������ǹ apex (��蹤�� �к� stiffness-limited �еͺʹͧ���ǡ����к� mass-limited)
�ٻ���仹���ʴ� snapshot �ͧ membrane ��еͺʹͧ��� pure tone �ͧ��� ��������� 2 kHz ��� 200 Hz ����ӴѺ �����Ҫ�ǧ�������ҧ��õͺʹͧ�ͧ��������Ӻ� membrane �С��ҧ���Ҥ�������٧ (�٤�����Ǣͧ envelope) �������е��˹觺� basilar membrane �зӵ������ band-pass filter �����ҹ��������ҹᵡ��ҧ�ѹ� ��觤�������� �������ѹ��ҹ filter ����ͺ�ء��Ǻ����¡��Ŵ���������ҡѹ ��Ҩ֧��繨ҡ�ٻ��� basilar membrane ��ͺ�����µͺʹͧ��ͤ�������� ��з���պ���dz��ǧ�����ҧ�ѡ�ͺʹͧ��ͤ�������٧

Transduction & How Do Inner Hair Cells Work?��áԨ�ŧ�����蹢ͧ basilar membrane ����ѭ�ҳ俿�������觵�������ͧ��˹�ҷ��ͧ inner hair cells ��ҹ���ͧ hair cells �� stereocilia ���������� ˹�ҵҤ���¢������� � ���� basilar membrane �Ѻ tectorial membrane ���������ŧ��� ���ǡ���ж١��������§��§��ҹ��ҧ �ѧ�ٻ

㹤����繨�ԧ stereocilia ���§��Դ���� (�ٻ�����繶١�����������仹Դ�Ф�Ѻ) ����Ѻ���§�дѺ�����§�մ�����������Թ �ǡ�ѹ���§仴��¤�ҡ�á�ШѴ�� 0.3 ���������ҹ�� �ٴ��Ҷ�� stereocilia �բ�Ҵ��ҡѺ�֡ Sears 㹪Ԥ��� ���дѧ����ǡ���ҡѺ��á�ШѴ�ͧ�ʹ�� 5 �繵�����

stereocilia ������鹨�������§�ѹ����������õչ ���¡��� tip link ���� stereocilia ���§����� scala media ���ͪ���͡�͡ cochlea ����� tip link ���ж١�֧����״ �Դ��ͧ���������� � �ѧ�ٻ

�����ͧ����Դ�͡��� K+ (�õ���������) ���������� hair cell �����ѡ��俿�Ңͧ���� (��дѺ mV) ������ͧ�ҡ�ѡ��俿�ҹ�� (resting electric potential) �ͧ inner hair cell �դ����ź (����ҳ -45 mV) ��Ҩ֧���¡���������鹢ͧ�ѡ��俿�Ҵѧ�������� depolarization ��С�кǹ��� depolarization ����ͧ����������������ͻ���ҷ (neurotransmitter) �١�������Ҫ�ͧ��� � (synaptic cleft) �����ҧ inner hair cell �Ѻ�������ҷ���鹻���ҷ�Ѻ������§ �ѧ�ٻ

����������ͻ���ҷ����Ҷ֧�������ҷ (����) �ѹ�з�����Դ��ū�����俿�� (spike) �����������ҷ
��� stereocilia ���§�㹷�ȵç���� ���ͪ��������ٹ���ҧ�ͧ cochlea ��蹤�� tip link ���� ���١�֧ ������ͧ�ҧ�ѧ����ǻԴ Ŵ��ûŴ�����������ͻ���ҷ ��觡���������ͧ basilar membrane �ҡ����� tip link ����觶١�֧����Դ��ͧ���ҧ�ҡ�����ҹ�� �������ա������¹�ŧ�ҧ俿��� hair cell �ҡ ������ͻ���ҷ�����觶١������ҡ �ѭ�ҳ俿�����鹻���ҷ�ҡ�������
