|
���ͧ��蹡Ѻ���ͧ�������§����Ҷ֧��
[��úѭ���������ͧ�����ѧ�֡��]
Law of the first wavefront ���� precedence effect (�ҧ�����¡ Haas effect) �͡��� ��Ҥ������§������¡ѹ 2 ����Թ�ҧ�Ҷ֧���ѧ������������¡ѹ �����ҧ�ѹ����Թ 50 ms ���ѧ�����Թ���§�á ��������Թ (suppress) ���§��ѧ �֧������§��ѧ�дѧ���Ҷ֧ 10 dB �������ҷ����ҧ�ѹ�ҡ���� 65 ms (���ͷ����ҧ�ѹ����ҳ 20 ������ҡ��) ��Ҩ����Թ���§ echo �Ѵਹ ������˵ؼ���ҷ��� ���������Թ���§ echo ���ͧ��� �
��ҡ���ó��鷴�ͧ��蹧��� � �����ʤ�Ի���� �ͧ�Ѵ���§�ѡ˹�觾�ҧ�� (㹵�����ҧ���������§ so.wav) �鴨�������§����� echo ������������� delay ��Ҥ�Ҥ�� 10 ms, 30 ms, 50 ms, 70 ms ��� 90 ms �ʹ���������� 50 ms ��ҡ���������Թ���§ 2 �������

�� �Ԥ��ë�����������§Ẻ��ԡ�ش � �ѹ˹�觤�� echo hiding ������ echo ��������§�������Ҵ�������ᵡ��ҧ�ѹ�Ẻ�������ö�դ�����亹����ԨԷ (�����繵�ͧ��� echo ������� �Ҩ��������µ�� �������ٻẺ���ᵡ��ҧ�ѹ�ͧ reverbertation ����) ������Ҵ�����������ҡ�ͷ���٤�������ö�¡ echo �͡�ҡ host
| Create Date : 25 �á�Ҥ� 2558 | | |
| Last Update : 25 �á�Ҥ� 2558 20:15:09 �. |
| Counter : 3309 Pageviews. |
| |
|
 |
|
|
|
���ͧ��蹡Ѻ pitch �ͧ complex tones
[��úѭ���������ͧ�����ѧ�֡��]
ANSI ����� "pitch ����ѡɳ��� (attribute) �ͧ����Ѻ������§㹾��������§����ö���§�ӴѺ����Ũҡ�����٧ pitch �������Ѻͧ���Сͺ�������ͧ���§��е�����Ӥѭ �����§��ҹ�� �ѧ�������Ѻ�����ѹ���§����ٻ���蹢ͧ��ǡ�е��"
�������������Ҿ���¡��ҹ�� ��� pitch ���ѡɳТͧ����Ѻ������§������ᵡ��ҧ�ͧ�ѹ����ѹ��Ѻ�ӹͧ�ŧ �ٴ�ա���ҧ˹����� ���§㴡������������Ѻ�������ǡѺ pitch (���� ���§㴡����������Ѻ��� pitch ��) ���§��� ������ö��������ҧ�ӹͧ�ŧ��������¹�ѵ�ҡ�ë�ӤҺ�ͧ���§ �������§��������Դ����Ѻ��� pitch ��ҡ�������§���价��繷ӹͧ�ŧ����� �� �س�������ö�����§����������٧���� 5 kHz ���͵�ӡ��� 25 Hz ����ҧ�ӹͧ�ŧ�� ������� ���§㹪�ǧ 25 Hz �֧ 5 kHz ��ҹ�鹷�������Դ pitch ��ǹ���§����դ����������͡��ǧ��� ��������Դ����Ѻ��� pitch (C.J. Plack, The Sense of Hearing)
�����������ⷹ G3 (196 Hz) ����Ѻ�������ԡ 4 ����á ���Ƿ��ͧ�ѧ pure G3, complex tones, �Ѻ complex tones ���ź fundamental frequency ��� ��Ҩ��Ѻ��� pitch ���ǡѹ (�����鵴���� G3 ������ǡѹ) ���¤س�Ҿ���§ (���� timbre) ��ҧ�ѹ
�ٻ��ҹ��ҧ�ʴ� waveform �Ѻ������ͧ���§ 3 ���§ ���§�á ���ش�� pure tone ���§����ͧ�Ѻ����� complex tones ���������§�� pitch ���ǡѹ ���з��������§�դ��������Űҹ���ǡѹ (���������Űҹ�繵�ǡ�˹� pitch)

