|
|
|
XIBOTS (3)
XIBOTS version แรกเสร็จแล้วครับ
เป็น version 0.5 ครับ download ได้ที่
//code.google.com/p/xibots/downloads/list
file ที่ให้ download จะมี 2 file คือ
xibots-v0.5.zip <--- สำหรับ Windows
xibots-v0.5.tar.gz <--- สำหรับ Unix/Linux
พอ download เสร็จแล้ว ขั้นตอนที่ต้องทำคือ
- extract
- เตรียม libcurl
- build XIBOTS
Extract File
สำหรับ Windows ไม่น่ามีปัญหา
tool ที่ extract .zip file มีหลายตัว เช่น pkzip, winzip, winrar, 7zip
สำหรับ Linux ใช้
tar xvfz xibots-v0.5.tar.gz
ส่วน Unix อาจต้องใช้
gunzip xibots-v0.5.tar.gz
แล้วตามด้วย
tar xvf xibots-v0.5.tar
files ที่ extract ออกมาจะอยู่ภายใต้ directory xibots
ประกอบไปด้วย
LICENSE-2.0.txt <--- เป็น Apache License
Makefile <--- เป็น Makefile สำหรับ Unix/Linux โดยเฉพาะ ส่วนของ Windows จะอธิบายต่อไป
แล้วก็ source code พวก .h .c
db.c
db.h
html.c
html.h
http.c
http.h
url.c
url.h
ustring.c
ustring.h
xibots.c
xibots.h
รายละเอียดของแต่ละ file จะอธิบายคราวหน้า ขอติดไว้ก่อน
เตรียม libcurl
อย่างที่บอกใน entry แรกว่า XIBOTS ใช้ libcurl เป็นตัวทำ download
ก่อนที่จะ build XIBOTS ต้องเตรียม libcurl ก่อนครับ
สำหรับ Unix/Linux
1) กรณีที่มี libcurl ติดตั้งอยู่แล้ว ตรวจสอบได้โดยรัน
curl-config --cflags
จะได้ผลลัพธ์ประมาณ (เป็นแค่ตัวอย่าง)
-I/usr/local/include
แต่ถ้าเกิด error ก็แสดงว่าไม่มี libcurl ติดตั้งอยู่ ให้ข้ามข้อ 2) ไปที่ข้อ 3)
2) ทีนี้ก็รัน
curl-config --cflags
-I/usr/local/include (ตัวอย่างผลลัพธ์)
แล้วเอาผลลัพธ์ไปใส่ใน Makefile ของ XIBOTS ตรงบรรทัด
LIBCURL_CFLAGS=
แก้เป็น
LIBCURL_CFLAGS=-I/usr/local/include
และรัน
curl-config --libs
-L/usr/local/lib -lcurl -lssl -lcrypto -ldl -lz (ตัวอย่างผลลัพธ์)
แล้วเอาผลลัพธ์ไปใส่ใน Makefile ของ XIBOTS ตรงบรรทัด
LIBCURL_LIBS=
แก้เป็น
LIBCURL_LIBS=-L/usr/local/lib -lcurl -lssl -lcrypto -ldl -lz
แล้วข้ามข้อ 3) ไปที่ขั้นตอนการ build XIBOTS
3) กรณีที่ต้อง build libcurl ขึ้นมาเอง
build เฉยๆ นะครับ ไม่ต้องติดตั้ง
ไปที่
//curl.haxx.se/download.html
ภายใต้หัวข้อ Source Archives
เลือก version ล่าสุด ที่ลงท้ายด้วย .tar.gz
ตอนที่เขียน blog อยู่นี่ version ล่าสุดเป็น curl-7.19.5.tar.gz
พอ download เสร็จก็ทำการ extract
สำหรับ Linux ใช้
tar xvfz curl-7.19.5.tar.gz
ส่วน Unix อาจต้องใช้
gunzip curl-7.19.5.tar.gz
แล้วตามด้วย
tar xvf curl-7.19.5.tar
ผลจากการ extract จะได้ directory curl-7.19.5