����Ѻ outer hair cell ��١��е�鹴����Ը��Դ�Դ��ͧ��ҹ��������ǡѺ inner cell ��Դ�ѹ��� �������¹�ŧ�ѡ��俿�Ңͧ������з���������Ǣͧ��������¹ �ѧ����ѹ�֧�������Դ�Ż�з���� basilar membrane (�С���Ƕ֧㹺�����) ����Ӥѭ outer hair cell ����ͧ����ǡѺ����觼�ҹ��������ѧ��ͧ
The Auditory Nerve�Ӷ�� �ѵ�좹Ҵ�˭���觢����Ũҡ��ǹ˹����ѧ�ա��ǹ˹�觢ͧ��ҧ��������ҧ�� �ӵͺ �к�����ҷ �к�����ҷ��Сͺ�����������ҷ��������觷�˹�ҷ��Դ�������������ҧ�Ǵ���������ҧ�����Ѻ������ (sensory cell) ������������ �����ͧ ��ͧ������չ����ҡ����˹���ʹ��ҹ���� ���������ա���������͡Ѻ��������ա�Ѻ���� �����Ѻ���������������Ф�Ѻ���ç���»����żŷ��Ѻ������ա��ѧ�ҡ �֧��鹷������ҤԴ�� ����֡�� ��дٷ�����
4 ��ǹ��Сͺ��ѡ�ͧ�������� dendrite, soma (�ӵ������), axon �Ѻ terminal button �ѧ�ٻ
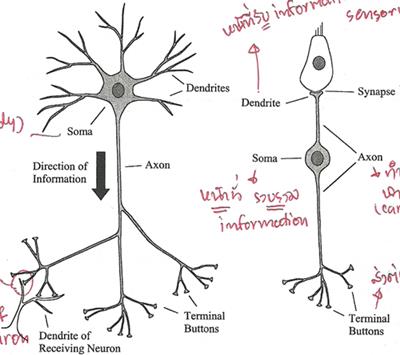
�ٻ����ʴ��������ç���ҧ�ͧ���� 2 Ẻ �ٻ�����繹�����辺��������ͧ �� dendrite �Ѻ terminal button ������� ��������ҧ���¢ͧ�ٻ�����ʴ� terminal button ���ҧ synapse �Ѻ dendrite �ͧ������� ��ǹ�ٻ����繹����Ѻ������ �� ��Ƿ���������͡Ѻ hair cell � cochlea �ǡ����� dendrite ����
�ٴ����� � ˹�ҷ��ͧ dendrite ��� �Ѻ�����Ũҡ�����Ѻ������ ���ҧ inner hair cell ���ͨҡ����������, soma �Ǻ��������Ţ������, axon �ӾҢ����Ţ������ ��� terminal button �觵�͢��������Ѻ dendrite �ͧ����������
synapse ��� �������������ҧ terminal button �Ѻ dendrite ���������ҧ�����Ѻ�����ʡѺ dendrite �·�������ͧ�ͧ��� dendrite �ͧ�������˹�觨����ҧ synapse �Ѻ terminal button �ͧ�����������ա�������µ��
������Ǣͧ axon �Ҩ�������ͺ 1 ����㹹���������Ǣ�ͧ�Ѻ���������Ǣͧ��������� �ѹ�ӾҢ����Ţ��������ٻ�����ū�俿�� ���¡��� action potential ���� spike �¢�Ҵ�ͧ spike ��������ҳ 10 mV ���ٻẺ�ͧ spike ���ͨӹǹ������� spike ���˹������� ���ͷ�����¡��� firing rate �Т������Ѻ�����Ţ������ �ѵ�����Ǣͧ spike � axon �Ҩ�٧�֧ 120 m/s �������¹�ŧ�ѡ��俿�ҷ�� terminal button �ѹ���ͧ�ҡ�� spike �Թ�ҧ�Ҷ֧��� �з�����ա�ûŴ�����������ͻ���ҷ ��觨�����Ш�¼�ҹ��ͧ synapse �����ҧ���� ����� spike �Ҷ֧����� ����觻����������ͻ���ҷ�ҡ��� �����������Ѻ��Ǩ�Ѻ������ͻ���ҷ����� �ѹ�Ҩ�з�����Դ spike 㹵���ѹ (�����Ҩ���Ѻ��� spike �����ѧ�Դ����㹵���ѹ���� ������ó�) ��蹤�� ���������ôѧ������繡�кǹ��� electrochemical
