High Capacity Audio Watermarking Using the High Frequency Band of Wavelet Domain เนื้อหาตอนนี้ สรุปจากบทความชื่อเดียวกันของ Mehdi Fallahpour กับ David Megias ตีพิมพ์ใน Multimedia Tools and Application Vol 52 Issue 2-3 หน้า 485-498 ปี 2011 วิธีการที่ผู้เขียนนำเสนอนี้ high capacity สมชื่อครับ เพราะสามารถซ่อนข้อมูลลงในเสียงได้ถึง 11 kbps !!! สาเหตุที่เลือกใช้ย่านความถี่สูง เพราะหูคนเรานั้นไม่ค่อยอ่อนไหวต่อความถี่สูงเท่าไรนัก เมื่อเทียบกับย่านความถี่เสียงพูด (ดูรูปด้านล่าง) ผู้เขียนจึงเลือกที่จะดัดแปลง wavelet coefficient ของย่านความถี่แถว ๆ 10 kHz ในการฝังข้อมูล watermark bit และสาเหตุที่เลือกใช้ wavelet domain เพราะอาศัยข้อดีของ wavelet ที่เหนือกว่าการแปลงฟูริเยร์ อาทิ มันเป็น time-frequency analysis และเหมาะกับ non-stationary signal ทั้งยังมี computational complexity ต่ำกว่า จึงคำนวณเร็วกว่า และข้อดีอีกประการ (อาจจะด้วยความบังเอิญ) คือ การแยกย่านความถี่ด้วย wavelet นั้นล้อกับโครงสร้าง critical band ในระบบการรับรู้เสียงของมนุษย์ (เกี่ยวกับเรื่องนี้ ผมจะพูดถึงในบล็อกตอนอื่นอีกที) 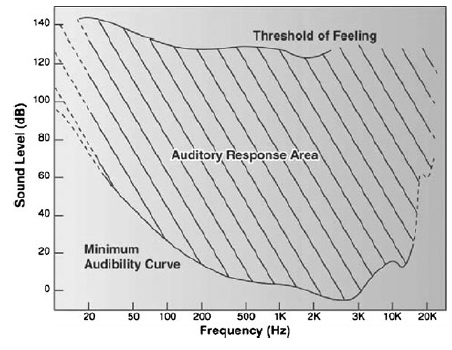 ขั้นตอนการฝังข้อมูลสรุปได้ดังแผนภาพด้านล่าง เริ่มจาก เราแปลง wavelet กับเสียง (สีฟ้า) ให้กลายเป็นสีส้ม ใช้เฉพาะย่านความถี่สูงนะครับ ต่อมาแบ่งออกเป็นท่อน ๆ ท่อนละ s แซมเปิ้ล แต่ละแซมเปิ้ลก็มี wavelet coefficient cj ของมัน เรากำลังจะดัดแปลงค่า cj ตัวนี้แหละเพื่อซ่อนข้อมูล เราคำนวณค่าเฉลี่ย mi ของ ส.ป.ส. ของแต่ละท่อน (โดยการหาผลรวมของ ส.ป.ส. ในท่อนนั้นแล้วหารด้วย s) และค่า ส.ป.