Bloggang.com : weblog for you and your gang
Sufficiency Economy
Group Blog
Japanese Language
ท่องศัพท์ภาษาญี่ปุ่นวันละคำ
NSW NDS DSi 3DS Programming
Romancing Saga2 Translation
My Japanese Coach
XNA Unity3d Programming
Miyoo Mini and Dingoo A-320
SNES NES GB programming
MAC OSX IOS APPLE
บันทึกช่วยจำ
บ้านไร่ ชายทุ่ง
Android
ไม่เข้ากลุ่ม
Graphic Art
Python Programming
Linux
English
VITA PSP Programming
Flutter WEB JAVA PHP JSP ASP
LibreOffice
ออกกำลังกาย
Gameboy Advance
All blogs
pyTorch
Youtube การใช้ Tkinter python
Python : Machine Learning [6]
Python : Machine Learning [5]
Python : Machine Learning [4]
Python : Machine Learning [3]
Python : Machine Learning [2]
Python : Machine Learning [1]
เชียนโปรแกรมได้ทุกที่ ด้วย Qpython
ทดลอง Natural Language Toolkit
python + ubuntu + japanese + write binary file ?
Python + Matplotlib
Python อ่าน และการเขียนข้อมูลลงใน binary file
ตัวอย่างการ load ไฟล์ จาก web mangareader.net
python: OpenCV สร้างภาพสีขาวดำ grayscale
python: OpenCV Crop ภาพ
Python: OpenCV ทำภาพ Smooth
python : ทดลองใช้ OpenCV
Python: การเขียนไฟล์ กับปุ่มกด
Python: โหลดการ์ตูนจาก web ตอนที่ 4
Python: โหลดการ์ตูนจาก web ตอนที่ 3
Python: โหลดการ์ตูนจาก web ตอนที่ 2
Python: โหลดการ์ตูนจาก web
Python อ่านข้อมูล text File (Lexitron)
Python อ่านโครงสร้างของ Table ของ MS Access
Python ทำโปรแกรมจัดการฐานข้อมูล MS Access อย่างง่าย
Python การจัดการ widgets ด้วย grid method
Python ติดต่อฐานข้อมูล Access
Python ทดลองเขียนโปรแกรมเครื่องคิดเลข บวก ลบ ตอนที่2
Python ทดลองเขียนโปรแกรมเครื่องคิดเลข บวก ลบ ตอนที่1
Python Step by Step ^ ^
ทดลองใช้ Python
Python : Machine Learning [5]
เมื่อวานเรียนบทที่ 8 สอนเรื่อง Grouping Data
โดยใช้หลัก Split Apply Combine SAC งงส่ะ