Activity in the Auditory Nerve��鹻���ҷ����Ѻ������§��͡�����ͧ axon (�����»���ҷ) ���������Ѻ (���;ٴ��� ���ҧ synapse �Ѻ) hair cell 㹤�����ջ���ҳ 30,000 ���� �������»���ҷ����ҹ����ǹ�˭��������Ѻ inner hair cell �·�� inner hair cell ���е�Ǩ�������Ѻ dendrite ����ҳ 20 ����»���ҷ
���ͧ�ҡ inner hair cell ���е�ǵԴ�Ѻ���˹��е��˹�㴵��˹�˹�觺� basilar membrane �ѧ��� �������е�����鹻���ҷ����Ѻ������§�֧�ӾҢ���������ǡѺ�����蹢ͧ basilar membrane �����˹���§���˹������ cochlea �չ�� ���е��˹觴ѧ���������� (sensitive) ��ͤ�������ѡɳ��з����Ш����˹�� ����� ��Ҿٴ����ҹ������е�ǡ�����ǵ�ͤ�������ѡɳ��кҧ��ҹ���蹡ѹ �ٻ��ҹ��ҧ�ʴ���������ҹ������е�Ǩ��դ��������Ŵŧ���ҧ�Ǵ��������ͤ���������§����ҡ�е���͡��ҧ�ҡ��������ѡɳ���
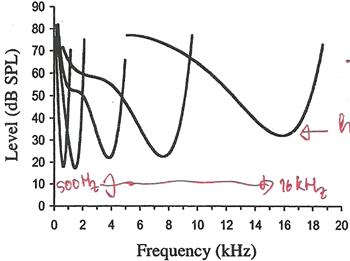
��ҿ��ٻ����ʴ���������ѹ�������ҧ�дѺ�ͧ pure tone ����ͧ�������������� firing rate �ͧ���� 5 ��� (���С�ҿ�繢ͧ�������е�ǡѹ) �������㹻���ҳ����������Ǩ�Ѵ�� ������¡��ҿ������ frequency threshold tuning curve (�ٻ�Ҩҡ��鹻���ҷ�Ѻ������§�ͧ˹� chinchilla) �ش����ش ��� �ش�������Ƿ���ش
�֧�����������§ �������ǹ�˭���� firing rate �дѺ��� ���¡��� spontaneous activity ������ 90% �ͧ����� ���� spontaneous rate �٧����ҳ 60 spike ����Թҷ� ���������ҹ�������������ҧ������������ firing rate ����Ͷ١��е�鹷���дѺ��� ����·��������ա 10% �� spontaneous rate ��� 10 spike ����Թҷ� �繾ǡ����դ�������ǹ��¡��� ��������Ƿ��ᵡ��ҧ�ѹ���Ҵ����Ҩ����ѹ��Ѻ���˹觢ͧ synapse ����Ǥ�� ��� synapse �������Ѻ outer hair cell �ѹ��������·���� spontaneous rate �٧ ���� synapse �����ա��ҹ˹�� ���� spontaneous rate ��� �����١��е�鹴��� pure tone ���ç�Ѻ��������ѡɳ��Тͧ�ѹ firing rate ��������鹵���дѺ�ͧ tone ���֧����٧�ش���˹�� �繨ش������� ���¤������ �������дѺ�ͧ tone �������ҡ���ҹ�� firing rate �����������ҡ���ҹ�� �ѧ�ٻ ������¡��ҿ rate-level function

