|
|
|
Python: โหลดการ์ตูนจาก web ตอนที่ 4
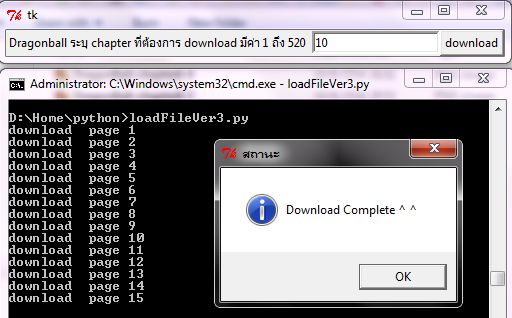
คราวนี้เป็นการรวมโปรแกรมเข้ากับ GUI แล้วระบุ Chapter ที่ต้องการ download ก็เป็นตามรูปข้างล่าง ส่วน source code ก็อยู่ตรงนี้
ลองศึกษาใน code ดูละกัน เขียนมั่วๆไปหน่อยเลยไม่ขอขยายความ

| Create Date : 10 สิงหาคม 2554 | | |
| Last Update : 10 สิงหาคม 2554 21:29:57 น. |
| Counter : 1062 Pageviews. |
| |
|
 |
|
|
|
Python: โหลดการ์ตูนจาก web ตอนที่ 3
ตอนนี้มีดูวิธีการอ่านค่า จำนวนหน้าจาก web กัน
ถ้าสังเกตดีๆ จำนวนหน้าจะอยู่ที่บรรทัดประมาณ 131 และมีคำว่า " of" เป็นที่สังเกต ดังนั้นถ้าเราไปที่ page นั้นแล้วทำอ่านค่าไปที่ละบรรทัด ให้ตรวจสอบว่าพบ คำว่า " of" ก็เก็บมาใช้งาน ต่อจากนั้นก็ทำการตัดคำ จนได้ตัวเลข ออกมา ตาม code นี้เลย หรือ download sourcecode พร้อมไฟล์จำนวนหน้าที่นี้
import urllib
#เรียกใช้ module เกี่ยวกับ web
num = 1
#เป็นค่าเริ่มต้นสำหรับ chapter เพราะเรื่อง dragonball มี 520 chapter
fpFileList01 = open('fileList01.txt','r')
#สร้าง File Pointer ที่ชี้ไปยังไฟล์ที่เก็บข้อมูลชื่อ link url แต่ละ chapter ที่ได้เขียนโปรแกรมในตอนที่ 2
fpPageList01 = open('PageList01.txt','w')
#สร้าง File pointer เก็บข้อมูลจำนวนหน้า โดยมีรูปแบบคือ เลขที่ chapter + เครื่องหมาย colon + จำนวนหน้าใน chapter นั้น
for line in fpFileList01:
fpNumPage = urllib.urlopen(line)
for lineN in fpNumPage:
if " of" in lineN:
List2 = lineN.split(" ")
List3 = List2[2].split("<")
fpPageList01.write(str(num) + ':'+List3[0]+"n")
print str(num) + ':'+List3[0]
num = num+1
break
#เป็น loop ที่อ่านค่าจากไฟล์ชือ่ 'fileList01.txt' ที่ละบรรทัดเพื่อนำไป urlopen page chapterที่ต้องการ ไล่จาก chapter ที่หนึ่งแล้วเก็บในตัวแปล fpNumPage
#ต่อจากนั้นก็อ่านข้อมูลที่ละบรรทัดจากไฟล์ที่ fpNumPage ชี้อยู่ ถ้าพบข้อความ " of" ก็ทำการเก็บบรรทัดนั้นมาส่ะ
#แล้วทำการเก็บข้อมูลจำนวนหน้าที่ตัวแปร List3[0] และจัดการ write ลงไฟล์ตาม Format ที่บอกไว้ข้างต้น
#แล้วก็ break ออกจาก loop เพื่อไปวน loop ข้างบนเพื่ออ่าน chapter ที่สองต่อไป
fpPageList01.close()
fpFileList01.close()
fp.close()
#สุดท้ายก็ไล่ปิด file Pointer ตามระเบียบ
ตอนนี้ก็ได้ข้อมูลครบแล้วคือ link chapter และจำนวนหน้า ครั้งหน้าก็จะเป็น นำข้อมูลทั้งหมดไปใส่เป็นแบบ GUI เพื่อง่ายต่อการใช้งาน
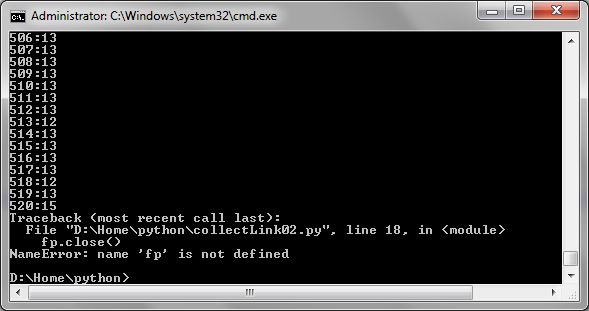
ถ้าสังเกตจะเป็นว่ามี error ตอน run ก็เพราะว่าบรรทัดสุดท้ายเป็นบรรทัดเปล่า มันไปหา url ไม่เจอ ถ้าไม่ต้องการให้error ก็ลบบรรทัดเปล่าทิ้ง
| Create Date : 31 กรกฎาคม 2554 | | |
| Last Update : 31 กรกฎาคม 2554 8:58:49 น. |
| Counter : 1293 Pageviews. |
| |
|
| |
|
|
|
Python: โหลดการ์ตูนจาก web ตอนที่ 2
จากครั้งที่แล้วก็สามารถโหลดภาพการ์ตูนได้แล้ว แต่ก็ไม่ค่อยสะดวกเพราะต้องมาเปลี่ยน link เรื่อย และเปลี่ยนจำนวนหน้า ดังนั้นมาครั้งนี้เลยเขียนโปรแกรมเพื่อดึงชื่อ link ทั้งหมดมา ใส่ในไฟล์ชื่อ fileList01.txt และดึงข้อมูลจำนวนหน้ามาเก็บที่ไฟล์ pageList01.txt ซึ่งหลักการก็คล้ายๆกับครั้งที่แล้ว