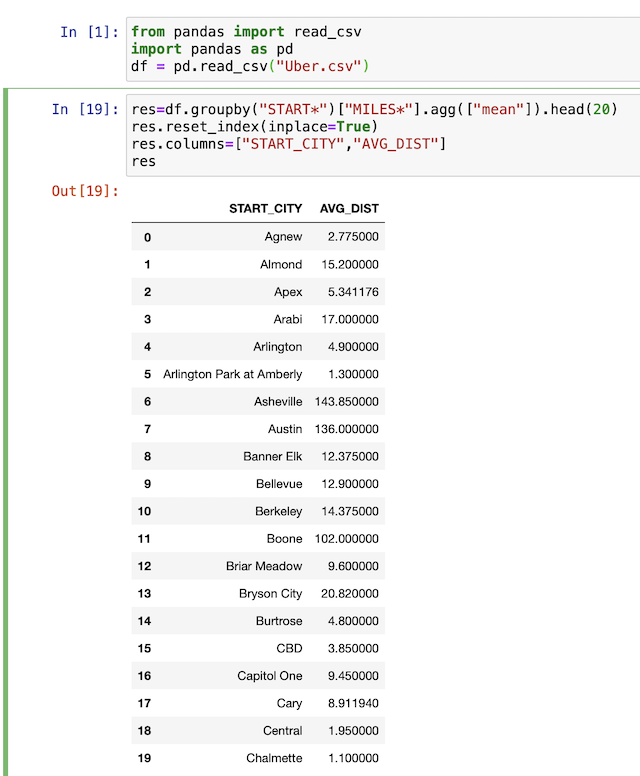
res=df.groupby("START*")["MILES*"].agg(["mean"]).head(20)
ทำ grouping ด้วย column START* แล้วนำค่า MILES* มาคำนวณค่าเฉลี่ย และให้แสดงผลเพียง 20 บรรทัด
res.reset_index(inplace=True)
res.columns=["START_CITY","AVG_DIST"]
กำหนดชื่อ column ใหม่ ให้เข้าใจง่ายขึ้น แต่ต้อง reset_index ก่อนนะ งงๆ เหมือนกัน
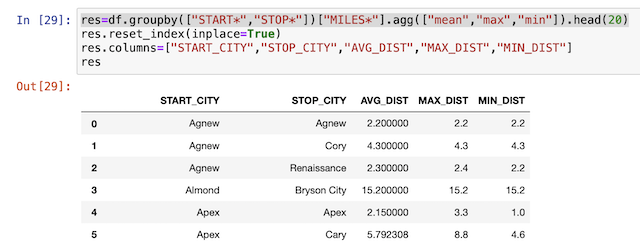
res=df.groupby(["START*","STOP*"])["MILES*"].agg(["mean","max","min"]).head(20)
เพิ่มการคำนวณหาค่า max min จาก column MILES*
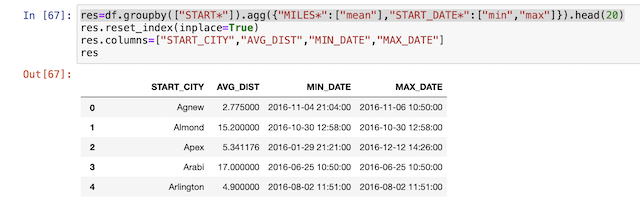
res=df.groupby(["START*"]).agg({"MILES*":["mean"],"START_DATE*":["min","max"]}).head(20)
ถ้าเราต้องการคำนวณค่า คนละcolumnกัน ต้องใช้ datetype แบบ dictionary {} แล้วกำหนดเป็นคู่ๆไป
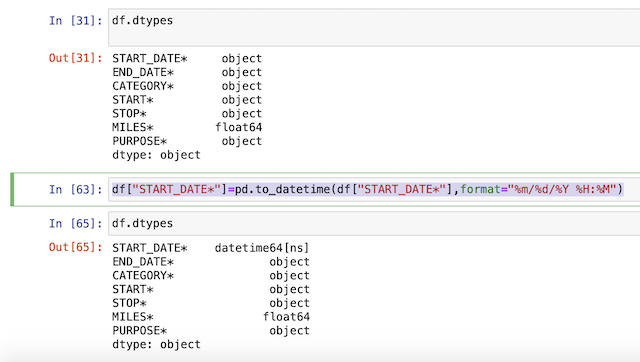
df["START_DATE*"]=pd.to_datetime(df["START_DATE*"],format="%m/%d/%Y %H:%M")
START_DATE* ต้องแปลงให้เป็น datetime ก่อน ถึงจะคำนวณได้ ถ้าทำแล้วเกิด ERROR ให้ดูข้อมูล Uber.csv ที่ให้มาว่ามีบรรทัดได้ที่รูปแบบไม่ถูกต้อง ??
ทดลองก็ประมาณรูปข้างล่างครับ
ข้างล่างแสดงการ convert datetime
Create Date : 20 สิงหาคม 2563
Last Update : 20 สิงหาคม 2563 21:30:22 น.
0 comments
Counter : 935 Pageviews.
Share
Tweet
ชื่อ :
Comment :
*ใช้ code html ตกแต่งข้อความได้เฉพาะสมาชิก
wink99_th
Location :
พิษณุโลก Thailand
[Profile ทั้งหมด]
ฝากข้อความหลังไมค์
Rss Feed
Smember
ผู้ติดตามบล็อก : 8 คน [
?
]
New Comments
Friends' blogs
Aorora
I^^
กิ่งลีลาวดี
มาทิรน
daikon
nainokkamin
jaikojung
Webmaster - BlogGang
[Add wink99_th's blog to your web]
Links
ชุมชนคนรัก ญี่ปุ่น และ ภาษาญี่ปุ่น
BlogGang.com
Pantip.com
|
PantipMarket.com
|
Pantown.com
| © 2004
BlogGang.com
allrights reserved.


 ฝากข้อความหลังไมค์
ฝากข้อความหลังไมค์ ผู้ติดตามบล็อก : 8 คน [
ผู้ติดตามบล็อก : 8 คน [