ทีนี้เราก็หาว่า directory curl-7.19.5 ที่ได้อยู่ที่ไหน ตัวอย่างเช่น
/home/user/aaa/curl-7.19.5
ต้องจำไว้ จะได้ใช้ตอนหลัง
ต่อไปก็เข้าไปใน directory curl-7.19.5 โดยทำคำสั่ง
cd curl-7.19.5
แล้วรัน
./configure --disable-ldap --without-ssl --without-zlib --without-ca-bundle --without-libidn
ตัว configure จะสร้าง Makefile ขึ้นใหม่
แล้วรัน
make clean
ตามด้วย
make
ถ้าไม่มี error เราจะได้ libcurl ตัวใหม่
ไปที่ Makefile ของ XIBOTS แล้วแก้ 3 บรรทัดตามนี้
LIBCURL_DIR=/home/user/aaa/curl-7.19.5
LIBCURL_CFLAGS=-I($LIBCURL_DIR)/include
LIBCURL_LIBS=$(LIBCURL_DIR)/lib/.libs/libcurl.a -lrt
แล้วไปที่ขั้นตอนการ build XIBOTS
สำหรับ Windows
การติดตั้ง libcurl บน Windows จะยุ่งยากหน่อย
เพราะมี compiler + tool หลายตัว หลายวิธีการ
บวกกับ option ของ libcurl เอง ทำให้ยุ่งยากเข้าไปอีก
แต่ที่ผมทดลองแล้วได้ผลดี คือ
download dll มาจากที่หนึ่ง แล้ว download .h กับ .lib มาจากอีกที่ ครับ
อาจฟังดูประหลาดซักหน่อย
เริ่มจาก download libcurl.dll มาจากที่นี่ครับ
//www.paehl.com/open_source/?CURL_7.19.5
เลือก download ตรงที่เขียนว่า
Download libcurl.dll (SSL, NOSSL and SSH2) only
พอ download มาแล้ว extract ด้วย 7zip
copy libcurl.dll ที่อยู่ใน directory nossl ไปใส่ไว้ที่ directory system32 ภายใต้ windows
ต่อไปก็ไปที่
//curl.haxx.se/dlwiz/?type=devel&os=Win32&flav=MSVC
เลือก download อันที่ไม่มี ssl
ตอนที่เขียน blog อยู่นี่เป็น file นี้ครับ
libcurl-7.18.0-win32-msvc.zip
พอ download มาแล้ว สมมุติว่า extract ไปไว้ที่
C:\libcurl-7.18.0
ต้องจำไว้ จะได้ใช้ตอนหลัง
Build XIBOTS
สำหรับ Unix/Linux
ไปที่ directory ของ XIBOTS
กรณีที่ใช้ OS เป็น Solaris ต้องแก้ Makefile ของ XIBOTS ตรงบรรทัด
LDLIBS=$(LIBCURL_LIBS)
แก้เป็น
LDLIBS=$(LIBCURL_LIBS) -lsocket -lnsl
Unix อื่นหรือ Linux ไม่ต้องแก้ครับ
แล้วรัน
make clean
ตามด้วย
make
ถ้าไม่มี error ก็เป็นอันเสร็จเรียบร้อย ลองรัน
./xibots -h
XIBOTS จะแสดง usage กับ help ขึ้นจอ
แต่ถ้าเกิด error ขึ้น ก็อาจมาจาก libcurl ที่มีอยู่ไม่สมบูรณ์
ให้กลับไปทำข้อ 3) ในขั้นตอน เตรียม libcurl
แล้วค่อยมา build XIBOTS ใหม่
สำหรับ Windows
ไม่ว่าจะเป็น VC++ 6.0 หรือ VC++ 2008 Express Edition
เราจะไม่ใช้ Makefile ที่มากับ XIBOTS
ต้องสร้าง project ขึ้นมาใหม่ ขั้นตอนคือ
- สร้าง project สำหรับ Win32 Console Application
- สร้าง แบบ empty project
- add file .c .h ที่มากับ XIBOTS เข้าใน project
- add include path C:\libcurl-7.18.0\include
- add library libcurl.lib