�� MATLAB ����Ѻ���ͧ��� � �ѧ���� tonegen ���ҧ���� sine ��������� Ft Hz ��� Td �Թҷ� ��� sampling rate = Fs ������/�Թҷ�

ʤ�Ի�� pitch_of_complex_tone ������§ pure G3 ������� complex tones ����� f1+f2+f3+f4+f5 ���ǵ������ complex tones ���ź f1 ���ź f1+f2 ����ӴѺ ���Ф�Ի��� 2 �Թҷ� ��� sampling rate = 16 kHz

| Create Date : 25 �á�Ҥ� 2558 | | |
| Last Update : 25 �á�Ҥ� 2558 20:08:24 �. |
| Counter : 1696 Pageviews. |
| |
|
| |
|
|
|
Differential Evolution
[��úѭ���������ͧ�����ѧ�֡��]
�����ҵ�����ػ�ҡ Section ��� 2 �ͧ������ Differential Evolution - A Simple and Efficient Heuristic for Global Optimization over Continuous Spaces (Journal of Global Optimization 11: 341-359, 1997) �ͧ Rainer Storn �Ѻ Kenneth Price
Differential Evolution (DE) ���ա�Ԥ˹��㹵�С�� evolutionary algorithm ��觼����¹������һ�СǴ ICEO �����á (1996) ���ǻ��ʺ������� �͡����� evolutionary algorithm ������Ƿ���ش DE �� parallel direct search method ����� D-dimentional parameter vector �ӹǹ NP ����繻�Ъҡâͧ��� G
����������xi,G ����� i = 1, 2, ..., NP
���������ҧ vector �ش������¡����������ͺ������� parameter space ���Ͷ���繡óշ���� preliminary solution �������� ���Ҩ����ӵͺ�ѧ������繵�ǵ�駵��������ҧ����á�ҡ���������Ҫԡ��������§ູ�ҡ�ӵͺ��鹡�Ш��Ẻ������������� NP ���
�ҡ��� DE �����ҧ parameter vector �ش���� ���¡��� trial vector �ҡ��鹵 mutation �Ѻ crossover �������º��º trial vector �Ѻ target vector (��觡��ͻ�Ъҡ���� G �������) ���� greedy criterion ����Ǥ�� ������� cost function ��ӡ��ҡѹ ����鹡���������� G+1 ��鹵������¡��� selection ���Ƿӫ�� mutation, crossover, selection, mutation ... 仨��֧�ӹǹ��蹷���˹� ������һ�Ъҡõ�Ƿ��շ���ش�ҡ����ش�����繤ӵͺ
����������´�ͧ���Т�鹵
Mutation������ target vector xi,G ����� i = 1, 2, ..., NP �����ҧ mutant vector ����
����������ui,G+1 = xr1,G + F*(xr2,G - xr3,G)
����� index r1, r2, r3 ∈ {1, 2, ..., NP} �١�������������ӡѹ�������ӡѺ i (���Щй�� DE ��ͧ��û�Ъҡ����ҧ���� 4 ��), F �繨ӹǹ��ԧ����� ∈ [0,2] ������ҧ������ҧ mutant vector �ͧ�Ե��ʴ��ѧ�ٻ

