|
|
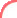 |
 |
 |
 |
| |
2. การจัดการกับข้อมูล
1. การเก็บข้อมูล (Data Acquisition)
2. การบันทึกข้อมูล (Data Entry)
3. การตรวจสอบความถูกต้องของข้อมูล (Data Edit)
4. การจัดแฟ้มข้อมูล (Filing)
5. การประมวลผล (Data Processing)
การประมวลผลข้อมูลในระบบคอมพิวเตอร์แบ่งเป็น 3 วิธีใหญ่ ๆ ดังนี้
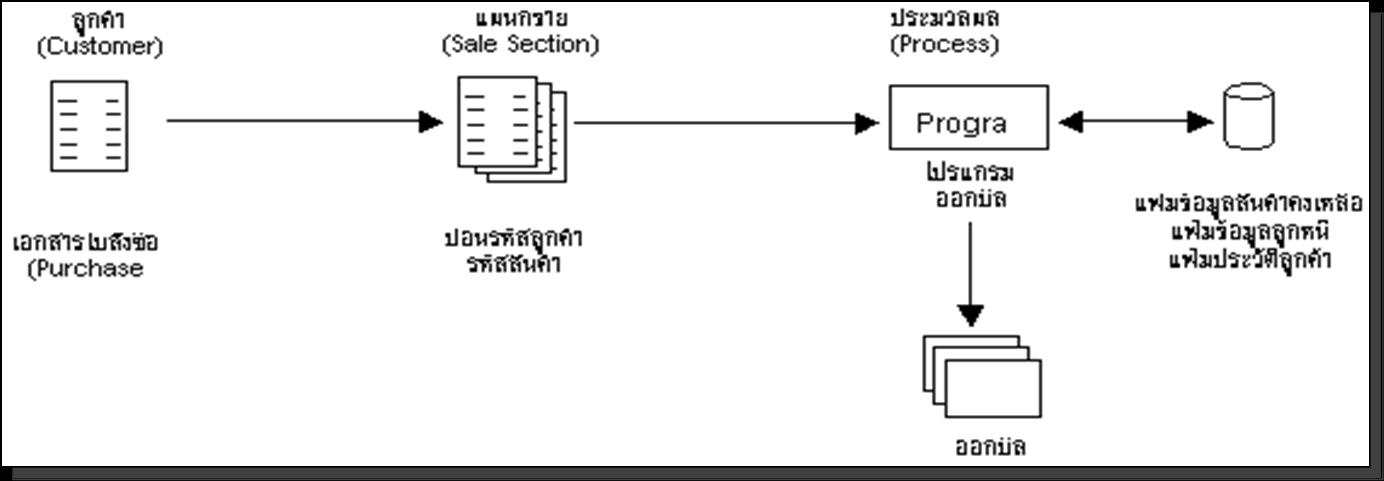
5.1. ระบบประมวลผลแบบกลุ่ม (Batch Processing) คือ การประมวลผลโดยผู้ใช้จะทำการรวบรวมเอกสารที่ต้องการประมวลผลไว้เป็นชุด ๆ ซึ่งเอกสารแต่ละชุดต้องให้มีขนาดเท่ากัน

5.2. ระบบประมวลผลแบบโต้ตอบ (Transaction Processing) หมายถึงการทำงานในลักษณะที่มีการโต้ตอบระหว่างผู้ใช้กับเครื่องคอมพิวเตอร์ โดยผู้ใช้สามารถที่จะตรวจสอบข้อมูลได้ตลอดเวลา
5.3. ระบบประมวลผลแบบออนไลน์ (Online Processing) คือ การประมวลผลร่วมกันระหว่างคอมพิวเตอร์ที่ต่อพ่วงกับระบบสื่อสาร (Communication) โดยอาศัยอุปกรณ์ต่อพ่วง เช่น โมเด็ม (Modem) ซึ่งลักษณะการทำงานอาจจะมีเครื่องคอมพิวเตอร์หลายเครื่องต่อพ่วงกันในระบบเครือข่าย (Network)

6. การสอบถามและค้นคืนข้อมูล(Data Query and Data Retrieval)
7. การปรับข้อมูลให้เป็นปัจจุบัน (Update)
8. การจัดทำรายงาน (Reporting)
9. การทำสำเนา (Duplication)
10. การสำรองข้อมูล (Backup)
11. การกู้ข้อมูล (Data Recovery)
12. การสื่อสารข้อมูล (Data Communication)
13. การทำลายข้อมูล (Data Scraping)
14. การจัดการไฟล์
วิธีการจัดการไฟล์ของข้อมูลในสื่อบันทึกข้อมูล มี 3 วิธีใหญ่ ๆ คือ
14.1. การจัดแฟ้มข้อมูลแบบเรียงลำดับ (Sequential File)
14.2. การจัดแฟ้มข้อมูลแบบสุ่มหรือแบบโดยตรง(Random/direct File)
14.3. การจัดแฟ้มข้อมูลแบบลำดับเชิงดัชนี(Indexed Sequential File)
การเข้าถึงข้อมูล
การเข้าถึงโดยลำดับ (Sequential Access)
เป็นการเข้าถึงข้อมูลทีละเรคคอร์ดเรียงไปตามลำดับของการจัดเก็บ ถ้าจะดึงข้อมูลเรคคอร์ดที่ 10 มาใช้จะต้องอ่านข้อมูลผ่านเรคคอร์ดที่ 1 ถึง 9 ก่อนเสมอ เมื่อถึงเรคคอร์ดที่ 10 จึงจะสามารถดึงข้อมูลออกมาใช้ได้ สื่อที่ใช้ในการบันทึกข้อมูลแบบนี้มักเป็น เทป (Tape)

การเข้าถึงโดยสุ่ม (Random Access)
เป็นการเข้าถึงข้อมูลที่ต้องการได้ทันที ไม่ต้องผ่านเรคคอร์ดที่อยู่ก่อน การเข้าถึงเรคคอร์ดแบบสุ่มจะเร็วกว่าแบบโดยลำดับมาก เหมาะสมกับงานที่ต้องการความเร็วในการดึงข้อมูลมาก ๆ สื่อที่ใช้ในการเก็บข้อมูลมักเป็นดิสก์ หรือจานแม่เหล็ก

แบบฝึกหัด
2.1. อธิบายวิธีการเข้าถึงแบบสุ่ม และแบบลำดับ
2.2. การประมวลผลมีกี่วิธีอะไรบ้าง พร้อมทั้งอธิบายมาพอสังเขป
| Create Date : 11 มิถุนายน 2552 |
| Last Update : 12 มิถุนายน 2552 10:15:08 น. |
|
144 comments
|
| Counter : 9578 Pageviews. |
 |
|
|
| โดย: นศ.ณัฐชนันท์พร ศรีบุญเรือง (หมู่08 เช้า พฤ ) IP: 172.29.85.18, 58.137.131.62 วันที่: 11 มิถุนายน 2552 เวลา:15:32:31 น. |
|
|
|
| โดย: นายพงษ์ระวี รีชัยวิจิตรกุล ม22 อังคารเช้า IP: 192.168.1.111, 124.157.230.25 วันที่: 14 มิถุนายน 2552 เวลา:12:50:20 น. |
|
|
|
| โดย: นายพงษ์ระวี รีชัยวิจิตรกุล ม22 อังคารเช้า IP: 192.168.1.111, 124.157.230.25 วันที่: 14 มิถุนายน 2552 เวลา:12:52:19 น. |
|
|
|
| โดย: นายพงษ์ระวี รีชัยวิจิตรกุล ม22 อังคารเช้า IP: 192.168.1.111, 124.157.230.25 วันที่: 14 มิถุนายน 2552 เวลา:12:56:34 น. |
|
|
|
| โดย: นายพงษ์ระวี รีชัยวิจิตรกุล ม22 อังคารเช้า IP: 192.168.1.111, 124.157.230.25 วันที่: 14 มิถุนายน 2552 เวลา:12:59:55 น. |
|
|
|
| โดย: โดยนางสาวเบญจมาศ ปวงสุข หมู่ 1 เรียนจันทร์บ่าย IP: 114.128.130.15 วันที่: 15 มิถุนายน 2552 เวลา:19:11:00 น. |
|
|
|
| โดย: นางสาวอรธิรา บัวลา บช.บ. 1/3 หมู่ 29 เรียนวันพุธ คาบ 2 - 5 เมล์ manay_manay@hotmail.com IP: 113.53.161.51 วันที่: 17 มิถุนายน 2552 เวลา:21:51:49 น. |
|
|
|