- add library ws2_32.lib
- add library path C:\libcurl-7.18.0
สำหรับ 2008 Express Edition
ต้องเอา Unicode ออก โดยไปที่
Configuration Properties->General->Character Set
แก้ให้เป็น Not Set
และเพิ่ม _CRT_SECURE_NO_WARNINGS ที่
Configuration Properties->C/C++->Preprocessor
เป็นอันเสร็จ ต่อไปก็ build ได้เลยครับ
การทดสอบ
พอได้ตัว execute file แล้วก็ลองรันเลยครับ
สำหรับ Unix/Linux
./xibots -m 100 //www.example.com
สำหรับ Windows
xibots -m 100 //www.example.com
เมื่อ xibots ทำงานจบ เราต้องกด Enter หนึ่งครั้ง
xibots จะสร้าง file ขึ้นจำนวนหนึ่งและ directory docs
main entry จะอยู่ที่ xibots.html
ลองเปิด xibots.html ด้วย browser ดูนะครับ
หวังว่าคง build กันได้นะครับ
วันนี้เอาแค่นี้ก่อน คราวหน้าจะมาอธิบายที่ติดๆ ไว้ครับ

| Create Date : 06 มิถุนายน 2552 | | |
| Last Update : 7 มิถุนายน 2552 8:03:59 น. |
| Counter : 1195 Pageviews. |
| |
|
 |
|
|
|
XIBOTS (2)
ก่อนที่จะลงรายละเอียดของ XIBOTS
ลองมาดูปัญหาของ internets bots (ต่อไปจะเรียกว่า bots เฉยๆ) กันซักหน่อย
ข้อแรกคือ bots อาจ load ข้อมูลมาซ้ำๆ กัน
ข้อสองคือ bots อาจ load ไม่รู้จบ คือทำงานไปเรื่อย ไม่เสร็จซักที
ปัญหาแรกเรื่องข้อมูลซ้ำ
หากข้อมูลซ้ำเกิดจาก URL ซ้ำ ทางแก้ง่ายๆ คือ
ตรวจสอบ URL ก่อนว่าเคย load มาแล้วหรือเปล่า
หรือเป็น URL ที่อยู่ใน queue หรือเปล่า
แต่ถ้า URL ไม่ซ้ำ แต่ load มาแล้วข้อมูลซ้ำกับ URL อื่น
อันนี้ต้องตรวจสอบจาก signature ของข้อมูลแทน
อาจใช้ message digest พวก MD5, SHA มาช่วย
แต่ก็ต้อง load ข้อมูลมาก่อน คือเสียเวลาอยู่ดี
พวก bots ของ search engine จะต้องป้องกันเรื่องข้อมูลซ้ำ
เพราะจะทำให้ใช้ resource มากขึ้น และ search engine ทำงานช้าลง
แต่สำหรับ XIBOTS จะใช้แค่ การตรวจสอบ URL ซ้ำเท่านั้นครับ
ปัญหาต่อมาเรื่องทำงานไม่รู้จบ
เรื่องนี้อาจเกิดขึ้นได้ ถึงแม้ว่าจะวางเป้าหมายไว้ว่าให้ bots load ภายใน site ที่กำหนดเท่านั้น
สาเหตุคือได้ URL ที่ไม่เคยเหมือนเดิมเลย คือไม่ซ้ำ
bots ก็เลย load ไปเรื่อยๆ
เรียกว่าเป็น หลุมพราง หรือ trap ของ bots
ตัวอย่างของ URL ไม่รู้จบเช่น
//www.haha.com/page?lang=th
//www.haha.com/page?lang=th&lang=eng
//www.haha.com/page?lang=th&lang=eng&lang=th
//www.haha.com/page?lang=th&lang=eng&lang=th&lang=eng
//www.haha.com/page?lang=th&lang=eng&lang=th&lang=eng&lang=th
...
หรือ
//www.hehe.com/page/dira
//www.hehe.com/page/dira/dirb
//www.hehe.com/page/dira/dirb/dira
//www.hehe.com/page/dira/dirb/dira/dirb
...