Crossover��觷����Ҩ����Ѻ�ҡ��鹵����� D-dimentional trial vector ui,G+1 = (u1i,G+1, u2i,G+1, ..., uDi,G+1) ������ҧ�ҡ
����������uji,G+1 = vji,G+1 ��� randb(j) <= CR ���� j = rnbr(i)
����������uji,G+1 = xji,G �������������á
����� randb(j) ��� �������㹪�ǧ [0,1] ����繡������Ẻ uniform �ͧ parameter ��Ƿ�� j, CR ��� ��Ҥ���� crossover ∈ [0,1] �蹡ѹ, ��� rnbr(i) ��� ������� index ���˹�觨ҡ�� {1, 2, ..., D} �����繡���Ѻ��Сѹ��� ���վ������������ҧ����˹�觵�Ǣͧ ui,G+1 ����Ҩҡ mutant vector vi,G+1
��鹵 crossover �ʴ�������ҧ�óշ���վ��������� 7 ��Ǵѧ�ٻ
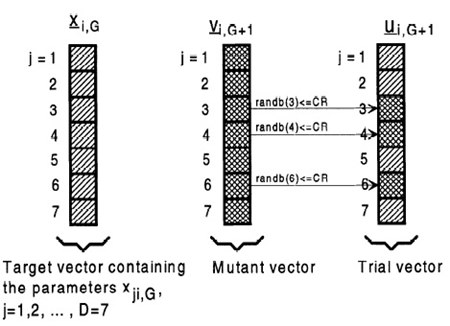
Selection�繡�����º��º trial vector ui,G+1 �Ѻ target vector xi,G ����è����� target vector ��蹶Ѵ� xi,G+1
� Section ��� 4 �ͧ�������ٴ�֧������͡ NP, F, CR ���դ��й���� NP �����ҧ 5*D �֧ 10*D �����, F = 0.5 �����, CR ����ͧ��� 0.1 ��� CR ����ҡ������� �ѧ��� �����á����������� CR = 0.9 ���� 0.1 �����ʹ���ҤӵͺẺ���� � ���������
| Create Date : 28 ���Ҥ� 2558 | | |
| Last Update : 28 ���Ҥ� 2558 16:53:54 �. |
| Counter : 2754 Pageviews. |
| |
|
| |
|
|
|
The Critical Band Concept & The Power Spectrum Model
[��úѭ���������ͧ�����ѧ�֡��]
��÷��ͧ�����ԡ�� 1940 �ͧ Fletcher �Ѵ�մ�����������Թ�ͧ�ѭ�ҳ���§�ٻ sine �繿ѧ���蹢ͧ bandwidth �ͧ band-pass noise ����� masker ��觡�÷��ͧ��������������ҧ�ͧ noise ����ç�������ͧ�ѭ�ҳ�ʹ� ��С�˹���� power density �ͧ noise �繤�Ҥ���� ���¤������ ���ѧ�ҹ����ͧ noise �����ҡ��� ����� bandwidth �ͧ�ѹ���ҧ��� ��÷��ͧ�١�ӫ�����¤��� ��м��Ѿ�������Ẻ���ǡѹ ����Ǥ�� 㹵�á �մ�����������Թ�ѭ�ҳ��������鹵�� bandwidth �ͧ noise ���������� ���֧�ش˹�� �ִ������ѧ����Ǩ����ѡɳ�Ẻ�Һ ������ bandwidth �ͧ noise �������������á��� �ѧ�ٻ