| โดย: นางสาวอรธิรา บัวลา บช.บ. 1/3 หมู่ 29 เรียนวันพุธ คาบ 2 - 5 เมล์ manay_manay@hotmail.com IP: 113.53.161.51 วันที่: 17 มิถุนายน 2552 เวลา:22:00:28 น. |
|
|
|
| โดย: นางสาวอรธิรา บัวลา บช.บ. 1/3 หมู่ 29 เรียนวันพุธ คาบ 2 - 5 เมล์ manay_manay@hotmail.com IP: 113.53.161.51 วันที่: 17 มิถุนายน 2552 เวลา:22:00:29 น. |
|
|
|
| โดย: นางสาววิภาวี พลวี (หมู่ 08 พฤ เช้า ) IP: 172.29.9.59, 202.29.5.62 วันที่: 18 มิถุนายน 2552 เวลา:8:22:21 น. |
|
|
|
| โดย: นางสาวปวีณา บรรยงค์ เรียนจันทร์-บ่าย หมู่1 รหัส50040302112 IP: 172.29.9.56, 202.29.5.62 วันที่: 22 มิถุนายน 2552 เวลา:14:53:19 น. |
|
|
|
| โดย: น.ส.นิตยา กลิ่นเมือง ( หมู่ที่ 15 ศ. เช้า) IP: 172.29.6.10, 202.29.5.62 วันที่: 26 มิถุนายน 2552 เวลา:9:54:20 น. |
|
|
|
| โดย: ศุภชัย จันทาพูน IP: 125.26.164.252 วันที่: 28 มิถุนายน 2552 เวลา:19:54:28 น. |
|
|
|
| โดย: ศุภชัย จันทาพูน IP: 125.26.164.252 วันที่: 28 มิถุนายน 2552 เวลา:19:56:27 น. |
|
|
|
| โดย: นางสาวเกศรินทร์ ไชยปัญญา หมู่( 08 พฤ เช้า) IP: 172.29.85.71, 58.137.131.62 วันที่: 29 มิถุนายน 2552 เวลา:15:10:42 น. |
|
|
|
| โดย: น.ส. วริศรา ทิมแดง (ม.08 พฤ . เช้า ) IP: 172.29.85.71, 202.29.5.62 วันที่: 30 มิถุนายน 2552 เวลา:9:47:02 น. |
|
|
|
| โดย: น.ส. วริศรา ทิมแดง (ม.08 พฤ . เช้า ) IP: 172.29.85.71, 202.29.5.62 วันที่: 30 มิถุนายน 2552 เวลา:9:54:10 น. |
|
|
|
| โดย: นายวีระวิทย์ นาคเสน เรียน วันจันทร์ บ่าย หมู่ 1 IP: 58.147.38.208 วันที่: 3 กรกฎาคม 2552 เวลา:15:19:29 น. |
|
|
|
| โดย: นางสาวเจนจิรา จุตตะโน หมู่8 พฤหัส(เช้า) รหัส 52040302126 IP: 1.1.1.236, 58.137.131.62 วันที่: 3 กรกฎาคม 2552 เวลา:17:51:00 น. |
|
|
|
| โดย: นางสาวสมฤทัย ราชอินทร์ หมู่01 (พิเศษ) เรียนพฤหัสบดีค่ำ รหัสนักศึกษา 52240501127 IP: 125.26.166.48 วันที่: 4 กรกฎาคม 2552 เวลา:14:24:28 น. |
|
|
|
| โดย: นางสาว ปาริสา แคนหนอง 52040332140 หมู่ 15 ศุกร์ (เช้า) IP: 125.26.233.224 วันที่: 5 กรกฎาคม 2552 เวลา:23:42:55 น. |
|
|
|
| โดย: นางสาว อนุสรา แคนหนอง 52040332139 หมู่เรียน 15 ศุกร์ เช้า IP: 125.26.233.224 วันที่: 5 กรกฎาคม 2552 เวลา:23:52:39 น. |
|
|
|
| โดย: 52040281122 ชื่อนางสาวณัฐติยา โกศิลา หมู่08 (วันพฤหัสบดีเช้า) สาขาชีววิทยา (จุลชีววิทยา) IP: 125.26.162.248 วันที่: 8 กรกฎาคม 2552 เวลา:15:39:47 น. |
|
|
|
| โดย: น.ส. กนกอร เสริฐดิลก หมู่15 ศุกร์เช้า รหัส 52040332133 IP: 192.168.1.107, 124.157.145.204 วันที่: 10 กรกฎาคม 2552 เวลา:16:10:54 น. |
|
|
|
| โดย: นางสาว อุไรวรรณ หาญศึก หมู1(พิเศษ)พฤหัส (ค่ำ) IP: 113.53.166.202 วันที่: 11 กรกฎาคม 2552 เวลา:12:37:59 น. |
|
|
|
| โดย: นางสาว อุไรวรรณ หาญศึก หมู1(พิเศษ)พฤหัส (ค่ำ) IP: 113.53.166.202 วันที่: 11 กรกฎาคม 2552 เวลา:12:45:50 น. |
|
|
|
| โดย: นางสาว อุไรวรรณ หาญศึก หมู1(พิเศษ)พฤหัส (ค่ำ) IP: 113.53.166.202 วันที่: 11 กรกฎาคม 2552 เวลา:12:47:52 น. |
|
|
|
| โดย: นางสาวศศิวิมล ภาณุพงศ์ภูสิทธิ์ หมู่ 8(พฤหัสเช้า) IP: 1.1.1.229, 58.137.131.62 วันที่: 11 กรกฎาคม 2552 เวลา:13:38:17 น. |
|
|
|
| โดย: น.ส.วิภาดา นาสิงห์ขันธ์ หมู่8(พฤหัสเช้า) IP: 1.1.1.141, 202.29.5.62 วันที่: 11 กรกฎาคม 2552 เวลา:23:38:33 น. |
|
|
|
| โดย: น.ส.วิภาดา นาสิงห์ขันธ์ หมู่8(พฤหัสเช้า) IP: 1.1.1.141, 202.29.5.62 วันที่: 11 กรกฎาคม 2552 เวลา:23:41:17 น. |
|
|
|
| โดย: นางสาวอรนิดา วรินทรา ม. 15 ศ.เช้า IP: 192.168.1.103, 125.26.167.254 วันที่: 13 กรกฎาคม 2552 เวลา:14:14:23 น. |
|
|
|
| โดย: นส.บลสิการ ดอนโสภา หมู่15 ศุกร์เช้า รหัส 52041151217 IP: 192.168.1.115, 125.26.167.254 วันที่: 13 กรกฎาคม 2552 เวลา:14:39:18 น. |
|
|
|
| โดย: นางสาววิภายี กลางหล้า ม. 15 ศุกร์เช้า IP: 192.168.1.102, 125.26.167.254 วันที่: 13 กรกฎาคม 2552 เวลา:15:06:16 น. |
