Audio Watermarking Based on Spread Spectrum Communication Technique [��úѭ���������ͧ�����ѧ�֡��] �����ҵ������ػ�ҡ����� 7 How could music contain hidden information? ˹ѧ��� Applied Signal Processing: A MATLABTM-Based Proof of Concept (Springer, 2009) ��¹�� C. Baras, N. Moreau �Ѻ T. Dutoit �������ö�ͧ watermarking ��ѭ�ҳ���§������ͧ�ͧ�ѭ�ҡ�����ӴѺ�Ե 1 �Ѻ 0 ��ҹ��ͧ�ҧ������÷���� noise �����ҡ�繾�������Ѻ �¡���ͧẺ��� �Ե�����Ҩ��觡��� watermark bit ��� noise ��� �ѭ�ҳ���§����ͧ �й�� ��÷� watermarking ����º��ҡѺ����͡Ẻ����Ѻ��е���觷���ʹ���ͧ�Ѻ��ͧ�ҧ����� �ٻ��ҹ��ҧ�ʴ�����ͧ watermarking �繻ѭ�� communication �ѭ��˹��  ����Ѻ watermarking ��ҵ�ͧ�͡Ẻ SNR ������ҡ (SNR = Psignal/Pnoise) ��������٤��������ö���Թ�����ŷ��нѧ���ͫ� ������ͧ�ҡ SNR ��Ӥ�� bit rate ��ӵ�� (�շ���ش����������������ѡ���ºԵ����Թҷ�) ��� error rate �դ���٧ (����ҳ 10-3 �������º�Ѻ�к�����������ҧ ADSL ��������� 10-6) Spread Spectrum Signals������á ���������ô����Ԥ Spread spectrum (SS) ��㹧ҹ�ҧ��ҹ��÷��� ���Т���蹢ͧ�ѹ��� 1. �Ըչ�鷹�ҹ (robust) ��͡��ú�ǹ㹪�ǧ�������᤺ �, 2. �繡����Ẻ�ͺ � �� � ��� 3. ������ʹ���㹡���觢������ѭ�ҳ SS ���ѡɳ������� 2 ��С�� 1. bandwidth �ͧ�ѭ�ҳ SS �١�������ҧ���� bandwidth �ͧ������������ҧ�ҡ (����任���ҳ 10-100 �������Ѻ�ҹ��ҹ�ҳԪ�� ��л���ҳ 1,000 - 106 ��� ����Ѻ�ҹ��÷���) ��÷���ѧ�ҹ�ѹ���Ш�� (spread) ���ҹ�����ҧ��� ����� PSD ���ŧ ������ѭ�ҳ SS ���͡��仵աѺ�ѭ�ҳ��ҹ�������᤺����ŧ ������������ҹ�������᷺᤺�������к� SS �������� ������ҵ���Ѻ�ͧ�к����Ǻ����ѭ�ҳ��ʹ��ҹ�����ҧ�ҡ � 㹡�ô֧�������͡�� ��ʹ��ա��С�èҡ PSD ��Ӥ�� �������ö������ѹ��ӡ��� PSD �ͧ noise �� �ѹ������Ф�Ѻ����ѡɳ���㹡���觢�����Ẻ�ͺ � �� � �ͧ�ѹ 2. �ա���� spreading sequence (�ҧ�ա����¡ spreading code ���� pseudo-noise) 㹡�����ҧ�ѭ�ҳ SS ��ҹ���������ҧ�ҡ�����ŷ����� ����� spreading sequence ���е�ͧ�繷�����ѹ ���ç�ѹ ��駽������н���Ѻ �ѡɳ� 2 ���ҧ����繢�ʹ������¤�Ѻ �Ӷ�� ��ͧ���������繡���š����¹����? �ӵͺ spectral efficiency ���ͻ���Է���Ҿ�ͧ�����Ŵŧ ����Է���Ҿ�ͧ�����������ҡ�ѵ����ǹ�����ҧ�Ե�õ��� bandwidth ����Ԥ SS ������ҷ���ӡ��� 1/5 ��з���Ԥ�ҵðҹ��� � �������ͺ 1 Direct Sequence SS (DSSS)� DSSS ���� time hopping ��� �ѭ�ҳ DSSS �����ҧ�ҡ��äٳ���ФҺ���Ңͧ˹�觺Ե (bit-sized period ���� Tb) �ͧ�ѭ�ҳ������ (