ส. ที่จะดัดแปลง c*j เราจะเปลี่ยนมันเป็น mi หรือ -mi เมื่ออัตราส่วนระหว่าง cj ต่อ mi อยู่ภายในช่วง -k ถึง k โดยที่ k เป็นพารามิเตอร์ตัวหนึ่ง เรียกว่า embedding interval (ช่วงการฝัง) แต่ถ้า cj/mi ไม่อยู่ในช่วงการฝัง เราก็จะไม่ฝัง นั่นคือ เราไม่ซ่อนข้อมูล ทีนี้ c*j จะเท่ากับ mi หรือ -mi ก็ขึ้นอยู่กับว่าข้อมูลที่จะฝังเป็น 1 หรือ 0 ตามลำดับ พูดอีกอย่างหนึ่งว่า ถ้า cj อยู่ในช่วง [-kmi, kmi] แล้ว c*j = mi เมื่อ watermark bit = 1 และ c*j = -mi เมื่อ watermark bit = 0 ตัวอย่างสีแดงในรูป คือ ช่วงที่มีการฝัง หลังจากดัดแปลง ส.ป.ส. เรียบร้อยแล้วก็ใช้ inverse DWT เพื่อสร้าง watermarked audio signal 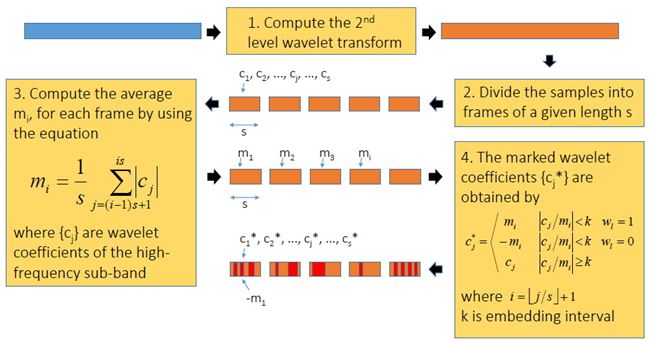 สังเกตว่า ถ้า k มาก โอกาสที่ cj จะมีค่าอยู่ในช่วง [-kmi, kmi] ก็ยิ่งมาก ผลที่ตามมาคือ capacity และ distortion ก็มากตามด้วย capacity มากนี่ดี แต่ distortion มากนี่หมายถึงคุณภาพเสียงห่วย ฉะนั้นจะต้องมีการเลือกค่า k ที่เหมาะสมครับ รูปด้านล่างแสดง wavelet samples ในระหว่างขั้นตอนการฝังข้อมูล a คือก่อนฝัง และ c คือหลังจากฝังแล้ว 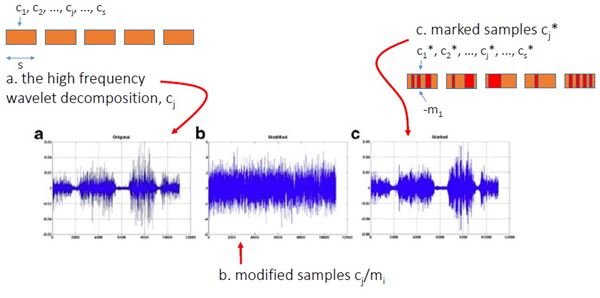 ผู้เขียนบอกว่า ในการดัดแปลงค่า c*j นั้น เขาไม่ดัดแปลงเป็น + หรือ - mi ตรง ๆ แต่ใช้ scale factor α ด้วย เพื่อควบคุมสมบัติด้าน robustness กับ transparency โดยค่าของ α อยู่ในช่วง (0.5,k) นั่นคือ c*j จะถูกเปลี่ยนเป็น + หรือ - αmi และ α ก็เป็นพารามิเตอร์อีกตัวที่ต้องเลือกอย่างชาญฉลาดเช่นกัน ขั้นตอนการดึงข้อมูลแสดงดังแผนภาพด้านล่าง เราทำเหมือนตอนฝังนะครับจนถึงขั้นคำนวณ m*i (สัญลักษณ์ superscript * ในที่นี้หมายถึง เป็นค่าของ watermarked audio signal) และเราก็ใช้แค่พารามิเตอร์ของระบบกับ m*i และ c*j ในการคำนวณ watermark bit (w*l) ตามสมการในขั้นตอนที่ 4 ตัวอย่างเช่น ถ้าพารามิเตอร์ของระบบ k = 2, α = 1 เมื่อเราหา c*j แล้วพบว่ามันอยู่ในช่วง [0, 1.5m*i] เราก็จะรู้ว่า w*l = 1 แต่ถ้า c*j อยู่ในช่วง [-1.5m*i, 0) ค่า w*l = 0 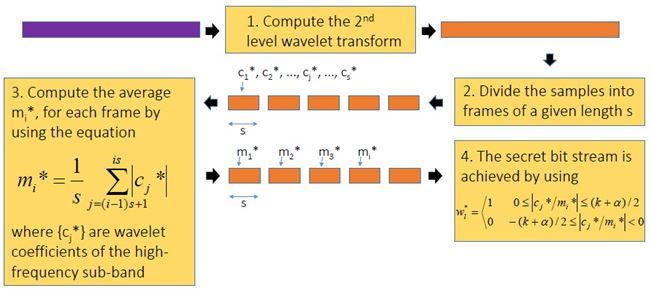 เห็นว่าพารามิเตอร์ที่ใช้ในระบบมีหลายตัว และการเลือกค่าพารามิเตอร์ก็ขึ้นอยู่กับความต้องการต่าง ๆ ของระบบ เช่น capacity, ODG, BER ที่เราอยากได้ ผู้เขียนได้เสนอขั้นตอนการปรับเลือกค่าพารามิเตอร์ดัง flowchar 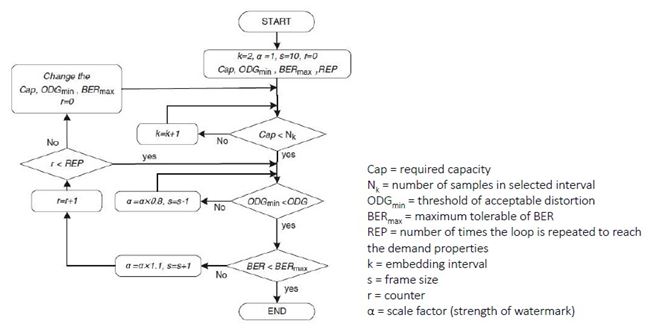 เช่น ถ้า ODG ต่ำกว่า ODGmin หมายถึง คุณภาพเสียงแย่ เราก็ควรปรับลด scale factor (ตาม flowchart การคูณ 0.8 คือ ปรับลดลง 20%) และลดขนาดของท่อน (เท่ากับเพิ่มจำนวนท่อน) การทดลองในบทความใช้เพลง 5 เพลง (44.1 kHz, 16 bits/sample) โดยมีพารามิเตอร์ของระบบ k = 6, α = 2 และ s = 10 และเลือกใช้ Daubechies wavelet รูปด้านล่างแสดงสเปกตรัมความถี่ของเพลงสองเพลง (แถวละเพลง) โดยคอลัมน์แรกเป็นสเปกตรัมของเพลงต้นฉบับ คอลัมน์กลางเป็นสเปกตรัมของเพลงหลังจากฝังข้อมูล watermark แล้ว และคอลัมน์สุดท้ายเป็นผลต่างของสองคอลัมน์แรก (สเกลแนวแกน y คนละสเกลกันนะครับ, ภาพในบทความต้นฉบับที่ผมมีก็ไม่ค่อยชัดอย่างนี้แหละ) จะเห็นว่าส่วนที่แตกต่างอยู่ในย่านความถี่สูง 10 kHz 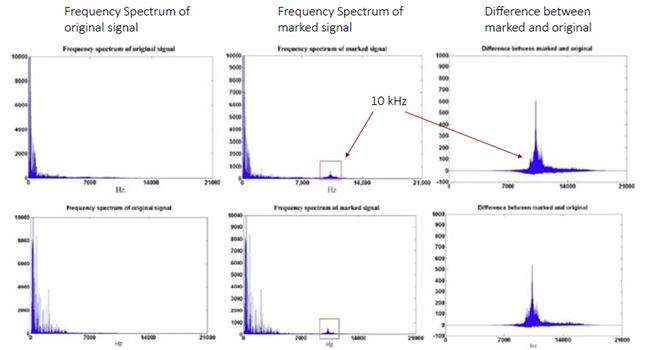 จุดขายอันหนึ่งที่ผู้เขียนบทความนี้ภูมิใจนำเสนอคือ ถึงแม้เราจะเห็นว่าข้อมูลไปซ่อนกันอยู่แถวย่านความถี่สูง 10 kHz (รูปบน) แต่ข้อมูลที่ซ่อนก็รอดจากการถูกโจมตีด้วย RC low-pass filter !!! รูปด้านล่างแสดง high frequency wavelet decomposition ของสัญญาณก่อนถูกโจมตี มี watermark ซ่อนอยู่แล้วนะ (a) และสัญญาณหลังจากผ่านการโจมตีด้วย LPF ที่มีความถี่ cut-off เท่ากับ 5 kHz และ 2 kHz (รูป b และ c ตามลำดับ) สังเกตว่ารูปทรงของสัญญาณเหมือนเดิม เปลี่ยนไปแค่สเกล และสเกลที่เปลี่ยนไปนั้นไม่มีผลกระทบต่อการดึงข้อมูลออกมา เพราะว่าเราใช้อัตราส่วนของ ส.