|
|
|
| โดย: นางสาว ธัญธิตา แก้วมีศรี ม. 15 ศุกร์เช้า 52041151239 IP: 192.168.1.104, 125.26.167.254 วันที่: 13 กรกฎาคม 2552 เวลา:15:24:29 น. |
|
|
|
| โดย: นายบดินทร์ แก้วมีศรี หมู่ 01 (พิเศษ) 52240210214 สาธารณสุขศาสตร์ IP: 119.42.83.148 วันที่: 13 กรกฎาคม 2552 เวลา:20:18:22 น. |
|
|
|
| โดย: นายบดินทร์ แก้วมีศรี หมู่ 01 (พิเศษ) 52240210214 สาธารณสุขศาสตร์ IP: 119.42.83.148 วันที่: 13 กรกฎาคม 2552 เวลา:20:19:46 น. |
|
|
|
| โดย: นางสาววิภาวี พลวี ( 08 พฤ เช้า ) IP: 125.26.169.73 วันที่: 15 กรกฎาคม 2552 เวลา:14:35:04 น. |
|
|
|
| โดย: นางสาว สุทธิดา ยาโย 52240210217 วัน พฤหัสฯค่ำ หมู่ 1 IP: 119.42.82.8 วันที่: 15 กรกฎาคม 2552 เวลา:16:10:11 น. |
|
|
|
| โดย: นางสาว สุทธิดา ยาโย 52240210217 วัน พฤหัสฯค่ำ หมู่ 1 IP: 119.42.82.8 วันที่: 15 กรกฎาคม 2552 เวลา:16:15:57 น. |
|
|
|
| โดย: โดยน.ส อังคณา สุทธิแพทย์52240210209หมู่01(พิเศษ)พฤ.ค่ำสาขา สาธารณสุขศาสตร์ IP: 119.42.82.8 วันที่: 15 กรกฎาคม 2552 เวลา:16:44:38 น. |
|
|
|
| โดย: โดยน.ส อังคณา สุทธิแพทย์52240210209หมู่01(พิเศษ)พฤ.ค่ำสาขา สาธารณสุขศาสตร์ IP: 119.42.82.8 วันที่: 15 กรกฎาคม 2552 เวลา:16:51:04 น. |
|
|
|
| โดย: นายนภศักดิ์ ชาทอง ม.29 พุธเช้า IP: 119.31.110.169 วันที่: 16 กรกฎาคม 2552 เวลา:18:29:52 น. |
|
|
|
| โดย: นางสาวนงลักษณ์ ทุมลา 51040325135 หมู่01 จันทร์บ่าย IP: 114.128.221.34 วันที่: 19 กรกฎาคม 2552 เวลา:16:59:09 น. |
|
|
|
| โดย: นางสาวนงลักษณ์ ทุมลา 51040325135 หม่01 จันทร์บ่าย IP: 114.128.221.34 วันที่: 19 กรกฎาคม 2552 เวลา:17:06:25 น. |
|
|
|
| โดย: นางสาวภัทราภรณ์ อุ่นจิต 52240236104 พฤ-ค่ำ(พิเศษ) IP: 172.29.5.133, 202.29.5.62 วันที่: 23 กรกฎาคม 2552 เวลา:18:12:38 น. |
|
|
|
| โดย: นายอดิศักดิ์ รักวิชา ม.1(พิเศษ) พฤ.ค่ำ 52240427132 IP: 117.47.10.111 วันที่: 24 กรกฎาคม 2552 เวลา:5:55:15 น. |
|
|
|
| โดย: นายนิรัช วิจิตรกุล ม.1(พิเศษ) พฤ.ค่ำ 52240427117 IP: 117.47.10.111 วันที่: 24 กรกฎาคม 2552 เวลา:5:56:02 น. |
|
|
|
| โดย: น.ส.ชฎาพร โสภาคำ ชีววิทยา (จุลชีววิทยา) ม.08 พฤ (เช้า) 52040281117 IP: 124.157.148.182 วันที่: 25 กรกฎาคม 2552 เวลา:12:30:29 น. |
|
|
|
| โดย: นางสาวจิลวรรณ ปัดถาวะโร รหัส 52040281130 ม. 08 ( พฤ.เช้า ) IP: 124.157.148.182 วันที่: 25 กรกฎาคม 2552 เวลา:12:59:16 น. |
|
|
|
| โดย: น.ส วนิดา ปัตตานี เช้าวันศุกร์ หมู่15 IP: 172.29.5.133, 202.29.5.62 วันที่: 26 กรกฎาคม 2552 เวลา:18:08:44 น. |
|
|
|
| โดย: น.ส วนิดา ปัตตานี เช้าวันศุกร์ หมู่15 IP: 172.29.5.133, 202.29.5.62 วันที่: 26 กรกฎาคม 2552 เวลา:18:19:00 น. |
|
|
|
| โดย: นางสาวสุพัตรา ธรรมสาร(หมู่15ศ.เช้า)52040302208 IP: 222.123.62.82 วันที่: 28 กรกฎาคม 2552 เวลา:0:33:54 น. |
|
|
|
| โดย: น.ส.วิไลวรรณ พงค์พันธ์ ม.29 (พุธเช้า) 52040501303 IP: 222.123.231.163 วันที่: 28 กรกฎาคม 2552 เวลา:21:39:45 น. |
|
|
|
| โดย: น.ส.วิไลวรรณ พงค์พันธ์ ม.29 (พุธเช้า) 52040501303 IP: 222.123.231.163 วันที่: 28 กรกฎาคม 2552 เวลา:21:42:57 น. |
|
|
|
| โดย: น.สผกาพรรณ หงษ์ทอง หมู่1 จันทร์-บ่าย IP: 124.157.146.74 วันที่: 29 กรกฎาคม 2552 เวลา:19:51:14 น. |
|
|
|
| โดย: นาย สุระทิน ใจใส หมู่ 15 ศุกร์เช้า รหัส 52041151202 IP: 1.1.1.171, 58.147.7.66 วันที่: 29 กรกฎาคม 2552 เวลา:21:00:34 น. |
|
|
|
| โดย: สุจิตรา มหาฤทธิ์ 51040305111 สาขาภาษาอังกฤษธุรกิจ หมู่ 01 จันทร์บ่าย IP: 172.29.5.133, 58.137.131.62 วันที่: 30 กรกฎาคม 2552 เวลา:18:24:01 น. |
|
|
|
| โดย: นายนิติธรรม พฤหัส เช้า หมู่ 08 IP: 1.1.1.4, 202.29.5.62 วันที่: 30 กรกฎาคม 2552 เวลา:23:38:20 น. |
|
|
|
| โดย: นางสาวอังสุมารินทร์ ลุนินิมิตร (ม15 ศ. เช้า) IP: 172.29.5.133, 58.137.131.62 วันที่: 31 กรกฎาคม 2552 เวลา:9:26:11 น. |
