|
|
|
Research of Improved Echo Data Hiding: Audio Watermarking based on Reverberation
[��úѭ���������ͧ�����ѧ�֡��]
�����ҵ��� ����ػ�ҡ������㹪������ǡѹ�ͧ G. Nain, S. Wang �Ѻ Y. Ge � Proc. IEEE International Conference on Acoustics, Speech, and Signal Processing, pp. 117-180 �� 2007 ��� Honolulu
�Ԥ echo-hiding ���������������µ��˹�ҹ�� ���ҧ�ҡ������� echo ��������Թ 4 �١�����¤�Ѻ ������Ѻ�Ԥ������¹�ʹ�㹺�������� ��������촢ͧ�ѹ��� reverberation ��觡������������͡ �͡�ҡ echo �ӹǹ�ҡ�������ѹẺ�Ѻ�� ����ѧ���� kernel 2 ���㹡�ýѧ "0" �Ѻ "1" ��Ӷ�������� ��Ҩ��� kernel �ѧ� ������Ф�Ѻ����� ��Фӵͺ�ͧ�����¹��� �Ҩҡ reverberation (���;ٴ�����Ш� room impulse response) ���ش 2 �ش���ͧ ��ش˹��᷹��ýѧ "0" ����ա�ش����Ѻ�ѧ "1" ���Ըա���� room ir �ͧ�����¹��� image method ��о��������������� room ir �ѧ��˹�ҷ���� secret key �����繵�ͧ��㹡�ô֧��¹���͡�� �����ҡѺ�繡������ security �ա�ʹ˹��

�����������觡��Դ���§������ (sx, sy, sz) ������͡���ѧ 2 �ش �ԡѴ (lx1, ly1, lz1) �Ѻ (lx2, ly2, lz2) �ӹdz room ir h1(n) �Ѻ h2(n) �ҡ������ѹ���ҧ kernel function f1(n) = δ(n) + h1(n) �Ѻ f2(n) = δ(n) + h2(n) ��� room ir ��������ٻ h(n) = α1δ(n-n1) + α2δ(n-n2) + ... + αLδ(n-nL) ����� L ��� ������Ǣͧ room ir (���ͨӹǹ echo ������Ф�Ѻ) ��� xi(n) ��� �ѭ�ҳ�鹩�Ѻ ��Ҩ����ѭ�ҳ���ѧ��¹�� xwi(n) = xi(n)*f(n) ������ѭ�ѡɳ� * ᷹ linear convolution �ç��������� ��鹵��ҧ � �����Ԥ㹵�С�� echo-hiding ���� � � ��ҧ�ѹ���Ըա���� kernel function ��ҹ���ͧ
block diagram ��鹵��ô֧��¹���͡���ʴ��ѧ�ٻ

�ҡ�ٻ ��ѧ�� cepstrum �ͧ xwi(n) ���� ����� cepstrum ������� cross-correlation �Ѻ h1(n - n11 �Ѻ h2(n - n21 ����ҡ�Ե���ѧ������ "1" ��Ҩ���� peak ��� n1 �ͧ d1(n) �������繢ͧ d2(n) �ѧ�ٻ

��� σwn1 �� ��ǹ���§ູ�ҵðҹ�ͧ d1(n) ¡��鹤�ҷ�� n1(n) ���ͧ�ҡ�����˹觴ѧ������繤�� peak ��� σwn2 �� s.d. �ͧ d2(n) ¡��鹷�����٧�ش�蹡ѹ ��Ҩ����� r(i) = [d1(max)/σwn1]/[d2(max)/σwn2] �繵�ǵѴ�Թ���ҺԵ���ѧ��� "0" ���� "1" ��� r(i) > T (�� threshold ���˹��) ��Ҩк͡��ҺԵ���ѧ������ "1" ���� r(i) < T �Ե���ѧ��� "0"
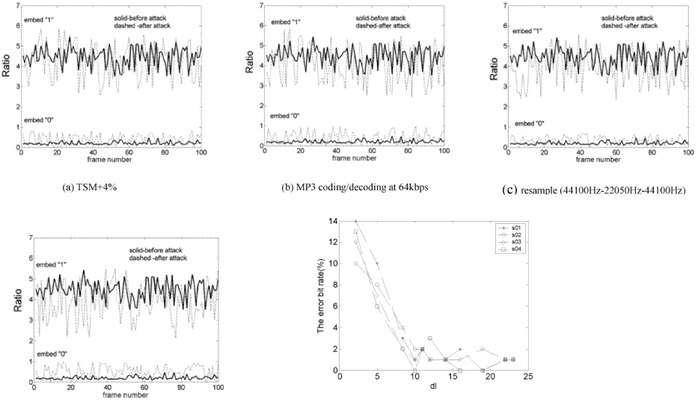
�š�÷��ͧ: �ٻ��ҹ��ҧ�ʴ���������ѹ�������ҧ dl = sqrt[(lx1-lx2)2 + (ly1-ly2)2 + (lz1-lz2)2] �Ѻ correct response �ͧ�ŧ S01 - S04 ������ ��� dl ���� correct response ����觴� ������ѵ� imperceptibility �д��ҡ��� dl < 15

