|
Python : Machine Learning [5]
เมื่อวานเรียนบทที่ 8 สอนเรื่อง Grouping Data
โดยใช้หลัก Split Apply Combine SAC งงส่ะ 
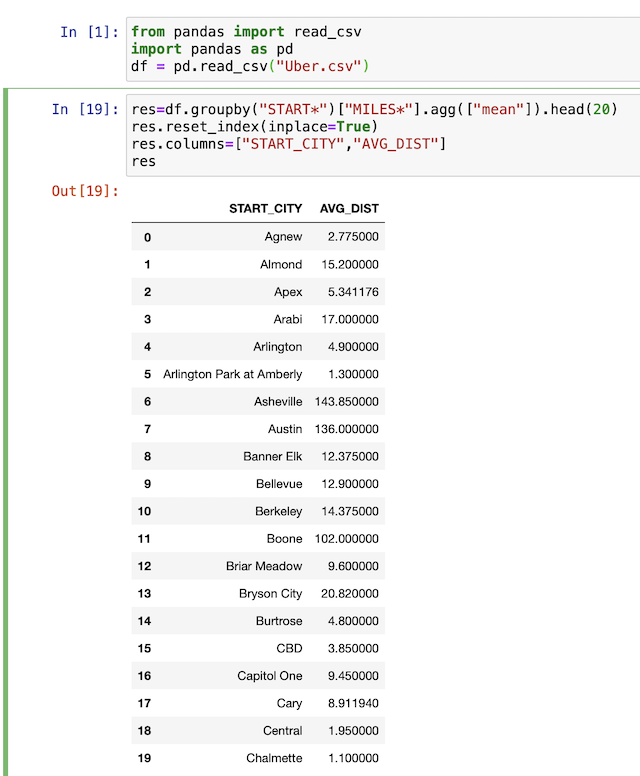
res=df.groupby("START*")["MILES*"].agg(["mean"]).head(20)
ทำ grouping ด้วย column START* แล้วนำค่า MILES* มาคำนวณค่าเฉลี่ย และให้แสดงผลเพียง 20 บรรทัด
res.reset_index(inplace=True)
res.columns=["START_CITY","AVG_DIST"]
กำหนดชื่อ column ใหม่ ให้เข้าใจง่ายขึ้น แต่ต้อง reset_index ก่อนนะ งงๆ เหมือนกัน
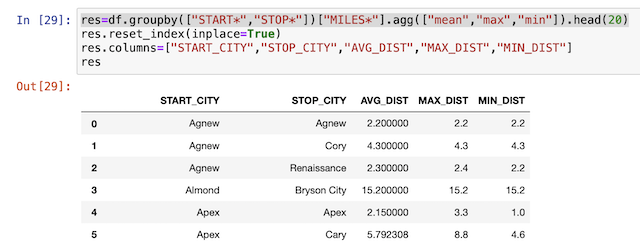
res=df.groupby(["START*","STOP*"])["MILES*"].agg(["mean","max","min"]).head(20)
เพิ่มการคำนวณหาค่า max min จาก column MILES*
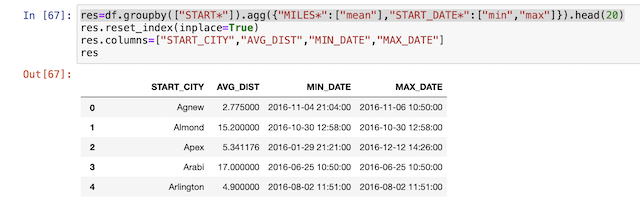
res=df.groupby(["START*"]).agg({"MILES*":["mean"],"START_DATE*":["min","max"]}).head(20)
ถ้าเราต้องการคำนวณค่า คนละcolumnกัน ต้องใช้ datetype แบบ dictionary {} แล้วกำหนดเป็นคู่ๆไป
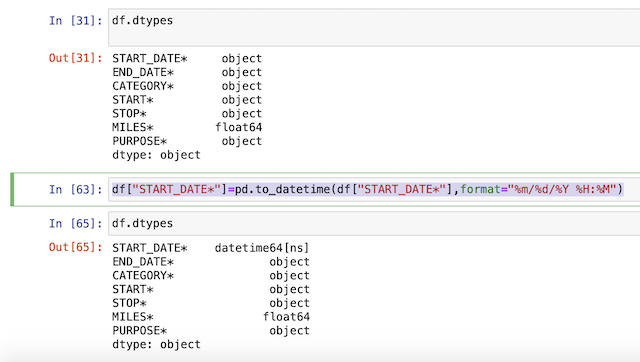
df["START_DATE*"]=pd.to_datetime(df["START_DATE*"],format="%m/%d/%Y %H:%M")
START_DATE* ต้องแปลงให้เป็น datetime ก่อน ถึงจะคำนวณได้ ถ้าทำแล้วเกิด ERROR ให้ดูข้อมูล Uber.csv ที่ให้มาว่ามีบรรทัดได้ที่รูปแบบไม่ถูกต้อง ??
ทดลองก็ประมาณรูปข้างล่างครับ
ข้างล่างแสดงการ convert datetime
| Create Date : 20 สิงหาคม 2563 | | |
| Last Update : 20 สิงหาคม 2563 21:30:22 น. |
| Counter : 1150 Pageviews. |
| |
|
| |
|


 ฝากข้อความหลังไมค์
ฝากข้อความหลังไมค์ ผู้ติดตามบล็อก : 8 คน [
ผู้ติดตามบล็อก : 8 คน [