|
|
|
| โดย: นายอรรคพล วิทิยาเทคโนผลิตพืชอังคารเช้าหมู่22 IP: 125.26.167.27 วันที่: 1 สิงหาคม 2552 เวลา:19:20:07 น. |
|
|
|
| โดย: น.ส ผกาพรรณ หงษ์ทอง หมู่ 1 จันทร์-บ่าย IP: 124.157.146.209 วันที่: 3 สิงหาคม 2552 เวลา:15:25:20 น. |
|
|
|
| โดย: น.ส ผกาพรรณ หงษ์ทอง หมู่ 1 จันทร์-บ่าย IP: 124.157.146.209 วันที่: 3 สิงหาคม 2552 เวลา:15:29:05 น. |
|
|
|
| โดย: ธวัชชัย นิวาสธนชัย 52040001162 (พุธ เช้า) IP: 124.157.146.209 วันที่: 4 สิงหาคม 2552 เวลา:14:40:36 น. |
|
|
|
| โดย: เติมศักดิ์ พงษ์มา 52040001153 (พุธ เ้ช้า) IP: 124.157.146.209 วันที่: 4 สิงหาคม 2552 เวลา:14:42:22 น. |
|
|
|
| โดย: นาย สุระทิน ใจใส รหัส 52041151202 หมุ่15 ศุกร์เช้า IP: 202.29.5.62 วันที่: 4 สิงหาคม 2552 เวลา:18:59:37 น. |
|
|
|
| โดย: นางสาวสุภาพร รัตนา 50240210102 วท.บ.สาธารณสุขศาสตร์ (เรียน พฤ-ค่ำ เวลา 17.00-21.00 น. ) IP: 114.128.22.96 วันที่: 5 สิงหาคม 2552 เวลา:12:05:54 น. |
|
|
|
| โดย: นายนารายณ์ แก้วภักดี ม. 15 ศ.เช้า IP: 124.157.129.16 วันที่: 10 สิงหาคม 2552 เวลา:17:24:00 น. |
|
|
|
โดย: อ.น้ำผึ้ง (neaup  ) วันที่: 11 สิงหาคม 2552 เวลา:11:30:14 น. ) วันที่: 11 สิงหาคม 2552 เวลา:11:30:14 น. |
|
|
|
| โดย: 52040263105 ชื่อ.น.ส.อรวรรณ ไชยยงค์ สาขาวิชาวิทยาศาสตร์และเทคโนโลยีการอาหาร หมู่22 (อังคารเช้า) IP: 124.157.149.216 วันที่: 12 สิงหาคม 2552 เวลา:13:33:26 น. |
|
|
|
| โดย: นางสาวชลดา บุญรุ่ง (หมู่8 พฤหัส เช้า) IP: 172.29.5.133, 58.147.7.66 วันที่: 15 สิงหาคม 2552 เวลา:13:44:42 น. |
|
|
|
| โดย: นางสาวชลดา บุญรุ่ง (หมู่8 พฤหัส เช้า) IP: 172.29.5.133, 58.147.7.66 วันที่: 15 สิงหาคม 2552 เวลา:13:47:00 น. |
|
|
|
| โดย: อภิญญา อุ้ยปะโค IP: 117.47.128.146 วันที่: 15 สิงหาคม 2552 เวลา:15:04:45 น. |
|
|
|
| โดย: นางสาวคนึงนิจ ผิวบาง หมู่22 IP: 124.157.148.178 วันที่: 17 สิงหาคม 2552 เวลา:19:27:13 น. |
|
|
|
| โดย: นางสาว นงนุช นาเจริญ 52040258129 หมู่22 อังคารเช้า IP: 1.1.1.182, 58.147.7.66 วันที่: 20 สิงหาคม 2552 เวลา:19:22:57 น. |
|
|
|
| โดย: นางสาว นฤมล หมู่หาญ 52040263122 หมู่22 อังคารเช้า IP: 1.1.1.182, 58.147.7.66 วันที่: 20 สิงหาคม 2552 เวลา:19:33:59 น. |
|
|
|
| โดย: นางสาวสุจิตรา อินทสร้อย 52040258139 หมู่22 อังคารเช้า IP: 124.157.144.104 วันที่: 22 สิงหาคม 2552 เวลา:14:41:13 น. |
|
|
|
| โดย: นายวรวัฒน์ ศรีใจ 52040332110 พฤหัส เช้า หมู่ 08 IP: 202.29.5.62 วันที่: 27 สิงหาคม 2552 เวลา:18:11:44 น. |
|
|
|
| โดย: นายอัศวิน บัวน้ำอ้อม 51241151118 รูปแบบพิเศษหมู่ 5 วันเสาร์บ่ายโมง IP: 172.29.5.133, 58.137.131.62 วันที่: 29 สิงหาคม 2552 เวลา:14:06:53 น. |
|
|
|
| โดย: นางสาววินภา พินิจมนตรี รหัส 51241151116 รูปแบบพิเศษหมู่ 5 วันเสาร์บ่ายโมง IP: 172.29.5.133, 58.147.7.66 วันที่: 29 สิงหาคม 2552 เวลา:14:08:23 น. |
|
|
|
| โดย: นาย ปิยะ ศรีกุลวงศ์ เสาร์บ่าย 51241151204 IP: 222.123.59.23 วันที่: 31 สิงหาคม 2552 เวลา:13:24:55 น. |
|
|
|
| โดย: นาย ปิยะ ศรีกุลวงศ์ เสาร์บ่าย 51241151204 IP: 222.123.59.23 วันที่: 31 สิงหาคม 2552 เวลา:13:50:19 น. |
|
|
|
| โดย: นางาสาว สมร นาแพงหมื่น เสาร์บ่าย 51241151220 IP: 114.128.133.6 วันที่: 31 สิงหาคม 2552 เวลา:16:18:10 น. |
|
|
|
| โดย: นางฉวีวรรณ แสงเลิศ 51241151132 รูปแบบพิเศษ รปศ. เรียนเวลา บ่ายโมงวันเสาร์ IP: 117.47.14.74 วันที่: 1 กันยายน 2552 เวลา:19:30:40 น. |
|
|
|
| โดย: นางสาวลำไพ พูลเกษม (ศุกร์ เช้า หมู่เรียนที่ 15) IP: 1.1.1.40, 58.137.131.62 วันที่: 1 กันยายน 2552 เวลา:20:00:34 น. |
|
|
|
| โดย: นางสาวสุกัญญา แก้วคูณเมือง รหัส 51241151122 (เรียนวันเสาร์บ่ายโมง) IP: 10.0.100.48, 125.26.246.123 วันที่: 2 กันยายน 2552 เวลา:22:02:49 น. |