ถ้า bots หลงเข้าไปใน URL พวกนี้ก็จะ load นานมาก หรือบางที crash ไปเลย
trap
trap หรือหลุมพรางแบบที่ว่า อาจเกิดขึ้นโดยไม่ตั้งใจ หรือบางทีก็จงใจทำขึ้นมาเลยครับ
ลองค้นคำเหล่านี้ใน internet ดู
spider trap
bots trap
crawler trap
จะเห็นว่ามีการจงใจวาง trap ไว้ โดยเฉพาะกับ bots
นัยว่าเป็นการลงโทษ bots ที่ไม่ทำตามข้อมูลใน file robots.txt
robots.txt
robots.txt จะเป็น file ที่มีอยู่ใน website โดยอยู่ที่ root
เช่น robots.txt ของ pantip.com ก็จะอยู่ที่
//www.pantip.com/robots.txt
ลองใช้ browser load มาดูได้
แต่แปลกจริงครับ bloggang.com ไม่ยักกะมี robots.txt
ข้อมูลใน robots.txt จะระบุว่า bots จะ load URL ไหนได้บ้าง
และ URL ไหนห้าม load
แต่ก็มี bots ที่ไม่สนใจจะทำตาม รวมถึง XIBOTS ด้วยครับ
ใน XIBOTS ผมเว้นเรื่อง robots.txt ไว้ ให้เอาไปทำต่อกันเอง ฮิฮิ
กลับมาที่ปัญหาเรื่อง trap
ไม่มีวิธีแก้ปัญหาที่สมบูรณ์แบบครับ ต้องแก้เป็นกรณีๆ ไป
วิธีง่ายๆ แบบนึง คือกำหนดจำนวนสูงสุดของ URL ที่ load ได้
พอจำนวนถึง ก็หยุด load เลยครับ ไม่ต้องคิดมาก
อีกวิธีคือกำหนดจำนวนสูงสุดของ level ครับ
level
level คือระดับความลึกของ URL ว่าอยู่ห่างจาก URL เริ่มต้นแค่ไหน ลองดูตามรูป
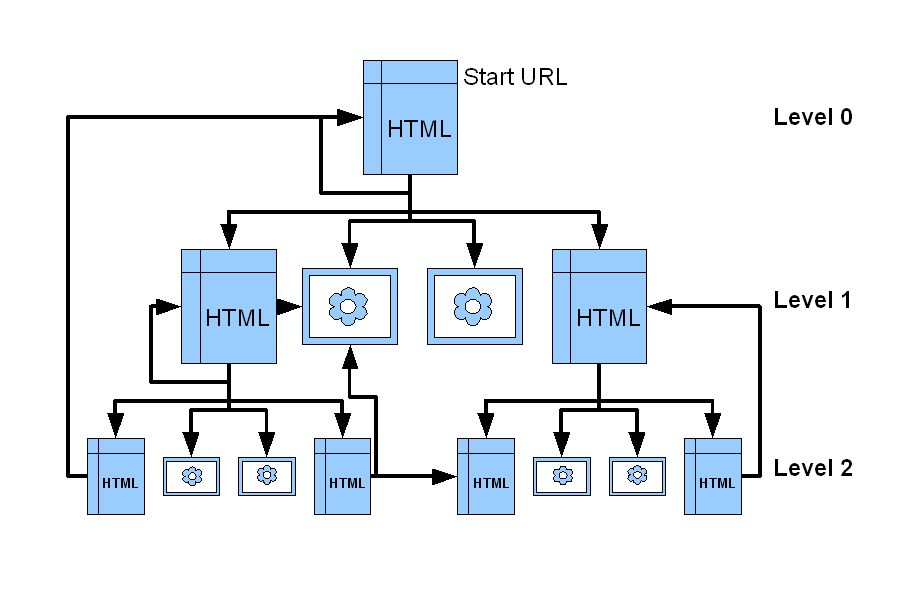
รูปด้านบนเป็นตัวอย่างโครงสร้างของ website
เริ่มจาก start URL ที่อยู่บนสุด (level 0) อาจมี URL เดียวหรือหลาย URL ก็ได้
แล้วก็มี link ไปยัง URL อื่นๆ ที่อยู่ถัดลงมา (level 1)
และก็ link ไปยัง level ถัดไป
ถ้ากำหนดจำนวนสูงสุดของ level
พอ load ได้จำนวน level ครบ ก็ให้หยุด
สรุป
ตรวจสอบ URL ซ้ำ
กำหนดจำนวน URL สูงสุด
กำหนดจำนวน level สูงสุด
จะช่วยแก้ปัญหาของ internet bots ที่เล่ามาได้บ้าง
วันนี้เอาแค่นี้ก่อน ยังไม่ได้เริ่มเข้า module เลย
ยังไงขอติดไว้ก่อน สงสัยต้องติดไว้อีกหลายทีครับ
| Create Date : 17 พฤษภาคม 2552 | | |
| Last Update : 17 พฤษภาคม 2552 20:07:58 น. |
| Counter : 773 Pageviews. |
| |
|
| |
|
|
|
XIBOTS (1)
ไม่ได้เขียน blog มานาน ...