�͡�ҡ��� ����»���ҷ�ѧ�ʴ��������¹�ŧ firing rate ������ͧ�����ѹ���ͧ�Ҩҡ�������������§ ���� onset �ѧ�ٻ
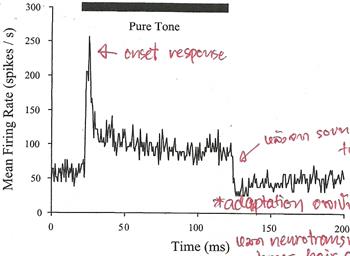
������ �����������§ firing rate �դ���٧�ش (onset response) ���Ŵŧ��������Ҽ�ҹ� ��оͻԴ���§ firing rate �е�ŧ������ spontaneous rate ��� 100 ms
Place Coding���ͧ�ҡ firing rate �ͧ�������鹻���ҷ����Ѻ������§�١��˹��¢�Ҵ�����蹢ͧ basilar membrane � ���˹觷���ѹ��������� �ѧ��� �������е�����鹻���ҷ�դ�������ѡɳ��л�Шӵ�� ��оǡ�ѹ������ǵ�ͪ�ǧ�������ӡѴ�ͺ � ��������ѡɳ��й����ҹ�� �͡�ҡ��� ��������дѺ���§ �ѧ���� firing rate �ͧ���� �����Ҩж֧�ش������� �й�� �Ը�˹�觷���к�����Ѻ������§����᷹�����ʹ�������ͧ���§�����ٻ�ͧ firing rate �ͧ�������ᵡ��ҧ�ѹ �� ������§���ͧ���Сͺ������������� ��������դ�������ѡɳ��������§�Ѻͧ���Сͺ��ǹ�鹨����� firing rate ������¡��ù��ʹ͢����������Ẻ������ place code ���� rate-place code ���Т�����������١᷹�����ٻẺ�ͧ firing rate �ͧ���������
Phase Locking & Temporal Codingplace coding ��������§�Ըա�����Ƿ�� characteristics �ͧ���§�ж١���ʹ� �������¹�ŧ�ҧ俿��� inner hair cell �Դ�������͢��ͧ�ѹ���§���价ҧ��ҹ�͡�ͧ cochlea ��ҹ�� �������ҵ��� basilar membrane ���ѧ��蹢��ŧ�ͺʹͧ��� pure tone ��������� ������ stereocilia �ͧ�ѹ���§�����Ѻ��ҧ��� �չ�� stereocilia ���Դ depolarize ����������ѹ���§价ҧ��ҹ˹�觶١���¤�Ѻ �����ҡѺ �ѹ�ͺʹͧ��ͺҧ���Тͧ������ ���¤������ �������鹻���ҷ����Ѻ������§�м�Ե spike ��������˹�觢ͧ waveform ���ѵԹ�����¡��� phase locking ���С�õͺʹͧ�ͧ������͡���ͨѺ���Ѻ���Тͧ������ basilar membrane �ѧ�ٻ
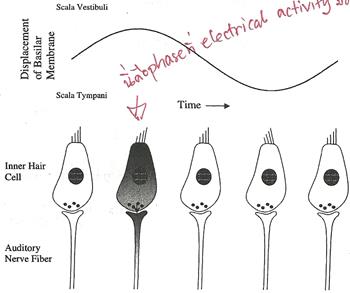
�ҡ�ٻ ���� ��� �ʷ�� electrical activity �դ���٧�ش
�ҡ���ѵ� phase locking ����ͧ ��͡�繹�¶֧�ա�Ը�˹�觷������ʹ�������᷹����������鹻���ҷ����Ѻ������§ ��蹤�� ��ù��ʹ���ٻ�ͧ timing ���� synchrony �ͧ�Ԩ�������鹻���ҷ �� �����ҡ�е�鹴��� pure tone ������� 100 Hz ����� ��������������м�Ե spike ������ҧ�ѹ�繨ӹǹ�����Ңͧ�Һ�ͧ pure tone �óչ���� 10 ms �չ�� firing rate �ͧ��������Ҩ�ҡ���� 200 spike ����Թҷ� ���֧�������繢մ�ӡѴ�ͧ��������ª��ҡ phase locking ���������������ҳ 200 Hz ���ҧ�á��� �֧��������������е�Ǩ��������ö�ͺʹͧ�����ѵ�ҷ���٧�͵�͡���繵��᷹�ء�ͺ�ͧ waveform ����繵�ǡ�е�� ������ö��ѭ������¡����Ң����Ţ�����èҡ�����ء���������ѹ������᷹�������ͧ tone ��������٧ �ѧ�ٻ �������ͧ input ��ҡѺ 250 Hz �ٻ��ҧ���ٻẺ spike �ͧ����������� �ٻ��ҧ�繡����� spike ����Ե�ҡ���� 500 ���

From Ear to Brain�ٻ���仹���ʴ���鹷ҧ�觢����Ũҡ����ѧ��ͧ (ascending auditory pathways) ��鹻���ҷ�Ӣ����Ũҡ cochlea �觵����ѧ cochlea nucleus ����繡�����ͧ����� brainstem (��ҹ��ͧ ���� ��ͧ) ����觵����ѧ�������ʵ�ҧ � � brainstem �ѧ�ٻ
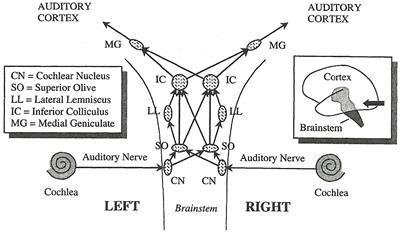
���Ъ�ǧ�ͧ����觹�� ����������ǡѺ���§�ж١�����ż����ç���¹��� �� SO �����ż�����ǡѺ��ú͡���˹觢ͧ���觡��Դ���§ ��� IC ����ǡѺ����Ѻ��� pitch �ͧ���§
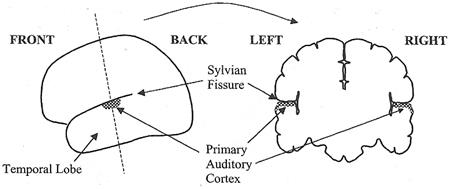
����»���ҷ�ҡ IC ������Ѻ (�������ҧ synapse �Ѻ) MG �������ǹ˹�觢ͧ������� (thalamus) ���ͧ��ǹ��ҧ �·�����ʷӵ�ǻ��˹�觪����� (relay station) ����Ѻ�������Ѻ������ ����»���ҷ�ҡ MG ��͡Ѻ auditory cortex (���͡��ͧ��˹�ҷ���ҹ����Ѻ������§) �������ǹ˹�觢ͧ cerebral cortex (���͡��ͧ�˭�) cerebral cortex ��� ��ǹ����ͧ���������Ѻ�蹹�����Ф�Ѻ �л�������鹼����ǹ�˭�ͧ��ͧ ��˹�ҷ���ͧ����ǡѺ��û����żŤ����Դ��дѺ�٧ ����֧�ѧ�����Ѻ�����ʡѺ�������������ͧ�� cortex ������蹹����ҧ � ����˹���§ 3 ��������� �ѹ���Ѻ����������Ѻ���ͨ����վ�鹷�����ҡ �ҧ��ǹ�ͧ cerebral cortex �Ѻ�����Ũҡ�к�����ҷ�Ѻ������ ����ǹ�Ѻ�ٻ �Ѻ���§ �繵� ��ǹ�Ѻ���§ ���� auditory cortex ���躹 temporal lobe (��ͧ��պ��Ѻ) �������������� cerebral cortex ������¡��� Sylvian fissure (��ͧ������¹) �ѧ�ٻ
�͡�ҡ ascending auditory pathways �ѧ�� descending pathways ��觢����Ŷ١���觨ҡ�ٹ���ҧ�����ż����§�дѺ�٧���ͧŧ��ѧ�дѺ��ӡ��� ���ŧ件֧��з�� cochlea �������ö�Ǻ�������������ͧ basilar membrane ����������к��Ѻ������§�١�͡Ẻ����������ٹ���������ż��дѺ�٧����ö�Ǻ����Ԩ������дѺ��� ����觼š�з���͡�û����ż����§����¤�Ѻ
| Create Date : 30 ����¹ 2556 | | |
| Last Update : 22 �ԧ�Ҥ� 2556 22:17:07 �. |
| Counter : 5400 Pageviews. |
| |
|
| |
|
|
|
|
|

 �ҡ��ͤ�����ѧ����
�ҡ��ͤ�����ѧ���� ���Դ������͡ : 85 �� [
���Դ������͡ : 85 �� [