|
|
|
| โดย: นาย สุระทิน ใจใส หมู่ 15 ศุกร์เช้า รหัส 52041151202 IP: 172.29.5.133, 202.29.5.62 วันที่: 4 กันยายน 2552 เวลา:10:57:54 น. |
|
|
|
| โดย: นางสาวกฤติยา เหล่าผักสาร รหัสนักศึกษา 52040263134 คณะเทคโนโลยี สาขาวิชาวิทยาศาสตร์และเทคโนโลยีการอาหาร IP: 125.26.170.66 วันที่: 5 กันยายน 2552 เวลา:15:01:06 น. |
|
|
|
| โดย: นางสาวเกษร อัครฮาด รหัสนักศึกษา 52040003135 หมู่ 29 เรียนพุธเช้า IP: 110.49.98.71 วันที่: 7 กันยายน 2552 เวลา:18:18:35 น. |
|
|
|
| โดย: นางสาวกฤติยา เหล่าผักสาร รหัสนักศึกษา 52040263134 หมู่ 22 อังคารเช้า คณะเทคโนโลยี สาขาวิชาวิทยาศาสตร์และเทคโนโลยีการอาหาร IP: 172.29.5.133, 58.147.7.66 วันที่: 8 กันยายน 2552 เวลา:9:20:16 น. |
|
|
|
| โดย: ชื่อ นายวัชระพงศ์ โคตรชมภู รหัสนักศึกษา 51040901205 หมู่ที่1จันทร์(บ่าย)สาขาวิชานิติศาสตร์คณะมนุษยศาสตร์และสังคมศาสตร์ IP: 172.29.5.133, 58.147.7.66 วันที่: 11 กันยายน 2552 เวลา:12:41:22 น. |
|
|
|
| โดย: นางสาว ศิริพร คมกล้า รหัส 51040901250 สาขา นิติศาสตร์ หมู่ 01 (จันทร์ - บ่าย ) IP: 202.29.5.62 วันที่: 14 กันยายน 2552 เวลา:14:50:55 น. |
|
|
|
| โดย: นายปิยะ หอมชื่น 51241151144 IP: 125.26.176.50 วันที่: 14 กันยายน 2552 เวลา:15:36:56 น. |
|
|
|
| โดย: นางสาวพิพิทย์ชยานันต์ สีลาเวช 512411511 33 หมุ่ 05 IP: 125.26.176.50 วันที่: 14 กันยายน 2552 เวลา:15:37:51 น. |
|
|
|
| โดย: นายสันทัด คูหานา 51241151128 IP: 125.26.176.50 วันที่: 14 กันยายน 2552 เวลา:15:38:23 น. |
|
|
|
| โดย: นายสุรพล อินทร์ธิราช หมู่ 05 IP: 125.26.176.50 วันที่: 14 กันยายน 2552 เวลา:15:39:11 น. |
|
|
|
| โดย: นายจักรกริช โพธิวงษ์ หมู่ 15 ศุกรเช้า IP: 192.168.1.103, 125.26.174.249 วันที่: 14 กันยายน 2552 เวลา:20:04:20 น. |
|
|
|
| โดย: น.ส. นาริณี อินทร์ดี IP: 125.26.160.68 วันที่: 15 กันยายน 2552 เวลา:0:10:44 น. |
|
|
|
| โดย: น.ส. นาริณี อินทร์ดี IP: 125.26.160.68 วันที่: 15 กันยายน 2552 เวลา:0:19:26 น. |
|
|
|
| โดย: น.ส.สุวรรณี ระวะใจ หมู่เรียนที่ 22 อังคารเช้า IP: 172.29.5.133, 58.137.131.62 วันที่: 15 กันยายน 2552 เวลา:10:15:54 น. |
|
|
|
| โดย: น.สชไมพร ตะโคตร ม.29 พุธ(ช้า) 520404103 IP: 172.29.5.133, 58.147.7.66 วันที่: 15 กันยายน 2552 เวลา:11:13:03 น. |
|
|
|
| โดย: นางสาวกิตติยาพร คนดี(51040901202)สาขานิติศาสตร์ จันทร์บ่าย หมู่1 IP: 124.157.149.128 วันที่: 15 กันยายน 2552 เวลา:19:44:37 น. |
|
|
|
| โดย: นาวสาวกาญจนา อุปวันดี (หมู่01 วันจันทร์บ่าย) IP: 113.53.164.173 วันที่: 15 กันยายน 2552 เวลา:21:57:30 น. |
|
|
|
| โดย: นางสาวประสิทธิ์พร เพ็งสอน(หมู่01 วันจันทร์บ่าย) IP: 113.53.164.173 วันที่: 15 กันยายน 2552 เวลา:21:58:58 น. |
|
|
|
| โดย: นางสาวปิยนุช แสงจันทร์(หมู่01 วันจันทร์บ่าย) IP: 113.53.164.173 วันที่: 15 กันยายน 2552 เวลา:22:01:35 น. |
|
|
|
| โดย: นายวิทวัฒน์ พากุล รหัสนักศึกษา 52042055102 หมู่ 29 ( พุธ เช้า ) IP: 192.168.1.103, 119.42.82.83 วันที่: 16 กันยายน 2552 เวลา:19:44:16 น. |
|
|
|
| โดย: จ.ส.ต. เสกสิท วงศรีรักษา 51241151128 เสารืบ่าย หมู่ 05 รปศ. IP: 222.123.230.32 วันที่: 17 กันยายน 2552 เวลา:14:28:20 น. |
|
|
|
| โดย: จ.ส.อ. อาสา โสมประยูร 51241151211 เสาร์บ่าย หมู่05 รปศ. IP: 222.123.230.32 วันที่: 17 กันยายน 2552 เวลา:14:30:50 น. |
|
|
|
| โดย: จ.ส.ต. หญิง พรรสุภา ชิตเกษร 51241151125 เสาร์บ่าย หมู่ 05 รปศ. IP: 222.123.230.32 วันที่: 17 กันยายน 2552 เวลา:14:33:55 น. |
|
|
|
| โดย: น.ส.จิตราภรณ์ ภุเกตุ หมู่ 8 พฤหัสเช้า IP: 58.137.131.62 วันที่: 17 กันยายน 2552 เวลา:16:41:01 น. |
|
|
|
| โดย: นางสาวจุรีพร โดคตชมภุ รหัส 52040332125 พฤหัส (เช้า) หมู่ 8 IP: 172.29.5.133, 58.137.131.62 วันที่: 17 กันยายน 2552 เวลา:17:15:24 น. |