เพราะไม่ค่อยจะมีเวลาว่าง (ข้ออ้าง สูตรสำเร็จ)
ทั้งงานหลวงงานราษฎ์
และที่สำคัญคือ ขี้เกียจ (ยอมรับ) ครับ
ทีนี้พอมีเวลาว่างบ้าง ก็มานั่งนึกว่า น่าจะหาอะไรทำ ดีกว่าอยู่เฉยๆ
จริงๆ ก็พยายามหาอะไรทำอยู่เรื่อยๆ แหละครับ
แต่ทำไม่เสร็จเป็นชิ้นเป็นอัน ซะเยอะ
คราวนี้ต้องตั้งใจทำให้เป็นเรื่องเป็นราว และต้องทำให้เสร็จ
ลองไปเอางานเก่าที่ค้างๆ มาดูว่า อันไหนทำได้แน่ เสร็จแน่
เลยเป็นที่มาของ project นี้
คือ internet bots หรือ web crawler ครับ
มารู้จัก internet bots หรือ web crawler กันก่อน
internet bots คือโปรแกรมอัตโนมัติที่ load ข้อมูลจาก web site มาเก็บลง disk
ถ้าข้อมูลที่ได้เป็น html ก็จะทำการหาว่ามี link ไปที่ไหนบ้าง
แล้วก็ตามไป load ข้อมูลต่อไปแบบอัตโนมัติครับ
พวก search engine จะใช้ internet bots ในการ load ข้อมูลจาก web site ต่างๆ
เพื่อนำมาสร้าง index สำหรับค้นหาครับ
ชื่อ
กลับมาที่ project
จะทำให้เสร็จแน่ๆ ก็ต้องทำให้เป็นทางการหน่อย
เริ่มจากชื่อ project ก่อนเลยครับ
ผมตั้งชื่อ project internet bots ของผมว่า
eXperimental Internet BOTS
เรียกย่อๆว่า XIBOTS
แบบว่าเป็นการทดลองส่วนตัวครับ
วัตถุประสงค์
พอตั้งชื่อได้แล้วก็มาถึงวัตถุประสงค์
ข้อแรกคือ ต้องการศึกษาค้นคว้า และทดลองเขียน internet bots
ข้อสองคือ ทำเป็น open source เพื่อให้ผู้สนใจสามารถศึกษาและนำไปใช้ต่อไป
ข้อสามคือ ไม่เขียนทุกอย่างขึ้นมาใหม่ทั้งหมด แต่จะใช้เครื่องมือที่มีอยู่แล้ว
ข้อสี่ นึกไม่ออก
เป้าหมาย
ต่อมาก็หาเป้าหมาย
ข้อแรกคือ โปรแกรมต้องรันได้ทั้ง linux, unix และ windows (console application)
ข้อสองคือ โปรแกรมจะ download เฉพาะ URL ที่อยู่ภายใน site ที่กำหนดเท่านั้น
ข้อสามคือ โปรแกรมจะรับค่า URL และ parameter ต่างๆ ทาง command line