��÷��ͧ������͡�� dl = 8.378 ����ͼ�ҹ�������Ẻ��ҧ � ���Ǿ���� error bit rate < 4% ��ҿ��ҹ��ҧ�ʴ� ratio curve �������ѧ�������
| Create Date : 16 �á�Ҥ� 2556 | | |
| Last Update : 16 �á�Ҥ� 2556 9:29:39 �. |
| Counter : 1140 Pageviews. |
| |
|
| |
|
|
|
Researches on Echo Kernels of Audio Digital Watermarking Technology Based on Echo Hiding
[��úѭ���������ͧ�����ѧ�֡��]
�����ҵ��� ����ػ�ҡ������㹪������ǡѹ�ͧ X. Cao �Ѻ L. Zhang � IEEE International Conference on Wireless Communications and Signal Processing �� 2011 ��� Nanjing
������ ���������ᵡ��ҧ�ҡ�Ԥ��� � 㹵�С�� echo-hiding ��������¹˹�ҵҢͧ kernel ��ҹ���ͧ��Ѻ �������ʹټš�÷��ͧ ������������֡�������ѡ����� ���е�Ƿ������¹����º��§������ kernel �ͧ Bender ������ 1996
˹�ҵҢͧ kernel ��� Cao �ʹ���Ẻ���

������ᵡ��ҧ�ҡ mirrored kernel �ͧ Wu �����ç���ҧ�ͧ kernel �����ѧ "0" �Ѻ "1" ��������ѹ (�ѧࡵ positive echo �����������š��� negative echo �������º�Ѻ�ѭ�ҳ�鹩�Ѻ)
������ҧ real cepstrum �ͧ segment ���ѧ "0" ��� "1" ����ӴѺ�ʴ��ѧ�ٻ �� d0 = 40 ������ ��� d1 = 90 ������

�����¹�鷴�ͺ�ͧ���ҧ ��� robustness test �Ѻ subjective quality test ��дټš������¹ α ����з���� detection rate ���º��º�����ҧ kernels ��������ʹ͡Ѻ kernels �ͧ Bender ���Ѿ���ʴ��ѧ��ҿ

���������м��Ѿ���ʴ��ѧ���ҧ (������ѹ�Ѳ�Ң��)
SDG ����¡��͡�ҴչФ�Ѻ �����ҧ��� �ͺ������������ ������º�������Ẻ��ҧ�ѹ�Թ�

| Create Date : 15 �á�Ҥ� 2556 | | |
| Last Update : 15 �á�Ҥ� 2556 22:03:21 �. |
| Counter : 999 Pageviews. |
| |
|
| |
|
|
|
Analysis-by-Synthesis Echo Hiding Scheme Using Mirrored Kernels
[��úѭ���������ͧ�����ѧ�֡��]
�����ҵ��� ����ػ�ҡ������㹪������ǡѹ�ͧ W. Wu �Ѻ O. Chen �ҡ IEEE International Conference on Acoustics, Speech and Signal Processing �� 2006 ��� Toulouse
������������ǹ�������¹���ʹ�ᵡ��ҧ�ҡ echo-hiding Ẻ��� � ����¾ٴ�֧�����㹺��͡���µ��˹�� �ҹ��鹹��ͧ Wu �դ������������ 2 �Ӥ�Ѻ ��� (1) analysis-by-synthesis �Ѻ (2) mirrored kernels ��������ҡ����ѧ�� mirrored kernels �ʴ���ѧ�ٻ

����Ѻ segment � � �����Ҩ���� echo ��Ҩ�����ѹ������ 2 segments ���� ���¡��� ��˹�� (front part) �Ѻ����ѧ (rear part) ���з����� kernel �ç���ҧ�����ѹ���վ���������ᵡ��ҧ�ѹ �� �ٻ (a) ��˹������������� da ��з�����ѧ����������� db �����ʴ��֧��ýѧ "0" ��ж���ҡ�����ҡ�ѧ "1" ��ҡ�����Ѻ����˹������������� db ��ǹ����ѧ da �ѹ������Ф�Ѻ�������¢ͧ���� mirrored �ͧ�ѹ �����¹��ҧ��� ��÷� mirror ������ recovery rate �ٵ��ҧ�š�÷��ͧ���º��º

��� αe ��� equivalent decay rate 㹡óբͧ EHBF �ӹdz�ҡ αe = αb + αf ��ǹ�ó� mirrored �ӹdz�ҡ αe = (α0f + α0r + α1f + α1r)/2
����������ա�� analysis-by-synthesis �繢�鹵����Դ���㹡�кǹ��ýѧ��¹�� �ѧ�ٻ

��ѧ�ҡ����� y[n] �����÷� echo Ẻ��� ��ҡ�����������ѹ�Ф�Ѻ �ѧ������稾Ը� �����ѹ��� noise model ���ͨ��ͧ�������������Ҽ��Ѿ��ҡ������դ�� ŷ[n] �Ҷʹ����Ҷʹ��������� �������Ң����ŷ����ҽѧ��� I ��жʹ�� Î ����Ǩ�ͺ�����١��ͧ����� Î �Ѻ -I ��Ҽ��Ѿ�����������ҡѺ 0 (���¤������ �����ŷ��֧�͡�����١��ͧ) ������Ѻ任�Ѻ��� α ���� ������ Î - I = 0 ��Ҩ֧�о�� ����ç������� analysis-by-synthesis ����� ���ҧ�Ŵ�ҹ��ҧ�ʴ�����������Ըշ�� Wu �ʹͪ������� robustness �ͧ�к�

| Create Date : 15 �á�Ҥ� 2556 | | |
| Last Update : 15 �á�Ҥ� 2556 21:17:54 �. |
| Counter : 1168 Pageviews. |
| |
|
| |
|
|
|
|
|

 �ҡ��ͤ�����ѧ����
�ҡ��ͤ�����ѧ���� ���Դ������͡ : 85 �� [
���Դ������͡ : 85 �� [