|
|
|
| โดย: นายอภิเชษฐ์ หาคำ ม.8 พฤหัส (เช้า) IP: 172.29.5.133, 58.137.131.62 วันที่: 17 กันยายน 2552 เวลา:17:22:27 น. |
|
|
|
| โดย: นายสุพจน์ ยางขัน หมู่ 8 พฤหัสเช้า IP: 58.137.131.62 วันที่: 19 กันยายน 2552 เวลา:14:26:57 น. |
|
|
|
| โดย: นางสาวนฤมล ภูหนองโอง รหัสนักศึกษา 52040264108 หมู่ 29 (พุธ-เช้า) IP: 125.26.177.195 วันที่: 19 กันยายน 2552 เวลา:14:42:09 น. |
|
|
|
| โดย: นาย พิษณุ มีที คบ.ทัศนศิลป์ หมู่ 11 1/52 จันทร์/บ่าย 51100103115 IP: 192.168.1.124, 124.157.149.201 วันที่: 20 กันยายน 2552 เวลา:12:01:03 น. |
|
|
|
| โดย: นางสาวสุขชฎา อินทปัญญา หมู่ 22 รหัส 52040427216 IP: 192.168.1.112, 124.157.129.6 วันที่: 23 กันยายน 2552 เวลา:18:16:53 น. |
|
|
|
| โดย: นางสาวหนึ่งฤทัย มังคละแสน คณะมนุษศษสตร์และสังคมศาสตร์ สาขานิติศาสตร์หมู่01 จ.บ่าย IP: 124.157.147.100 วันที่: 23 กันยายน 2552 เวลา:19:29:43 น. |
|
|
|
| โดย: ส.อ.ชาคร ทานินนท์ หมู่ 05 5124151208 IP: 125.26.164.16 วันที่: 24 กันยายน 2552 เวลา:11:23:26 น. |
|
|
|
| โดย: นายตง ประดิชญากาญจน์ IP: 202.29.5.62 วันที่: 24 กันยายน 2552 เวลา:13:28:08 น. |
|
|
|
| โดย: นายชัยวัฒน์ ศรีอุต หมู่ 22 อังคาร (เช้า) IP: 192.168.1.108, 124.157.139.216 วันที่: 24 กันยายน 2552 เวลา:15:07:36 น. |
|
|
|
| โดย: นายชัยวัฒน์ ศรีอุต หมู่ 22 อังคาร (เช้า) IP: 192.168.1.108, 124.157.139.216 วันที่: 24 กันยายน 2552 เวลา:15:10:35 น. |
|
|
|
| โดย: นายศราวุฒิ ทดกลาง IP: 58.147.7.66 วันที่: 24 กันยายน 2552 เวลา:16:08:08 น. |
|
|
|
| โดย: นายอายุวัฒฯ นามมาลา หมู่.29 พุธเช้า IP: 172.23.8.231, 58.137.131.62 วันที่: 24 กันยายน 2552 เวลา:16:30:08 น. |
|
|
|
| โดย: นายอายุวัฒฯ นามมาลา หมู่.29 พุธเช้า IP: 172.23.8.231, 58.137.131.62 วันที่: 24 กันยายน 2552 เวลา:16:32:36 น. |
|
|
|
| โดย: นาย วัชฤทธิ์ มวลพิทักษ์ หมู่22 อ.เช้า IP: 125.26.175.79 วันที่: 26 กันยายน 2552 เวลา:13:59:46 น. |
|
|
|
| โดย: นาย เกรียงไกร สลับศรี หมู่1 จ.บ่าย IP: 192.168.10.106, 117.47.12.205 วันที่: 26 กันยายน 2552 เวลา:19:00:59 น. |
|
|
|
| โดย: นาย เกรียงไกร สลับศรี หมู่1 จ.บ่าย IP: 192.168.10.106, 117.47.12.205 วันที่: 26 กันยายน 2552 เวลา:19:43:20 น. |
|
|
|
| โดย: เบญจมาศ โคตรเพชร หมู่ 08 รหัส 52040332107 IP: 172.29.5.133, 58.137.131.62 วันที่: 27 กันยายน 2552 เวลา:12:32:15 น. |
|
|
|
| โดย: ปรีชา กลมเกลียว หมู่8 พฤหัสบดีเช้า รหัส 52040901222 IP: 124.157.139.201 วันที่: 27 กันยายน 2552 เวลา:15:49:10 น. |
|
|
|
| โดย: นายเจริญชัย ผ่ามดิน IP: 58.137.131.62 วันที่: 28 กันยายน 2552 เวลา:10:36:29 น. |
|
|
|
| โดย: นางสาววันวิสาข์ ศรีทอง หมู่ 1เรียนจันทร์บ่าย IP: 119.42.110.112 วันที่: 28 กันยายน 2552 เวลา:17:24:54 น. |
|
|
|
| โดย: นางสาววันวิสาข์ ศรีทอง หมู่ 1เรียนจันทร์บ่าย IP: 119.42.110.112 วันที่: 28 กันยายน 2552 เวลา:17:32:27 น. |
|
|
|
| โดย: นางสาวปาริฉัตร สาริมุ้ย หมู่ 1จันทร์บ่าย IP: 119.42.110.112 วันที่: 28 กันยายน 2552 เวลา:17:52:38 น. |
|
|
|
| โดย: นางสาวปัทมาวดี ไชยลา หมู่1 เรียนวันจันทร์บ่าย IP: 119.42.110.3 วันที่: 29 กันยายน 2552 เวลา:14:24:48 น. |
|
|
|
| โดย: นางสาวปัทมาวดี ไชยลา หมู่1 เรียนวันจันทร์บ่าย IP: 119.42.110.3 วันที่: 29 กันยายน 2552 เวลา:14:29:09 น. |
|
|
|
| โดย: น.ส.สุกัญญา พรมสวัสดิ์ (หมู่ที่ 15 ศุกร์ เช้า ) IP: 61.19.119.253 วันที่: 30 กันยายน 2552 เวลา:13:53:50 น. |
|
|
|
| โดย: น.ส.สุกัญญา พรมสวัสดิ์ (หมู่ที่ 15 ศุกร์ เช้า ) IP: 61.19.119.253 วันที่: 30 กันยายน 2552 เวลา:13:55:59 น. |
|
|
|
| โดย: น.ส.จิราภรณ์ ศุกรักษ์(หมู่15 ศุกร์ เช้า) IP: 222.123.58.158 วันที่: 30 กันยายน 2552 เวลา:14:01:41 น. |
|
|
|
| โดย: นาย ณัฐพงศ์ มันทะลา IP: 124.157.129.36 วันที่: 30 กันยายน 2552 เวลา:18:44:02 น. |
|
|
|
| โดย: นางสาวกฤตยา อินทร์กอ หมู่ 22 IP: 118.174.22.110 วันที่: 4 ตุลาคม 2552 เวลา:1:08:41 น. |
|
|
|
| โดย: นางสาว สุดารัตน์ นรินทร์ IP: 125.26.164.252 วันที่: 5 ตุลาคม 2552 เวลา:9:34:01 น. |
|
|
|
| โดย: นส.เพ็ญนภา เจริญทรง IP: 192.168.0.109, 180.183.67.230 วันที่: 6 ธันวาคม 2552 เวลา:14:23:34 น. |
|
|
|
| โดย: นายธีรยุทธ วันทอง คบ.ภาษาอังกฤษ รหัส 52100102145 หมู่ 08 พฤหัสเช้า IP: 202.29.5.241 วันที่: 27 ธันวาคม 2552 เวลา:16:52:50 น. |
|
|
|
| โดย: **** นายสุรศักดิ์ พฤคณา 52100102101 คบ.ภาษาอังกฤษ หมู่ 8 พฤหัสบดี เช้า IP: 172.29.5.133, 202.29.5.241 วันที่: 27 ธันวาคม 2552 เวลา:17:08:05 น. |
|
|
|
| โดย: นาย นุกูลกิจ ลีทุม 52100102146 คบ.อังกฤษ หมู่ 8 พฤหัส(เช้า) IP: 202.29.5.244 วันที่: 19 มกราคม 2553 เวลา:14:00:58 น. |
|
|
|
|
|
| |
|
 |
 |
 |
 |
|
|






 ฝากข้อความหลังไมค์
ฝากข้อความหลังไมค์ ผู้ติดตามบล็อก : 35 คน [
ผู้ติดตามบล็อก : 35 คน [
แฟ้มลำดับ (sequential) ลำดับ เทปแม่เหล็กจานแม่เหล็ก ประหยัด ใช้ได้ดีกับการเข้าถึงข้อมูลปริมาณมาก หรือทั้งแฟ้ม การจะเข้าถึงระเบียนแบบเฉพาะเจาะจงใช้เวลามาก
แฟ้มสุ่ม(direct หรือ hash) สุ่ม จานแม่เหล็ก การเข้าถึงระเบียนแบบเฉพาะเจาะจงเร็วมาก ไม่เหมาะกับการเข้าถึงข้อมูลปริมาณมาก และไม่สามารถเข้าถึงข้อมูลแบบเรียงลำดับได้ สิ้นเปลือง
ที่มา
//www.sirikitdam.egat.com/WEB_MIS/103_116/13.html
2. การประมวลผลข้อมูลแบ่งออกได้เป็น 3 แบบ คือ
1. การประมวลผลด้วยมือ (Manual Data Processing)
การประมวลผลด้วยมือ หมายถึงการใช้แรงงานคนเป็นหลักในการประมวลผล โดยมีอุปกรณ์ต่างๆ เข้ามามีส่วนร่วมในการประมวลผล เช่น ดินสอ ปากกา ไม้บรรทัด กระดาษ ลูกคิด เครื่องคิดเลข วิธีการประมวลผลด้วยมือเหมาะกับงานที่มีปริมาณไม่มากนัก และอยู่ในภาวะที่แรงงานยังมีการจ้างงานที่ไม่สูงนัก
2. การประมวลผลด้วยมือกับเครื่องจักรกล(Manual With Machine Assistance Data Processing)
การประมวลผลด้วยมือกับเครื่องจักรกล หรือการประมวลผลด้วยเครื่องจักรกล ซึ่งการประมวลผลแบบนี้จะเหมาะกับงานระดับกลางที่มีปริมาณไม่มากนัก และต้องการความเร็วในการทำงานในระดับพอสมควร การทำงานจะอาศัยแรงงานคน ร่วมกับเครื่องจักรกล เครื่องที่ใช้กันมาก คือ เครื่องทำบัญชี หรือเครื่องประมวลผลกึ่งอิเล็กทรอนิกส์ (Semi-electronic Data Processing)
3. การประมวลผลด้วยเครื่องอิเล็กทรอนิกส์ (Electronic Data Processing)
การประมวลผลด้วยเครื่องอิเล็กทรอนิกส์ หรือการประมวลผลด้วยเครื่องคอมพิวเตอร์ เรียกย่อๆ ว่า EDP คือ การประมวลผลด้วยเครื่องคอมพิวเตอร์ ซึ่งงานที่เหมาะสมกับการประมวลผลด้วยเครื่องคอมพิวเตอร์คือ งานที่มีลักษณะดังนี้
งานที่มีปริมาณมากๆ
ต้องการความเร็วในการประมวลผล
ต้องการความละเอียดและความถูกต้องของงานสูง
งานที่มีขั้นตอนยุ่งยาก ซับซ้อน หรือมีลักษณะที่ทำงานแบบเดิมซ้ำกันหลายๆ รอบ
มีการคำนวณที่ยุ่งยากซับซ้อน
เช่น ระบบงานทะเบียนและวัดผล, ระบบงานการจองตั๋วเครื่องบิน หรือระบบงานด้านการเงินและการธนาคาร เป็นต้น
ขั้นตอนการประมวลผลด้วยเครื่องอิเล็กทรอนิกส์
การประมวลผลข้อมูลด้วยคอมพิวเตอร์แบ่งออกเป็น 3 ขั้นตอน คือ
1. การเตรียมข้อมูลเข้า (Input Data)
คือการเก็บรวบรวมข้อมูลให้พร้อมที่จะทำการจัดเก็บ บันทึก และประมวลผล ซึ่งประกอบไปด้วย
1.1 การลงรหัส (Coding) คือการใช้รหัสแทนข้อมูล ซึ่งทำให้ข้อมูลอยู่ในรูปที่กระทัดรัดเพื่อสะดวกแก่การประมวลผล รหัสที่ใช้อาจเป็นตัวเลขหรือไม่ใช่ตัวเลขก็ได้
1.2 การแก้ไข (Editing) คือการตรวจสอบข้อมูล ให้มีความถูกต้อง และเป็นไปได้ (เช่น ข้อมูลอายุ ควรจะอยู่ระหว่าง 0 - 100 ปี เป็นต้น) ก่อนนำไปใช้งาน โดยมีการปรับปรุงแก้ไขเท่าที่จำเป็น