㹷�����ѭ�ҳ�����觤�� watermark) ���� pseudo-noise ����Сͺ�ҡ�ӴѺ�ӴѺ���ҧ�����ͧ��ū����������� ±1 ����դҺ��ҡѺ Tc �ѧ�ٻ �ٻ��� ���ش����ѭ�ҳ������ (watermark) �� Tb = 0.2 �Թҷ� �ٻ��ҧ��� pseudo-noise �� Tc = Tb/16 ����ٻ��ҧ����ѭ�ҳ SS �����ҡ��äٳ���ФҺ Tb �ͧ�ٻ�������ٻ��ҧ ����Ѻ�ٻ���� �ʴ� PSD �ͧ�ѭ�ҳ������ (���� �ٻ��Һ�) �Ѻ PSD �ͧ�ѭ�ҳ SS ����� Tc = Tb/4 ��� Tb/16 ����ӴѺ ������ Tc ��觵�� PSD ��觵�� ��з�� Tc = Tb/16 ��ӡ��� PSD �ͧ noise ��Ҥӹdz PSD �ͧ�ѭ�ҳ SS ������ҡ �ҡ�������ѭ�ҳ�����觹��������亹��������Ẻ NRZ ����Сͺ�ҡ��ū������������Һ Tb ��������Ԩٴ ± 1/Tb ��Ҩ��� ����������PSDNRZ(f) = [sinc2(fTb)]/Tb ������ͧ�ҡ�ѭ�ҳ SS �ͧ�����ѭ�ҳ NRZ ����ū��դҺ��ҡѺ Tc ��������Ԩٴ ± 1/Tb ����� ����������PSDSS(f) = [Tcsinc2(fTc)]/Tb2 �����(�ѧ���͵��ٻ����) Communication Channel Design������ҡ����� (Emitter) ���к���������ʴ��ѧ�ٻ��ҹ��ҧ �ѭ�ҳ���§ x(n) 㹷������ noise �ͧ�к� ���ѵ������������ҧ��ҡѺ Fs Hz �١��������ҡѺ v(n) �����ѭ�ҳ SS �ͧ watermark ������ҧ�Ҩҡ��äٳ (�����ʹ��ŵ) �ӴѺ�ͧ watermark (bm ∈ {0,1}) ����դ�����Ǣͧ�ӴѺ��ҡѺ M �Ե �Ѻ pseudo-noise (���� spreading sequence, c(n)) ����Сͺ���µ�����ҧ�ӹǹ Nb ��� �����¹᷹�����ǡ���� c = [c(0), c(1), ..., c(Nb - 1)]T ����ǡ���� c �������Ҩ�ѧ���������Ҩҡ������ҧ�ӴѺ������������դ��� {-1, +1} �ҷ� Walsh-Hadamard sequence ���� Gold sequence ��������� bm �����µç ���� bm ∈ {0, 1} ��ҡ��ŧ�ѹ���ѭ�ѡɳ�ش�������¡��� am = 2bm - 1 ∈ {-1, +1} ������ٳ�Ѻ c ����� vm ����������vm = amc ���;ٴ��� vm = +c ��� am = 1 (���� bm = 1) ��� vm = -c ��� am = -1 (���� bm = 0) ��ѧ�ҡ��鹨���� v(n) �Ң��´��� gain g ���ͤǺ��� SNR �����ҧ v(n) �Ѻ x(n) �������� ����觢����� (���ͽѧ������) 1 �Ե�ء � ������ҧ Nb ��� �ѧ��鹺Ե�õ R �֧�ӹdz��ҡ Fs/Nb �Ҵٷҧ��ҹ����Ѻ (Receiver) ��ҧ �ҡ�ٻ ����� ym = gvm + xm ���� ym = +gc + xm ����� am = +1 ��� ym = -gc + xm ����� am = -1 �� xm = [x(mNb, x(mNb+1), ..., x(mNb+Nb-1)]T ���ǡ����ͧ������ҧ�ͧ noise (�������§) 㹪�ͧ�ҧ������� ��� m ��� frame index ����Ѻ�Ե����Ѻ����ҡ ����������  (arg max = argument of the maximum, �ѭ�ѡɳ��ҧ�����¶֧ ��� b ������� P(b|ym) �դ���٧�ش) 㹡óշ���ͧ�ҧ�����������繪�ͧẺ AWGN (additive white Gaussian noise) ���ͪ�ͧ�ҧ���ǡ white noise (���¶֧�ѭ�ҳ��������� PSD �����) ��������Ԩٴ�ͧ noise �ա�á�Ш��Ẻ���� (���� Gaussian distribution) ��Ҵѧ����Ǩ�����šѺ��û���ҳ�ҡ����ͧ���¢ͧ�Ťٳ����� (αm) �����ҧ ym �Ѻ c ����������  ���� �����᷹��� P(b|ym) �����������ѹ��ͧ��� ����� ���������� 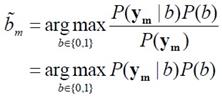 �·�� P(ym) �� priori probability �ͧ ym �������ռš�з���͡�û���ҳ��� bm ��� P(b) ��� priori probability �ͧ���Ф�ҷ�������ͧ b ���㹡óշ��������������ҡѹ �ѹ�������ռŵ�͡�û���ҳ bm �����蹡ѹ �й�� ����������  㹡óժ�ͧ�ҧ�������Ẻ AWGN ��� xm �� ��������� Gaussian Ẻ Nb-dimensional multivariate ����դ���������ҡѺ 0 �������ԡ������û�ǹ���� (covariance matrix) ��ҡѺ σx2I ����� I �������ԡ���͡�ѡɳ� Nb �Ե� �չ�� ym ���繵�������� Gaussian ����� Nb ����ô��� ���� ym = gvm + xm ���դ���������ҡѺ amgc �������ԡ������û�ǹ�������ǡѺ xm �֧�� ���������� 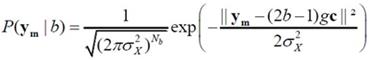 ���� ����������  ���ͧ�ҡ b ∈ {0, 1} ��蹷���� (2b - 1)2 = 1 ������ b ���դ������� ��÷Ѵ�ش���¢ͧ����ù��֧�͡��� �������ö�� bm ��ҡ ����ͧ���¢ͧ�Ťٳ�ԧ����� αm �����ҧ ym �Ѻ c ����������  �ٻ���仹���ʴ��Ҿ�óսѧ bm = 1 ŧ��ǡ�������§ x ���ǡ������ѧ�ҡ�ѧ���� y ��觤ӹdz�ҡ gv + x ���� gc + x ���� bm = 1 ��зҧ����Ѻ�еդ������ "1" ��� α > 0 �ٻ�����ʴ��ó� <x,c> �繺ǡ ��������� g ���繤�Һǡ����á��� ��������� α > 0 �й�� bm = 1 ��蹤�ʹ֧�����Ѻ��������ç�Ѻ���ѧ������ ����Ѻ�ٻ��� �繡óշ�� bm = 0 ���ͧ�ҡ <x,c> �繤��ź ��� g �����Թ� �óչ��֧�����Ѻ��������Դ�Ф�Ѻ �����ҡ����Ѻ��١ ��ͧ�ҷҧ����� g > <x,c>/|c|2 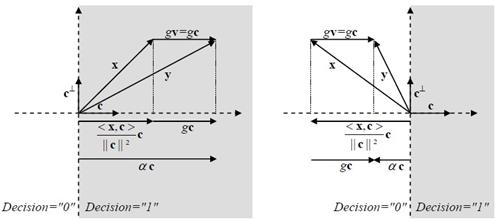 Error RatePDF �ͧ αm ��� g = 1 ��� σx2 = 20 dB �ʴ��ѧ�ٻ ����ͤ�� R ��ҡѺ 50, 100 ��� 120 ����ӴѺ (R = Fs/Nb �·���� Fs �繤�Ҥ���� 44.1 kHz �й�� �Ҩ�ٴ��� ��ҿ�����͵��������� Nb ��ҧ � �ѹ) �ٻ���¤�͡ó� b = 0 �ٻ��� b = 1 αm �繵�������� Gaussian �Ե����� ����դ������� (2bm - 1)g ��Ф����û�ǹ σx2/|c|2 ����������  ���������� ������Ҩ��繷�� αm �繺ǡ����� bm = 0 ��Ф�����Ҩ��繷�� αm ��ź����� bm = 1 �����ҡѺ�ٹ�� (���¤������ �ѹ���͡�ʷ����Ѻ���ʹ֧�Ե�͡����Դ���) �������ͤ�� R �ҡ��� (��ҿ PDF ����ŧ ��С�Ш�¡��ҧ���) ������Ҩ��繴ѧ����Ƿ�� 2 �óա������ҡ��鹵�� ������Ҩ��繷�����ҹ�����Դ��Ҵ�������ҡ ���������� 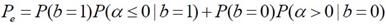 ����ѭ�ѡɳ����е���� priori probability ���ǡѹ (��蹤�� P(b=1) = P(b=0)) ������Ҩ��繢ͧ error ����ö����ҳ�����ҿ��ҹ�� �դ����ҡѺ ��鹷����Ѻ�ѹ�ͧ P(αm|bm = 0) ��� P(αm|bm = 1) �����ҨФӹdz Pe ��
�����ù������� σc2 = |c|2/Nb = ���ѧ�ͧ pseudo-noise ���� spreading sequence �»���ҳ ������ ������Ҩ��繷�����ҹ��ҼԴ�������Ѻ SNR �ͧ watermarking (= g2σc2/σx2) �Ѻ R �ٻ��ҹ��ҧ�ʴ���ҿ ���� ���͵ Q(√u) �Ѻ u ��Ҿ��͵ Pe(R) �Ѻ R ����� SNR ��ҧ � �ѹ ����� Fs = 44.1 kHz  Informed Watermarking��к�������÷������������� noise �ͧ��ͧ�ҧ���������ǧ˹�� �֧������ѹ�������ª��㹡�û�Ѻ gain ������������� ������Ѻ watermarking ��� ������Ѻ ���� noise 㹷���������§�����Ҩ������������Ҩ���������¡�ô��Ըյç仵ç�����ҧ��û�Ѻ gain ��������Ǩ�Ѻ�����������ҧ����բ�ͼԴ��Ҵ ��蹤�� �ҧ��������ͽ��������ʨе�ͧ�ա�û�Ѻ��� g ����繿ѧ���蹢ͧ�������ͪ��¤����ѹ�ǹ�ͧ���ѧẺ�ѹ�շѹ���ѭ�ҳ���§ ����ѡ�� SNR ��餧��� ��觷������ � �¡�û���ҳ��� σx2 �ͧ������§ (~ 20 ms) ���ǡ�˹���� g ����õ�� σx �������Ѻ仴١�ҿ PDF �ͧ α ������ ��ҷ���� error ��������¡�÷�����ҿ��� 2 �¡�͡��ҧ�ҡ�ѹ ��з����¡��������� g �����һ�Ѻ����� g �ͧ��������ʹ���ͧ�Ѻ ����������  �ŷ����������� error �ҧ����Ѻ������ (��ͨҡ��� ��� g ������¹��������� ��Ҩ���¹᷹ g �ͧ����������� gm) �Ըա�˹���� g �Ҩ���� ��� βm ������ͧ�������ǡѺ am ��� gm �繤�Һǡ����á��� ���� βm ������ͧ���µç�ѹ�����Ѻ am ���˹������ gm = -βm/am ���ҧ�á��� 㹷ҧ��Ժѵ� ��ͧ�ҧ������á������ noise ������ա����� �й�� �ǡ���������Ѻ���Ѻ�֧����� ym ���� ym+pm ����� ����������  �֧��ͧ�ա���������� Δg ���仴��� (Δg ��˹��ҡ�����û�ǹ�»���ҳ�ͧ�ѭ�ҳú�ǹ�ͧ��ͧ�ҧ�������) ���ͤ���������л�ʹ�������к��ѧ���� error-free �й�� gm �е�ͧ��ҹ���� ����������  �ٻ��ҹ��ҧ�ʴ� inform watermarking �ͧ�ǡ�������§ x ���١�ѧ���� "1" ����Ѿ�����ǡ���� y = gv + x = gc + x �����ҵ�ͧ���͡��� g ���ͷ���� y ������㹾�鹷���������Ң����� (�����赡㹾�鹷���� ����Ѻ�������ҹ���� "1") �ٻ�ʴ���������´ 2 �ó� �ó��á x(1) ������͡��� g ������Դź���á��� �� 0 �ǡ���� y �絡����㹾�鹷������ ����Ѻ�óշ���ͧ x(2) ��ҵ�ͧ���͡��� g �٧ � ��������ͧ�Ѻ noise ��� � 㹪�ͧ�ҧ������� ������ҧ 2Δg �١�������繪�ͧ��ҧ�����ҧ��õѴ�Թ� "1" ���� "0" �ͧ����Ѻ  ����Ѻ �ѭ�ҷ���Դ�ҡ��÷���� error-free �����Ըչ���� �س�Ҿ���§�ͧ y �е��������§�Դ���¹�ҡ������� gv ��� g �ҡ � ��ҡѺ x �ҧ�͡��ͻѭ�ҹ���������ѵ��Ѻ������§�ͧ����������Ҫ��·�������������Թ������ watermark �Ըա�ä�� ����� Psychoacoustic Model (PAM) �Ҫ���㹡�äӹdz masking threshold (��������´�ͧ PAM ������¹�֧㹺��͡���蹹Ф�Ѻ ��������ҵ��˹ѧ��ͺ���� �����¹�����Ҽ����ҹ���ѡ PAM �������ҧ������) ��蹤�� ��� PSD �ͧ watermark Sw(f) �����ӡ��� PSD �ͧ masking threshold Φ(f) �ѹ�з�������������Թ watermark ���;ٴ�ա���ҧ˹����� ���§�鹩�Ѻ���١ú�ǹ ������ͧ�ҡ����Է���Ҿ�ͧ�к� watermarking �繿ѧ���蹢ͧ SNR �й�� ����Է���Ҿ���ش����Դ��鹷�� Sw(f) = Φ(f) �������ö��������ҿ��������дѴ�ŧͧ���Сͺ�������������Ѻ��� G(f) ���� perceptual shaping filter �᷹��� gain g �ѧ�ٻ 
��� v(n) �ͧ����������ѡɳ�Ẻ���ǡѺ white noise (����������ҡѺ�ٹ����Ф����û�ǹ��������) ��û�Ѻ�������Է���ͧ�������������� output w(n) �ͧ�ѹ�� PSD Sw(f) ��� �繻ѭ���ѧ���������ͻѭ���͡Ẻ���������� � � (��ش�ͧ������ԧ��� Yule-Walker) �ҧ��ҹ����Ѻ ���ͧ���� G-1(f) �� demodulator ��չ���ջѭ����� �ѧ�Ѻ����� x(n) (�� watermarking ��Դ blind) ��� x(n) �繵�Ƿ����������ҧ G(f) �й�� G-1(f) �֧��ͧ���ҧ�����Ẻ����ҳ � �ҡ y(n) �¤�������Ӣͧ��� G-1(f) Ẻ����ҳ���������Ѻ 1. robustness �ͧ PAM ��� watermark ��� 2. noise ��� � 㹪�ͧ�ҧ������� ��ѧ�ҡ��� ��Ҥӹdz bm �������� ����ǹ����Ҵ�����ͧ���¢ͧ <zm,c> ᷹ ����� z(n) ��� output �ͧ G-1(f) �����Ҷ����������������� G-1(f) ������� � ����Ѻ�������ö�١���ҧ������Թ�����ʢͧ G(f) ���ԧ � ��Ҩ��� zm = vm + rm ����� r(n) ��� x(n) ��ѧ�ҡ��ҹ G-1(f) ����� G-1(f) (�ժ������¡ zero-forcing equalizer) ���觼���� SNR ��� output �ͧ�ѹ�դ�ҵ���ҡ ����Ǥ�� ���ѧ�ҹ�ͧ�ѭ�ҳ v(n) �դ�ҹ��� � �������º�Ѻ���ѧ�ҹ�ͧ�ѭ�ҳ���§����ҹ equalizer ���� r(n) ���ͧ�ҡ PSD �ͧ v(n) �Ѻ r(n) ᵡ��ҧ�ѹ �ѧ��� �֧�������п������ z(n) �Ẻ�����Ѿ��ҡ��ÿ������������� SNR ��觷����¡�â���ͧ���Сͺ������ͧ z(n) ������������ v(n) ���Ŵ�ͧ���Сͺ������ͧ z(n) ������������ r(n) ˹�ҷ��ѧ������繢ͧ FIR Wiener filter H(z) �ѧ�ٻ��ҧ�����������仵�ͷ��� G-1(f) ���ǹ�ͧ����͡Ẻ������������¹�֧�ա��㹺��͡���� �ѹ����ԧ ������㹺���� ��ѧ�ҡ�����¹�й� Wiener filter �ʴ������ transfer function �Ѻ �ش����� Wiener-Hopf ���ǡ稺��Ҥ��ɮ���¤�Ѻ
|
������������
|
|||||||||||||||||||||||||||
 |
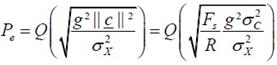
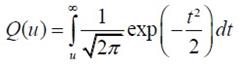






 ���Դ������͡ : 85 �� [
���Դ������͡ : 85 �� [