ก่อนอื่นมาดูวิธี load link ทั้งหมดมาก่อนนะครับ อืมที่ทดลองนี้ใช้กับ การ์ตูนเรื่อง dragonball นะครับ ถ้าเรื่องอื่นๆ ก็ไปแก้ไขcode ตามความเหมาะสมเองละกัน
มาดู code และคำอธิบาย ในโปรแกรม collectLink01.py
import urllib
#load module มาใช้งาน
url = "//www.mangareader.net/105/dragon-ball.html"
fp = urllib.urlopen(url)
#สร้าง File pointer ชี้ไปยัง url ที่กำหนด อันนี้เป็นหน้าแรกของdragonball ซึ่งจะมี link ไปทุกตอน 520 ตอน
startFromLine = 157
lineCount = 1
for line in fp:
if lineCount > startFromLine:
break
lineCount = lineCount+1
#เนื่องจาก Link จะเริ่มที่ประมาณบรรทัดที่ 157 กลุ่มคำสั่งนี้จึงมีหน้าที่ เลื่อนบรรทัดไปเรื่อยๆ จนกระทั่งถึงบรรทัดที่ประมาณ 157
fpWrite = open('fileList01.txt','w')
#สร้าง File Pointer เพื่อจะเก็บข้อมูล
for line in fp:
if "dragon-ball" in line:
strRead = line
print line
List = strRead.split('"')
fpWrite.write("//www.mangareader.net"+List[1]+"n")
#วน loop หาบรรทัดที่มีคำว่า dragon-ball เพื่อจะตัดเอา link url มาใช้งาน และเขียนข้อมูลลงไฟล์ เป็นอันจบ ซึงถ้าเราไม่เลื่อนบรรทัดมาจนประมาณ 157 บรรทัดจะมีคำว่า dragon-ball ที่ไม่ใช่ link url อยู่ ทำให้การเก็บข้อมูลผิดพลาดได้
fpWrite.close()
fp.close()
#ปิดไฟล์ที่ใช้งาน
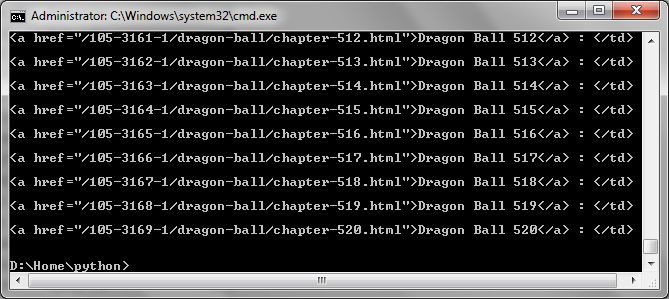
อันนี้เป็น sourcecode และ textfile ที่เก็บ link มาให้แล้วถ้าขี้เกียจ run program
| Create Date : 30 กรกฎาคม 2554 | | |
| Last Update : 30 กรกฎาคม 2554 8:34:49 น. |
| Counter : 993 Pageviews. |
| |
|
| |
|
|
|
Python อ่านข้อมูล text File (Lexitron)
คราวนี้มาลองใช้ python อ่านข้อมูล text file ดู ไฟล์ที่ใช้ก็คือ ไฟล์ dict Lexitron จาก //lexitron.nectec.or.th/2009_1/
เมื่อ d/l มาแล้วจะมีไฟล์ชื่อ etlex ซึ่งจะเป็นมูลแบบ xml แต่เวลาอ่านไฟล์จะพบปัญหามี code 0xfc
อยู่ 7 จุด ซึ่งไม่รู้มาได้อย่างไร และจาก //www.ascii.ca/cp874.htm จะพบว่า
ascii code ที่ใช้งานจะมีตั้งแต่ 0x20-0xFB ดังนั้นจึงใช้โปรแกรม hex edit replace ให้เป็น 0x5F ?
การอ่านไฟล์ก็ง่ายมาก ตามนี้เลย
from Tkinter import *
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
root = Tk()
L1 = Label(root, text = 'Begin' + 'n')
L1.pack()
#เปิดไฟล์ แบบอ่านอย่างเดียว
f = open('etlex-test','r')
while 1:
#อ่านที่ละบรรทัด
line = f.readline().decode('TIS-620')
L1['text'] = L1['text']+ line + "n"
#ตรวจสอบว่า eof หรือไม่
if line == '' :
L1['text'] = L1['text']+'END OF FILE' + "n"
break
#ปิดไฟล์
f.close
root.mainloop()
=======================
คำสั่งนี้ f.readline().decode('TIS-620') ต้องใส่ decode ด้วยเนื่องจากไฟล์ที่เก็บข้อมูล
เป็นแบบ ascii ไม่งั้นจะอ่านไม่รู้เรื่อง
ผลลัพธ์ ก็จะประมาณนี้

| Create Date : 13 มิถุนายน 2554 | | |
| Last Update : 13 มิถุนายน 2554 20:41:25 น. |
| Counter : 2419 Pageviews. |
| |
|
| |
|
|
|
|
|
|











 ฝากข้อความหลังไมค์
ฝากข้อความหลังไมค์ ผู้ติดตามบล็อก : 8 คน [
ผู้ติดตามบล็อก : 8 คน [