���¤������ ��ѧ�ҡ���������ҧ��ҹ�������ͧ noise ���ҧ�Թ���˹������� �մ�����������Թ�ѭ�ҳ���§�ٻ sine �ͧ��Ҩ�������� �֧��� noise �����§�ѧ���
Fletcher Ժ�»�ҡ���ó������ԧ�Ѻ����ʹͧ͢ Helmholtz ������ �к��Ѻ������§�ͧ��ҷӵ�������Ѻ����ѹ�� band-pass filters �ӹǹ˹�����§��͡ѹ�� bank �·����ҹ������� passbands �ͧ�����������е������ǹ��������ѹ ������¡�����������ҹ����� 'auditory filter' ��� Fletcher �Դ��� basilar membrane �繵鹵ͧ͢�����������ҹ�� ���е��˹觺��ҫ����������ù�еͺʹͧ��ͪ�ǧ�ͧ���������ӡѴ �ѧ��� �ش���ᵡ��ҧ�ѹ������ѹ��Ѻ����������դ�������ҧ��ҧ�ѹ
������Ҿ������е�Ǩ�Ѻ (�ѧ) �ѭ�ҳ����� noise �繩ҡ��ѧ ��Ҩ������������դ�������ҧ�����§�Ѻ�������ͧ�ѭ�ҳ ����ҿ�������ǹ��л��������ѭ�ҳ��ҹ ��СӨѴ�ѭ�ҳú�ǹ�������͡��ҹ��������ҹ�ͧ������� ��蹤�� �Ф������ͧ�ѭ�ҳú�ǹ����ҹ���������ҹ�鹷��з�����Դ masking effect
����� ��Ҩж����� �մ�����������Թ�ѭ�ҳ �١��˹��»���ҳ noise ����ҹ������� �ٴ�ա���ҧ��� �մ������ѧ���������ѹ��Ѻ SNR ������ҷ�ص�ͧ������� �ش�ͧ����ҹ����ҹ�����ѡ�ѹ㹹�� 'power spectrum model' �ͧ masking
��Ժ�¼��Ѿ��ҡ��÷��ͧ����� ��Һ��ҷ��������ҧ�ͧ noise �ѧ᤺���� bandwidth �ͧ������� ������� bandwidth �ͧ noise ����ҡѺ������� noise ������ҷ�ص�ͧ������� �����մ�����������Թ�ѭ�ҳ���§������� ����з�觤������ҧ�ͧ noise ���ҧ���� bandwidth �ͧ������� ��������������ҧ�ͧ�ѹ������ռ����õ�� SNR ������ҷ�ص�ͧ��������ա���� Fletcher ���¡ bandwith ���մ�����������Թ��ش������鹹����� 'critical bandwidth' (CB)
㹡����������š�÷��ͧ Fletcher �������ҹ��� �ٻ��ҧ�ͧ auditory filter ���ٻ��������������ҡ ����� critical band �����ѹ �ѡ����Ѻ����ҹ���������������������ҡ�ѹ���Ф�Ѻ (��駹������ͤ�������㹡�äӹdz �ѹ����ԧ Fletcher �������������� �����) Fletcher �͡��� �������ö�ӹdz��Ңͧ CB �ҧ����Ẻ����ҳ�� �¡���Ѵ�մ�����������Թ�ͧⷹ� broadband white noise �����Ѻ����ҹ��� (1) ����ҹ�������᤺ � ��������ͺ � ⷹ��觼�ҹ������������ҹ�鹷���觼ŵ�͡�� masking �ͧⷹ ��� (2) ��з�� noise �� mask ⷹ�ʹչ�� �ѵ����ǹ�ͧ���ѧ�ҹ�ͧⷹ (P) ��͡��ѧ�ҹ�ͧ noise �������� CB �繤�Ҥ���� K
��ҹ����͡���ѧ�ҹ�ͧ noise ��ٻ�ͧ���ѧ�ҹ���ҹ���������ҧ 1 Hz ���¡��� noise power density ��¹᷹�����ѭ�ѡɳ� N0 �������Ѻ white noise ��� N0 ����õ��������� �й�� ���ѧ�ҹ����ͧ noise �������� CB ���ҧ W Hz �֧��ҡѺ N0 x W
��Ҩ֧��¹����èҡ����ҹ��� 2 �ͧ Fletcher ����� P/(W x N0) = K ���� W = P/(K x N0) ��蹤�� ����������� N0 ����Ѵ��Ңͧ P �������ö����ҳ��� K �������������������ҧ�ͧ CB
Fletcher ����ҳ��� K = 1 �ѧ��� W = P/N0 (�ѡ���¡�ѹ��� critical ratio) ������ ��������Ҥ�һ���ҳ K �ͧ Fletcher ��������µç�ѡ ��÷��ͧ��ѧ � �͡��� K ����ҳ 0.4 ���ҧ�á��� ��� K �������Ѻ�Ըշ�����Ѵ�մ�����������Թ ����õ����������ҧ ������¤�� K �ͧ���Ф��������ҡѹ �й�� critical ratio �֧������Ǻ觪����١��ͧ�ѡ
��û���ҳ��� CB 㹻Ѩ�غѹ�ԧ����Ѻ���Ѿ��ҡ��÷��ͧ masking �����㹡�äӹdz ERB �ͧ auditory filter ��蹤�� ERB ����ö�������繡���Ѵ��Ңͧ CB ��Ф�Ѻ �������繡���¡�����ҧ����Ѵ��������Ѻ�ؤ��� ����ѴẺ����֧�����´��� ERB
�����: Brian C. J. Moore, An Introduction to the Psychology of Hearing (6th Ed), Emerald, 2012
| Create Date : 21 ���Ҥ� 2556 | | |
| Last Update : 21 �ѹ�Ҥ� 2556 3:09:26 �. |
| Counter : 1918 Pageviews. |
| |
|
| |
|
|
|
|

 �ҡ��ͤ�����ѧ����
�ҡ��ͤ�����ѧ���� ���Դ������͡ : 85 �� [
���Դ������͡ : 85 �� [