ป.ส. ต่อค่าเฉลี่ยของ ส.ป.ส. ในการฝังข้อมูล 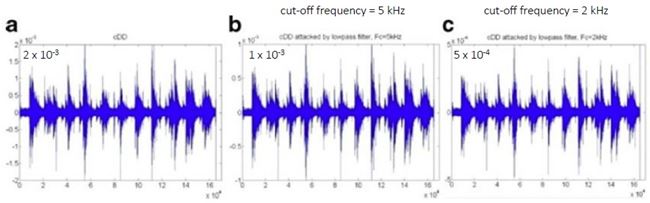 รูปต่อมาแสดง transparency กับ BER โดยใช้ ODG เป็นตัวระบุ transparency หรือคุณภาพของเสียงของเพลงสองเพลง (Beginning of the End กับ Rust) เมื่อถูกโจมตีด้วย (a) LPF กับ (b) HPF ตามลำดับ ข้อสังเกตประการหนึ่งคือ คุณจะเห็นว่าที่ BER สูง ๆ ODG จะต่ำกว่า -3 หมายความว่า LPF กับ HPF อาจทำลายข้อมูลที่ซ่อนในเพลงได้นะ (เพราะ BER สูง) แต่การทำลายนั้นจะต้องแลกกับ ODG ต่ำ (คุณภาพแย่) มันก็เปรียบเทียบได้กับ ผมมีกระดาษที่มีลายน้ำบนหน้ากระดาษ แล้วคุณบอกว่าคุณสามารถทำลายลายน้ำได้โดยการเอากระดาษไปเผาไฟ แน่นอนว่าลายน้ำถูกทำลาย แต่กระดาษก็ถูกทำลายไปด้วย ฉะนั้นมันจึงไม่เป็นประเด็นที่ผู้เขียนจะต้องกังวลครับ 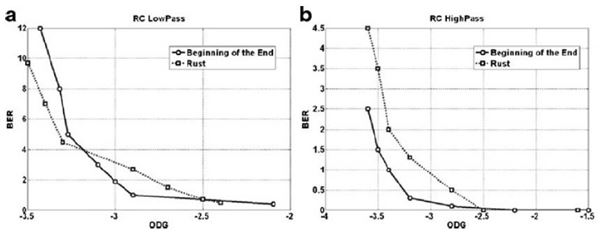 สำหรับตารางด้านล่าง ตารางที่ 1 แสดงค่าเฉลี่ยของเพลง 5 เพลงที่ถูกโจมตีโดยวิธีการในตารางที่ 2 และตารางที่ 2 ยังได้เปรียบเทียบการโจมตีนั้น ๆ กับวิธีการอื่น ๆ ดอกจันสีแดงที่ผมทำเอาไว้ ให้ดูเป็นจุดสังเกตว่าวิธีที่ผู้เขียนเสนอ แพ้ทาง resampling กับ pitchscale ตารางที่ 3 ตรง ๆ ตัว ดูเอง ตารางที่ 4 จะโชว์ว่าวิธีนี้รองรับ payload ขนาดมหึมาได้ชนิดแซงหน้าวิธีอื่นขาดลอย 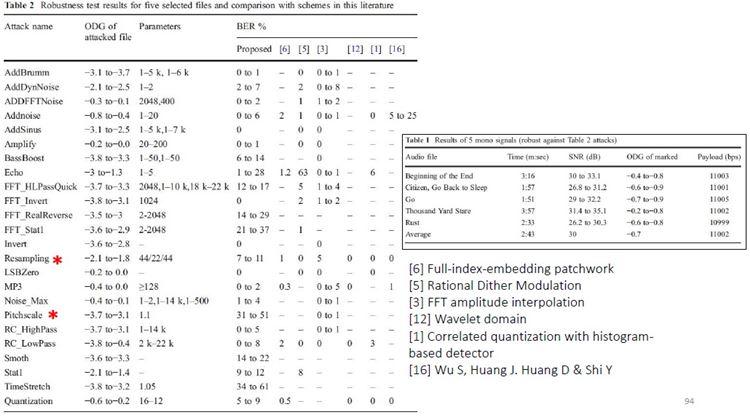 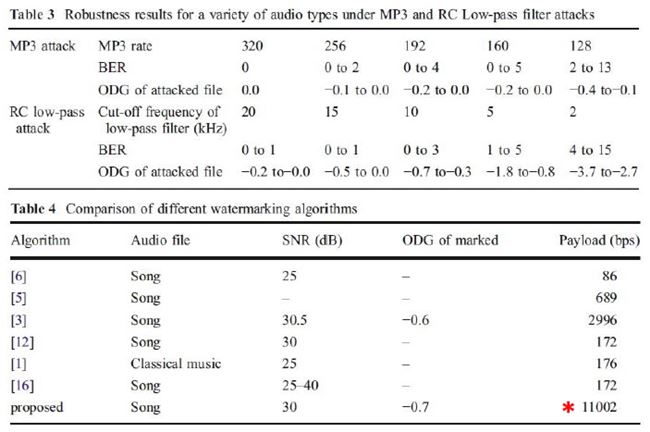
|
บทความทั้งหมด
|
||||||||||||||||||||
 |



 ผู้ติดตามบล็อก : 85 คน [
ผู้ติดตามบล็อก : 85 คน [