ข้อสี่คือ โปรแกรมจะสร้าง output report เป็น html
เครื่องมือ
ทีนี้ก็มาเลือกเครื่องมือครับ
ก่อนอื่นก็คือภาษาที่เขียน จะใช้ standard C ครับ (แน่นอนอยู่แล้ว)
เครื่องมือที่จะใช้คือ libcurl (//curl.haxx.se) เป็นตัวทำ download
Architecture
แล้วก็มาถึง idea เรียกว่า สถาปัตยกรรม ก็แล้วกัน
XIBOTS จะมีสถาปัตยกรรมดังรูป
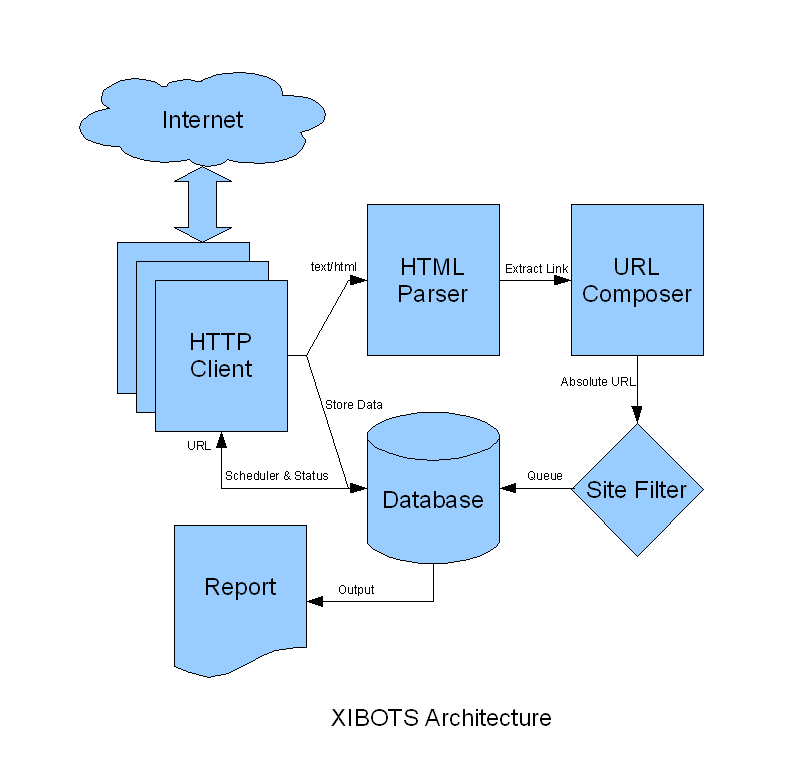
HTTP Client
คือส่วนที่จะ download ข้อมูลจาก internet โดยเอา URL มาจาก Database
เมื่อ download เสร็จก็จะเก็บข้อมูลลง Database
ถ้า content type ของข้อมูลเป็น text/html ก็จะส่งต่อข้อมูลไปยัง HTML Parser
สามารถ download ได้พร้อมๆ กันหลาย URL
HTTP Client นี้จะใช้ libcurl เป็นเครื่องมือ
HTML Parser
เป็นตัววิเคราะห์ html เพื่อหา link โดยดูจาก element พวก <a>, <img>, <base>, <frame> ...
เมื่อได้ URL ก็ส่งต่อไป URL Composer
URL Composer
จะทำการสร้าง absolute URL เช่น
จาก page ของ //www.aaa.com/bbb.html
มี link ไปที่ ccc.jpg จะได้ absolute URL เป็น
//www.aaa.com/ccc.jpg
นอกจากนี้ก็จะทำเรื่องอื่นๆ ที่เกี่ยวกับ URL
Site Filter
เป็นตัวกรอง URL ให้เอาเฉพาะที่อยู่ใน site เดียวกัน
Database
จะเป็นที่เก็บ URL ที่อยู่ใน queue รวมถึง status, level, ข้อมูลที่ download มาได้
รวมถึงการตรวจสอบ URL ที่ซ้ำ
Report
นำข้อมูลจาก database มาออก report เป็น html
เป็นคำอธิบายแบบคร่าวๆ ครับ
วันนี้เอาแค่นี้ก่อน คราวหน้าจะมาเล่ารายละเอียดในแต่ละ module ต่อไป
ยังต้องทำอีกยาวครับ
| Create Date : 05 พฤษภาคม 2552 | | |
| Last Update : 6 พฤษภาคม 2552 19:51:12 น. |
| Counter : 961 Pageviews. |
| |
|
| |
|
|
|
|
|
|




 ฝากข้อความหลังไมค์
ฝากข้อความหลังไมค์ ผู้ติดตามบล็อก : 2 คน [
ผู้ติดตามบล็อก : 2 คน [