1.3 การแยกประเภท (Classifying) คือ การจัดประเภทของข้อมูล หรือจำแนกข้อมูลออกเป็นกลุ่มเพื่อสะดวกแก่การนำไปประมวลผล เช่น ร้านค้าย่อย อาจจะจำแนกเป็น ชนิดของสินค้า แผนกที่ขาย ผู้ขาย หรือจำแนกหมวดอื่นๆ ตามที่ผู้จัดร้านเห็นว่ามีประโยชน์ต่อการดำเนินงาน
1.4 การแปรสภาพข้อมูล (Transforming) คือ การเปลี่ยนสื่อ หรือตัวกลางที่ใช้บันทึกข้อมูลเพื่อให้อยู่ในรูปที่สามารถนำไปประมวลผลต่อไปได้ เช่น การเจาะข้อมูลลงบนบัตร เพื่อให้คอมพิวเตอร์สามารถรับไปประมวลผลได้
2. การประมวลผล (Processing)
ได้แก่ วิธีการจัดการกับข้อมูล ซึ่งอาจเป็นการบวก ลบ คูณ หาร หรือการคำนวณ และเปรียบเทียบลักษณะต่างๆ ที่กำหนดไว้
3. การนำเสนอข้อมูล (Output)
คือ การเอาผลลัพธ์ที่ได้จากการประมวลผลมาแสดงให้ผู้อื่นทราบ อาจจะแสดงไว้ในรูปรายงาน ตาราง หรือแบบใดก็ได้ที่สามารถนำเสนอให้ผู้อื่นเข้าใจได้ง่าย
3.1 การสรุปผล (Summarizing) คือการนำเอาข้อมูลทั้งหมดที่มีอยู่มากลั่นกรอง และย่อลงให้เหลือเฉพาะส่วนที่จำเป็น เพื่อที่จะนำไปปฏิบัติให้คล่องตัว และใช้ประกอบการตัดสินใจ
3.2 การเก็บข้อมูล (Storing) เพื่อให้สามารถใช้ข้อมูลต่างๆ ได้อีกในอนาคตจึงจำเป็นต้องมีการจัดเก็บไว้อย่างเป็นระเบียบ ในระบบคอมพิวเตอร์มักจะบันทึกลงเทปแม่เหล็กหรือจานแม่เหล็ก
3.3 การค้นหาและการเรียกใช้ข้อมูล (Searching and Retrieving) คือ การค้นหาข้อมูลในแฟ้มข้อมูล และเรียกข้อมูลนั้นกลับมาใช้งาน (เช่นนำข้อมูลกลับมาแก้ไข ปรับปรุง)
3.4 การทำสำเนาข้อมูล (Reproduction) ไม่ว่าจะเป็นข้อมูลดิบที่ได้มาใหม่ หรือข้อมูลจากการประมวลผล ในบางครั้งต้องการข้อมูลหลายชุด จึงจำเป็นต้องมีการสำเนาข้อมูลออกมาใช้หลายๆ ชุด
--------------------------------------------------------------------------------
ระบบการทำงานของเครื่องคอมพิวเตอร์ (Computer processing)
สามารถแบ่งออกได้ดังต่อไปนี้
1. การประมวลผลแบบกลุ่ม (Batch processing system)
หมายถึงการประมวลผลข้อมูลที่ต้องมีการรวบรวมข้อมูลให้มากพอควร โดยใช้ระยะเวลาช่วงหนึ่งในการเก็บรวบรวม เมื่อมีการสะสมข้อมูลครบเวลาที่กำหนด จึงนำไปประมวลผล ระบบเครื่องที่ประมวลผลแบบนี้เรียกว่าระบบออฟไลน์ (Off-line system)
2. การประมวลผลแบบโต้ตอบ (Interactive processing system)
เป็นวิธีการประมวลผลที่รับข้อมูลที่เกิดขึ้นเข้าสู่เครื่องคอมพิวเตอร์ได้โดยตรง และเครื่องสามารถที่จะโต้ตอบข้อมูลที่รับเข้ามาทันที (ข้อมูลที่เข้าไปแต่ละรายการจะถูกประมวลผลทันที) เช่น ระบบการฝากถอนเงินโดยเครื่อง ATM เป็นต้น การทำงานในระบบนี้เรียกอีกอย่างว่าระบบออนไลน์ (On-line system) ซึ่งระบบ On-line นี้ยังมีประเภทย่อยๆ อีก 2 ประเภท คือ
2.1 ระบบการประมวลผลโดยใช้เวลาจริง (Real-time processing) เป็นระบบที่ต้องการความรวดเร็วในการตอบสนองข้อมูลสูงมาก (ข้อมูลที่ตอบสนองมาต้องถูกต้อง แน่นอน แม่นยำ ทันต่อเวลา)
2.2 ระบบการประมวลผลแบบเวลา (Timesharing processing) เป็นระบบที่ให้ผู้ใช้หลายๆ คนสามารถทำงานพร้อมๆ กันได้ โดยการแบ่งเวลาหน่วยประมวลผลกันใช้งาน โดยการผ่านเครื่องเทอร์มินัล ซึ่งเป็นสถานีที่ใช้ในการติดต่อระหว่างผู้ใช้กับคอมพิวเตอร์ และสามารถจัดสรรหน่วยความจำของระบบให้ผู้ใช้ได้ตามความต้องการของงาน
3. การประมวลผลโดยใช้ตัวประมวลผลมากกว่า 1 ชุด (Multiprocessing system)
หมายถึงการประมวลผลโดนอาศัยหน่วยประมวลผลกลางมากกว่า 1 ชุด โดยกำหนดให้ทำงานในเวลาพร้อมๆ กัน (อาจจะเสริมการทำงาน หรือ สำรองการทำงานซึ่งกันและกัน) นิยมใช้กับงานที่จำเป็นต้องมีการประมวลผล อยู่ตลอดเวลา
4. การประมวลผลแบบหลายโปรแกรม (Multiprogramming system)
ระบบ Multiprogramming system หรือ Multi tasking system หมายถึงระบบการประมวลผลที่ในขณะเวลาใดเวลาหนึ่งสามารถมีโปรแกรม อยู่ในระบบการประมวลผลมากกว่า 1 โปรแกรมได้ กล่าวคือ ในขณะที่โปรแกรมหนึ่งกำลังทำงานอยู่ ผู้ใช้สามารถที่จะเรียกโปรแกรมอื่น มาทำงานซ้อนได้ และสามารถที่จะสลับกันทำงานระหว่างโปรแกรมที่เปิดใช้งานอยู่ได้
ที่มา
//www.nrru.ac.th/learning/science/sc_007/03/unit3/data3.html